We’re going back in time, or is it forward?, as we continue learning about Google’s automation evolution, while Allen doesn’t like certain beers, Joe is a Zacker™, and Michael poorly assumes that UPSes work best when plugged in.
A cautionary, err, educational tale of automating MySQL for Ads and automating replica replacements.
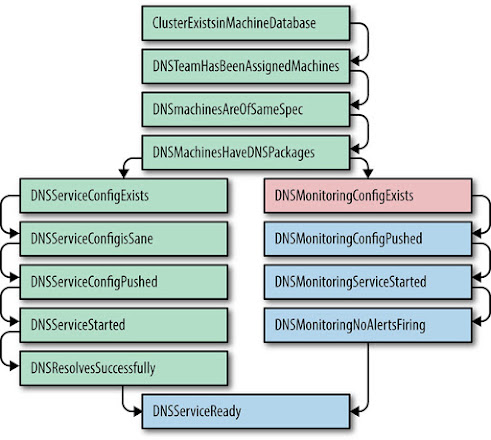
Migrating MySQL to Borg (Google Cluster Manager)
Large-scale cluster management at Google with Borg (research.google)
Desired goals of the project:
Eliminate machine/replica maintenance,
Ability to run multiple instances on same machine.
Came with additional complications – Borg task moving caused problems for master database servers.
Manual failovers took a long time.
Human involvement in the failovers would take longer than the required 30 seconds or less downtime.
Led to automating failover and the birth of MoB (MySQL on Borg).
Again, more problems because now application code needed to become much more failure tolerant.
After all this, mundane tasks dropped by 95%, and with that they were able to optimize and automate other things causing total operational costs to drop by 95% as well.
Automating Cluster Delivery
Story about a particular setup of Bigtable that didn’t use the first disk of a 12 disk cluster.
Some automation thought that if the first disk wasn’t being utilized, then none of the disks weren’t configured and were safe to be wiped.
Automation should be careful about implicit “safety” signals.
Cluster delivery automation depended on a lot of bespoke shell scripts which turned out to be problematic over time.
Detecting Inconsistencies with ProdTest
ProdTest contained chained “unit” tests that would figure out where problems began
Cluster automations required custom flags, which led to constant problems / misconfigurations.
Shell scripts became brittle over time.
Were all the services available and configured properly?
Were the packages and configurations consistent with other deployments?
Could configuration exceptions be verified?
For this, ProdTest was created.
Tests could be chained to other tests and failures in one would abort causing subsequent tests to not run.
The tests would show where something failed and with a detailed report of why.
If something new failed, they could be added as new tests to help quickly identify them in the future.
These tools gave visibility into what was causing problems with cluster deployments.
While the finding of things quicker was nice, that didn’t mean faster fixes. Dozens of teams with many shell scripts meant that fixing these things could be a problem.
The solution was to pair misconfigurations with automated fixes that were idempotent
This sounded good but in reality some fixes were flaky and not truly idempotent and would cause the state to be “off” and other tests would now start failing.
There was also too much latency between a failure, the fix, and another run.
Specializing
Automation processes can vary in one of three ways:
Competence,
Latency,
Relevance: the proportion of real world processes covered by automation.
They attempted to use “turnup” teams that would focus on automation tasks, i.e. teams of people in the same room. This would help get things done quicker.
This was short-lived.
Could have been over a thousand changes a day to running systems!
When the automation code wasn’t staying in sync with the code it was covering, that would cause even more problems. This is the real world. Underlying systems change quickly and if the automation handling those systems isn’t kept up, then more problems crop up.
This created some ugly side effects by relieving teams who ran services of the responsibility to maintain and run their automation code, which created ugly organizational incentives:
A team whose primary task is to speed up the current turnup has no incentive to reduce the technical debt of the service-owning team running the service in production later.
A team not running automation has no incentive to build systems that are easy to automate.
A product manager whose schedule is not affected by low-quality automation will always prioritize new features over simplicity and automation.
Turnups became inaccurate, high-latency, and incompetent.
They were saved by security by the removal of SSH approaches to more auditable / less-privileged approaches.
Service Oriented Cluster Turnup
Changed from writing shell scripts to RPC servers with fine-grained ACL (access control lists).
Service owners would then create / own the admin servers that would know how their services operated and when they were ready.
These RPC’s would send more RPC’s to admin server’s when their ready state was reached.
This resulted in low-latency, competent, and accurate processes.
Autonomous systems that need no human intervention”
Borg: Birth of the Warehouse-Scale Computer
In the early days, Google’s clusters were racks of machines with specific purposes.
Developers would log into machines to perform tasks, like delivering “golden” binaries.
As Google grew, so did the number and type of clusters. Eventually machines started getting a descriptor file so developers could act on types of machines.
Automation eventually evolved to storing the state of machines in a proper database, with sophisticated monitoring tools.
This automation was severely limited by being tied to physical machines with physical volumes, network connections, IP addresses, etc.
Borg let Google orchestrate at the resource level, allocating compute dynamically. Suddenly one physical computer could have multiple types of workloads running on it.
This let Google centralize it’s logic, making it easier to make systemic changes that improve efficiency, flexibility, and reliability.
This allowed Google to greatly scale it’s resources without scaling it’s labor.
Thousands of machines are born, die, and go into repair daily without any developer interaction.
They effectively turned a hardware problem into a software problem, which allowed them to take advantage of well known techniques and algorithms for scheduling processes.
This couldn’t have happened if the system wasn’t self-healing. Systems can’t grow past a certain point without this.
Reliability is the Fundamental Feature
Internal operations that automation relies on needs to be exposed to the people as well.
As systems become more and more automated, the ability for people to reason about the system deteriorates due to lack of involvement and practice.
They say that the above is true when systems are non-autonomous, i.e. the manual actions that were automated are assumed to be able to be done manually still, but doesn’t reflect the current reality.
While Google has to automate due to scale, there is still a benefit for software / systems that aren’t that at their scale and this is reliability. Reliability is the ultimate benefit to automation.
Automation also speeds processes up.
Best to start thinking about automation in the design phase as it’s difficult to retrofit.
Beware – Enabling Failure at Scale
Story about automation that wiped out almost all the machines on a CDN because when they re-ran the process to do a Diskerase, it found that there were no machines to wipe, but the automation then saw the “empty set” as meaning, wipe everything.
This caused the team to build in more sanity checks and some rate limiting!
Resources We Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Apple’s Self Service Repair now available (apple.com)
Tip of the Week
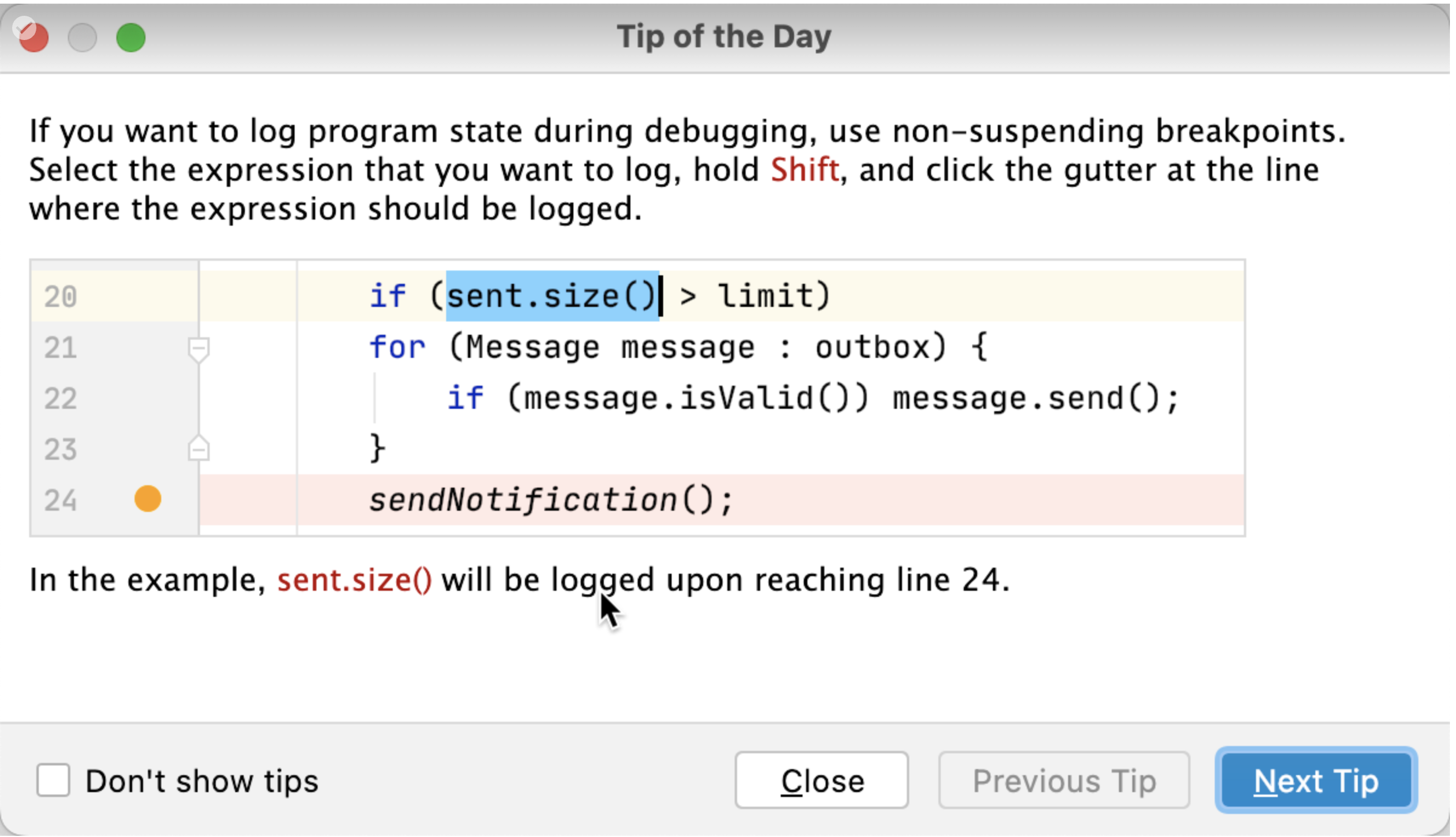
Jetbrains makes it easy to log values at debug time!
kubectl debug is a useful utility command that helps you debug issues. Here are a couple examples from the docs using kubectl debug (kubernetes.io)
Adding ephemeral debug containers to pods,
Copying existing pods and add additional containers,
Debugging pending pods,
Pods that immediately fail.
The Kubernetes docs feature a lot of nice tips for debugging (kubernetes.io)
Did you know that JetBrains makes it easy to add logging while you’re debugging? Just highlight the code you want to log the value of, then SHIFT-CLICK the gutter to set a logging point during debugging!
Want to copy a file out of an image, without running it? You can’t, however you can create a non-running container that will spin up a lite/idle container that will do the job. Just make sure to rm it when you’re done. Notice how helpful it was for later commands to name the container when it was created! Here’s an example workflow to copy out some.file. (docs.docker.com)