Picture, if you will, a nondescript office space, where time seems to stand still as programmers gather around a water cooler. Here, in the twilight of the workday, they exchange eerie tales of programming glitches, security breaches, and asynchronous calls. Welcome to the Programming Zone, where reality blurs and (silent) keystrokes echo in the depths of the unknown. Also, Allen is ready to boom, Outlaw is not happy about these category choices, and Joe takes the easy (but not longest) road.
Silent Key Tester for mechanical keyboards, you can specify a wide variety of switches (thockking.com)
Joe's preferences:
Durock Shrimp Silent T1
Tactile Gazzew Boba U4 Silent
Liner Kailh Silent Brown
Linear Lichicx Lucy Silent
Linear WS Wuque Studio Gray Silent
Tactile WS Wuque Studio
White Silent - Linear
Tactile Kailh Silent Pink
Linear Cherry MX Silent Red
Tip of the Week
Feeling nostalgic for the original GameBoy or GameBoy Color? GBStudio is a one-stop shop for making games, it's open-source and fully featured. You can do the art, music, and programming all in one tool and it's thoughtfully laid out and well-documented. Bonus…you games will work in GameBoy emulators AND you can even produce your own working physical copies. (If you don't want the high-level tools you can go old skool with "GBDK" too) (gbstudio.dev)
If you're going to do something, why not script it? If you're going to script it, save it for next time!
Dave's Garage is a YouTube channel that does deep dives into Windows internals, cool electronics projects, and everything in between! (YouTube)
This time we are missing the "ocks", but we hope you enjoy this off...ice topic chat about personalizing our workspaces. Also, Joe had to put a quarter in the jar, and Outlaw needs a cookie.
There's a story for Outlaw about this print: https://www.johndyerbaizley.com/product/four-horsemen-full-color-ap
Tip of the Week
If you have a car, you should consider getting a Mirror Dash Cam. It's a front and rear camera system that replaces your rearview mirror with a touchscreen. Impress all your friends with your recording, zoom, night vision, parking assistance, GPS, and 24/7 recording and monitoring. (Amazon)
Be careful about exercising after you give blood, else you might end up needing it back! (redcrossblood.org )
We are mixing it up on you again, no Outlaw this week, but we can offer you some talk of exotic databases. Also, Joe pronounces everything correctly and Allen leaves you with a riddle.
Store multiple values to a particular record's attribute
Some RDBMS's can do this as well, BUT it's typically an exception to the rule when you'd store an array on an attribute
In a MultiValue DBMS - that's how you SHOULD do it
Part of the reason it's done this way is these database systems are not optimized for JOINS
Looked at the Adabas and UniData sites - the primary selling points seem to be rapid application development / ease of learning and getting up to speed as well as data modeling that closely mirrors your application data structures
Provides the ability to efficiently store, modify, and query spatial data - data that appears in a geometrical space (maps, polygons, etc)
Generally have custom data types for storing the spatial data
Indices that allow for quick retrieval of spatial data about other spatial data
Also allow for performing spatial-specific operations on data, such as computing distances, merging or intersecting objects or even calculating areas
Geospatial data is a subset of spatial data - they represent places / spatial data on the Earth's surface
Spatio-temporal data is another variation - spatial data combined with timestamps
PostGIS - basically a plugin for PostgreSQL that allows for storing of spatial data
Additionally supports raster data - data for things like weather and elevation
If you want to learn how to use it and understand the data and what's stored (postgis.net)
Spatial data types are: point, line, polygon, and more…basically shapes
Rather than using b-tree indexes for sorting data for fast retrieval, spatial indexes that are bounding boxes - rectangles that identify what is contained within them
Typically accomplished with R-Tree and Quadtree implementations
RedFin - a real estate competitor to realtor.com and others, uses PostgreSQL / PostGIS
Quite a bit of software that supports OpenGIS so may be a good place to start if you're interested in storing/querying spatial data
Event Stores
Popular: 178. EventStoreDB, 336. IBM DB2 Event Store, 338. NEventStore
Used for implementing the concept of Event Sourcing
Event Sourcing - an application/data store where the current state of an object is obtained by "replaying" all the events that got it to its current state
This contrasts with RDBMS's in that relational typically store the current state of an object - historical state CAN be stored, but that's an implementation detail that has to be implemented, such as temporal tables in SQL Server or "history tables"
Only support adding new events and querying the order of events
Not allowed to update or delete an event
For performance reasons, many Event Store databases support snapshots for holding materialized states at points in time
Features: guaranteed writes, concurrency model, granulated stream and stream APIs
Many client interfaces: .NET, Java, Go, Node, Rust, and Python
Runs on just about all OSes - Windows, Mac, Linux
Highly available - can run in a cluster
Optimistic concurrency checks that will return an error if a check fails
"Projections" allow you to generate new events based off "interesting" occurrences in your existing data
For example. You are looking for how many Twitter users said "happy" within 5 minutes of the word "foo coffee shop" and within 2 minutes of saying "London".
Highly performant - 15k writes and 50k reads per second
If your internet connection is good, but your cell phone service is bad then you might want to consider Ooma. Ooma sells devices that plug into your network or connect wireless and provide a phone number, and a phone jack so you can hook up an an old school home telephone. We've using it for about a week now with no problems and it's been a breeze to set up. The devices range from $99 to $129 and there's a monthly "premier" plan you can buy with nifty features like a secondary phone line, advanced call blocking, and call forwarding. (ooma.com)
Why use "git reset --hard" when you can "git stash -u" instead? Reset is destructive, but stashing keeps your changes just in case you need them. Because sometimes, your "sometimes" is now!
This episode we are talking about keeping the internet interesting and making cool things by looking at PagedOut and Itch.io. Also, Allen won't ever mark you down, Outlaw won't ever give you up, and Joe took a note to say something about Barbie here but he can't remember what it was.
If you subscribe to Audible, don't forget that they have a lot of "free" content available, such as dramatic space operas and the "Great Courses" For example. "How to Listen to and Understand Great Music" is similar to a "Music Appreciation Course" you might take at uni. The author works through history, talking about the evolution of music and culture. It's 36 hours, and that's just ONE of the music courses available to you for "free" (once you subscribe) (audible.com)
Visualize Git is an excellent tool for seeing what really happens when you run git commands (git-school.github.io)
It's easy to work with checkboxes in Markdown and Obsidian, it's just - [ ] Don't forget the dash or spaces!
Did you know there is a Visual Studio Code plugin for converting Markdown to Jira markup syntax? (Code)
Apple, Google, and the major password manager vendors have ways to set up emergency contacts. It's very important that you have this setup for yourself, and your loved ones. When you need it, you really need it. (google.com)
This episode we are talking about the future of tech with the Gartner Top Strategic Technology Trends 2024. Also, Allen is looking into the crystal ball, Joe is getting lo, and Outlaw is getting into curling.
Make sure you read up on your next MacBook pro, if you want to maximize the performance then you are going to need to pay for it!
Reminder: Don't install packages from the internet in your CICD pipeline!
You can find links to leave us reviews on the website (/reviews)
Gartner Top Strategic Technology Trends 2024
No surprise, AI is a big topic - it looks like Gartner is suggesting the technologies and processes companies must follow to be successful using and incorporating AI In this overview, Gartner has grouped these technologies into three different sections
Protect Your Investment
Rise of the Builders
Deliver the Value
Protect Your Investment
Be deliberate
Ensure that you've secured appropriate rights for deploying AI driven solutions
AI Trism - AI Trust, Risk and Security Management
AI model governance
Trustworthiness
Fairness
Reliability
Robustness
Transparency
Data protection
Gartner Prediction - By 2026, companies that incorporate AI Trism controls will improve decision-making by reducing faulty and invalid information by 80%
Why is AI Trism Trending?
Largely, those who have AI Trism controls in place move more to production, achieve more value, and have higher precision in their modeling
Enhance bias control decisions
Model explainability
How to get started with AI Trism?
Set up a task force to manage the efforts
Work across the organization to share tools and best practices
Define acceptable use policies and set up a system to review and approve access to AI models
Continuous Threat Exposure Management - CTEM
Systemic approach to continuously adjust cybersecurity priorities
Gartner prediction - By 2026, companies invested in CTEM will reduce security breaches by 2/3 (statista.com)
Aligns exposure assessment with specific projects or critical threat vectors (fortinet.com)
Both patchable and unpatchable exposures will be addressed
Business can test the effectiveness of their security controls against the attacker's view
"Expected outcomes from tactical and technical response are shifted to evidence-based security optimizations supported by improved cross-team mobilization."
How to get started?
Integrate CTEM with risk awareness and management programs
Improve the prioritization of finding vulnerabilities through validation techniques
"security validation is a process or a technology that validates assumptions made about the actual security posture of a given environment, structure, or infrastructure"
Sustainable Technology Framework
Solutions for enabling social, environmental and governance outcomes for long term ecological balance and human rights
Gartner prediction - by 2027, 25% of CIO's will have compensation that's linked to their sustainable technology impact
Why trending?
Environmental technologies help deal with risks in the natural world
Social technologies help with human rights
Governance technologies strengthen business conduct
Sustainable technologies provide insights for improving overall performance
How to get started?
Select technologies that help drive sustainability
Have an ethics board involved when developing the roadmap (gartner.com)
Use the Gartner "Hype Cycle for Sustainability 2023" - helps identify well-established vs leading-edge technologies for enterprise sustainability (gartner.com)
Resources We Like
"Where Online Returns Really End Up And What Amazon Is Doing About It" (YouTube)
Tip of the Week
Lofi Girl is a youtube channel that plays lo-fi hip hop beats, with a relaxing minimalistic animations. The people behind Lo-Fi Girl also released a new channel featuring a Synthwave (80's influenced mid-tempo electro music) Boy. Same type thing, but Synthwave music. (youtube.com)
If you are interested in streaming technologies and/or Apache Pinot then you should check out the Real-Time Analytics podcast by Tim Berglund (rta.buzzsprout.com)
Are you having runtime issues with your Docker container? Why not run it, and poke around? (curl.se)
The call for speakers is open till December 15th for Orlando Code Camp
Sony announces a9 III: World's first full-frame global shutter camera (dpreview.com)
Technology Adoption Roadmap for Midsize Enterprises 2022-2024
Gartner Report Technology Adoption Roadmap for Midsize Enterprises 2022-2024More than 400 MSE's interviewed (gartner.com)
53 technologies were mapped to adoption stage (pilot, deployed 2022, deploy in 2023), value and risk
Value was determined by looking at the following factors
Increasing cost efficiency
Improving speed and agility
Enabling resilience
Enhancing employee productivity
Deployment risk
Cybersecurity risks
Implementation cost
Talent availability
Vendor supply chain disruption
Geopolitical risks
Key Takeaways
Cybersecurity
Investments prioritized in (M)anaged (D)etection and (R)response - this to deal with the growing threat of digital risks including things like ransomware
(S)ecure (A)ccess (S)ervice (E)dge is gaining traction for moving away from hardware based security solutions to cloud based security services
(Z)ero (T)rust (N)etwork (A)ccess is being evaluated to replace VPNs
Future work environments
Investments are being made in hybrid and remote work environments over collaboration and productivity tools
Deployment of cloud security tools being prioritized to enable more security hybrid and remote work environments
DIstributed cloud systems and cloud storage are also being prioritized
(C)itizen (A)utomation and (D)evelopment (P)latforms are also being investigated to allow business users to leverage low-code services to help speed business decisions
NLP - Natural Language Processing appears to be something that businesses want to adopt but are falling behind on plans to deploy due to some challenges
Accuracy in language translation
Even though NLP has come a LONG way in the past couple years, the human language is still a very challenging problem to solve
Investing in AI and Data Science and Machine Learning to help observe infrastructure across on-prem, cloud and edge computing
Comes with high deployment risks but still very highly adopted
Investments in 5g for larger demand of networking
Investments in API management PaaS
One of the problems here is talent shortages in this area of expertise (azure.microsoft.com)
Some of the high-value low-risk items being piloted
Cloud Data Warehousing
High-value low-risk items deployed or being deployed
Security Orchestration Automation and Response
Digital Experience Monitoring
Robotic Process Automation
Virtual Machine Backup and Recovery
Integration Platform as a Service
SD-WAN (software-defined WAN)
Network Detection and Response
High-value high risk
Zero Trust Network Access
Artificial Intelligence IT Operations - AIOps
Cloud Application Discovery
Hybrid Cloud Computing
AI Cloud Services
Cloud Managed Networks - CMNs
Who have you partnered with?
Email Addresses
Registrar
Cloud Storage (Dropbox, OneDrive, iCloud, etc)
Backups (Do you still need them!?)
Contacts
Passwords
Photos
Tip of the Week
Have a presentation to do? Slidev is a VueJs and markdown-based way to create slides. Because it's web based you can do cool interactive type stuff, and it's portable. Bonus: recording and camera view support built in. Thanks Dave! (sli.dev)
There are a lot of great resources for Kubernetes on the official Kubernetes Certifications and Training page (kubernetes.io)
Notes in iOS are pretty good now! Did you know you can use it for inline images, videos, along with note taking…. (youtube.com)
Use Docker? Check out dive, it's a tool for exploring a docker image, layer contents, and discovering ways to shrink the size of your Docker/OCI image. (github.com)
We've got a smorgasbord of delights for you this week, ranging from mechanical switches to the cloud and beyond. Also, Michael's cosplaying as Megaman, Joe learns the difference between Clicks and Clacks, and Allen takes no prisoners.
Leave us a review if you have a chance! (/reviews)
The Show
Why are mechanical keyboards so popular with programmers?
Is it the sound? Is it the feel? What are silent switches? Are they missing the point?
You can buy key switches for good prices (drop.com)
Cloud Costs Every Programmer should know (vantage.sh) (Thanks Mikerg!)
List of static analysis tools, so you can get with the times! (GitHub) (Thanks Mikerg!)
From itsmatt:
"I’d love a breakdown of what each of you think are your key differences in philosophies or approaches to software development. Could be from arguments or debates on older episodes, whether on coding, leadership, startups, AI, whatever - just curious about how best to tell everyone’s voices apart based on what they’re saying. I know one of you is Jay Z (JZ?), but slow to pick up on which host is which based on accents alone."
How do you center a div? Within a div? With right-align text? What about centering 3 divs? What if you want to space them out evenly? If you've been away from CSS for a while, you may be a bit rusty on the best ways to do this. Not sure if it's "the best" but an easy solution to these problems is to use Flexbox, and lucky for you there is a fun little game designed to teach you how to use it. (flexboxfroggy.com)
Drop.com is a website focused on computer gear, headphones, keyboards, desk accessories etc. It's got a lot of cool stuff! (drop.com)
Have you ever accidentally deleted a file? Recovering files in git doesn't have to be hard with the "restore" command (rewind.com)
Have trouble with your hands and want to limber up? Also doubles as a cool retro Capcom Halloween costume. It's a LifePro Hand Massager! (amazon)
In this episode, we are talking all about GitHub Actions. What are they, and why should you consider learning more about them? Also, Allen terminates the terminators, Outlaw remembers the good ol' days, and Joe tries his hand at sales.
GitHub Actions is a CI/CD platform launched in 2018 that lets you define and automate workflows
It's well integrated into Github.com and fits nicely with git paradigms - repository, branches, tags, pull requests, hashes, immutability (episode 195)
The workflows can run on GitHub-hosted virtual machines, or on your own servers
GitHub Actions are free for standard Github runners in public repositories and self-hosted runners, private repositories get a certain amount of "free" minutes and any overages are controlled by your spending limits
2000 minutes and 500MB for free, 3000 minutes and 1Gb for Pro, etc (docs.github.com)
Examples of things you can do
Automate builds and releases whenever a branch is changed
Run tests or linters automatically on pull requests
Automatically create or assign Issues, or labels to issues
Publish changes to your gh-pages, wiki, releases,
Check out the "Actions" tab on any github repository to check if a repository has anything setup (github.com)
The "Actions" in GitHub Actions refers to the most atomic action that takes place - and we'll get there, but let us start from the top
Workflows
Workflow is the highest level concept, you see any workflows that a repository has set up (learn.microsoft.com)
A workflow is triggered by an event: push, pull request, issue being opened, manual action, api call, scheduled event, etc (learn.microsoft.com)
TypeScript examples:
CI - Runs linting, checking, builds, and publishes changes for all supported versions of Node on pull request or push to main or release-* branches
Close Issues - Looks for stale issues and closes them with a message (using gh!)
Code Scanning - Runs CodeQL checks on pull request, push, and on a weekly schedule
Publish Nightly - Publishes the last set of successful builds every night
Workflows can call other workflows in your repository, or in a repository you have access to
Special note about calling other workflows - when embedding other workflows you can specify a specific version with either a tag or a commit # to make sure you're running exactly what you expect
In the UI you'll see a filterable history of workflow runs on the right
The workflow is associated with a yaml file located in ./github/workflows
Clicking on a workflow in the left will show you a history of that workflow and a link to that file (cli.github.com)
Jobs
Workflows are made up of jobs, which are associated with a "runner" (machine) (cli.github.com)
Jobs are mainly just a container for "Steps" which are up next, but the important bit is that they are associated with a machine (virtual or you can provide your own either via network or container)
Jobs can also be dependent on other jobs in the workflow - Github will figure out how to run things in the required order and parallelize anything it can
You're minutes are counted by machine time, so if you have 2 jobs that run in parallel that each take 5 minutes…you're getting "charged" for 10 minutes
Steps
Jobs are a group of steps that are executed in order on the same runner
Data can easily be shared between steps by echoing output, setting environment variables or mutating files
An action is a custom application written for the GitHub Actions platform
GitHub provides a lot of actions and other 3p (verified or not) providers do as well in the "Marketplace", you can use other people's actions (as long as they don't delete it!), and you can write your own
Github Checkout - provides options for things like repository, fetch-depth, lfs (github.com)
Setup .NET Core SDK - Sets up a .NET CLI environment for doing dotnet builds (github.com)
Upload Artifact - Uploads data for sharing between jobs (90-day retention by default) (github.com)
Docker Build Push - Has support for building a Docker container and pushing it to a repository (Note: ghrc is a valid repository and even free tiers have some free storage) (github.com)
Custom Examples
"run" command lets you run shell commands (docker builds, curl, echo, etc)
We glossed over a lot of the details about how things work - such as various contexts where data is available and how it's shared, how inputs and outputs are handled…just know that it's there! (docs.github.com)
You grant job permissions, default is content-read-only but you must give fine-grained permissions to the jobs you run - write content, gh-pages, repository, issues, packages, etc
There is a section under settings for setting secrets (unretrievable and masked in output) and variables for your jobs. You have to explicitly share secrets with other jobs you call
There is support for "expressions" which are common programming constructions such as conditionals and string helper functions you can run to save you some scripting (docs.github.com)
Verdict
Pros:
GitHub Actions is amazing because it's built around git!
Great features comparable (or much better) than other CI/CD providers
Great integration with a popular tool you might already be using (docs.github.com)
Works well w/ the concepts of Git By default, workflows cannot use actions from GitHub.com and GitHub Marketplace. You can restrict your developers to using actions that are stored on your GitHub Enterprise Server instance, which includes most official GitHub-authored actions, as well as any actions your developers create. Alternatively, to allow your developers to benefit from the full ecosystem of actions built by industry leaders and the open-source community, you can configure access to other actions from GitHub.com.
Great free tier
Great documentation https://docs.github.com/en/actions/using-containerized-services/creating-postgresql-service-containers
Hosted/Enterprise version
Cons:
Working via commits can get ugly…make your changes in a branch and rebase when you're done!
Next Steps
If you are interested in getting started with DevOps, or just learning a bit more about it, then this is a great way to go! It's a great investment in your skillset as a developer in any case.
Examples:
Build your project on every pull request or push to trunk
Run your tests, output the results from a test coverage tool
Run a linter or static analysis tool
Post to X, Update LinkedIn whenever you create a new release
There is a GitHub Actions plugin for VSCode that provides a similar UI to the website. This is much easier than trying to make all your changes in Github.com or bouncing between VSCode and the website to see how your changes worked. It also offers some integrated documentation and code completion! It's definitely my preferred way of working with actions. (marketplace.visualstudio.com)
Did you know that you can cancel terminating a terminating persistent volume in Kubernetes? Hopefully you never need to, but you can do it! (github.com)
How are the Framework Wars going? Check out Google trends for one point of view. (trends.google.com)
Rebasing is great, don't be afraid of it! A nice way to get started is to rebase while you are pulling to keep your commits on top. git pull origin main --rebase=i
There's a Dockerfile Linter written in Haskell that will help you keep your Docker files in great shape. (docker.com)
Allen made the video on generating a baseball lineup application just by chatting with ChatGPT (youtube)
https://youtu.be/i6jSeLvoFmM
Allen made the video on generating a baseball lineup application just by chatting with ChatGPT
What is OpenTelemetry?
An incubating project on the CNCF - Cloud Native Computing Foundation (cncf.io)
What does incubating mean?
Projects used in production by a small number of users with a good pool of contributors
Basically you shouldn't be left out to dry here
So what is Open Telemetry? A collection of APIs, SDKs and Tools that's used to instrument, generate, collect and export telemetry data
This helps you analyze your software's performance and behavior
It's available across multiple languages and frameworks
It's all about Observability
Understanding a system "from the outside"
Doesn't require you to understand the inner workings of the system
The goal is to be able to troubleshoot difficult problems and answer the "Why is this happening?" Question
To answer those questions, the application must be properly "Instrumented"
This means the application must emit signals like metrics, traces, and logs
The application is properly instrumented when you can completely troubleshoot an issue with the instrumentation available
That is the job of OpenTelemetry - to be the mechanism to instrument applications so they become observable
List of vendors that support OpenTelemetry: https://opentelemetry.io/ecosystem/vendors/
Reliability and Metrics
Telemetry - refers to the data emitted from a system about its behavior in the form of metrics, traces and logs
Reliability - is the system behaving the way it's supposed to? Not just, is it up and running, but also is it doing what it is expected to do
Metrics - numeric aggregations over a period of time about your application or infrastructure
CPU Utilization
Application error rates
Number of requests per second
SLI - Service Level Indicator - a measurement of a service's behavior - this should be in the perspective of a user / customer
Example - how fast a webpage loads
SLO - Service Level Objective - the means of communicating reliability to an organization or team
Accomplished by attaching SLI's to business value
Distributed Tracing
To truly understand what distributed tracing is, there's a few parts we have to put together first
Logs - a timestamped message emitted by applications
Different than a trace - a trace is associated with a request or a transaction
Heavily used in all applications to help people observe the behavior of a system
Unfortunately, as you probably know, they aren't completely helpful in understanding the full context of the message - for instance, where was that particular code called from?
Logs become much more useful when they become part of a span or when they are correlated with a trace and a span
Span - represents a unit of work or operation
Tracks the operations that a request makes - meaning it helps to paint a picture of what all happened during the "span" of that request/operation
Contains a name, time-related data, structured log messages, and other metadata/attributes to provide information about that operation it's tracking
Some example metadata/attributes are: http.method=GET, http.target=/urlpath, http.server_name=codingblocks.net
Distributed trace is also known simply as a trace - record the paths taken for a user or system request as it passes through various services in a distributed, multi-service architecture, like micro-services or serverless applications (AWS Lambdas, Azure Functions, etc)
Tracing is ESSENTIAL for distributed systems because of the non-deterministic nature of the application or the fact that many things are incredibly difficult to reproduce in a local environment
Tracing makes it easier to understand and troubleshoot problems because they break down what happens in a request as it flows through the distributed system
A trace is made of one or more spans
The first span is the "root span" - this will represent a request from start to finish
The child spans will just add more context to what happened during different steps of the request
Some observability backends will visualize traces as waterfall diagrams where the root span is at the top and branching steps show as separate chains below - diagram linked below (opentelemetry.io)
Attention Windows users, did you know you can hold the control key to prevent the tasks from moving around in the TaskManager. It makes it much easier to shut down those misbehaving key loggers! (verge.com)
Does your JetBrains IDE feel sluggish? You can adjust the heap space to give it more juice! (blogs.jetbrains.com)
Beware of string interpolation in logging statements in Kotlin, you can end up performing the interpolation even if you're not configured to output the statement types! IntelliJ will show you some squiggles to warn you. Use string templates instead. Also, Kotlin has "use" statements to avoid unnecessary processing, and only executes when it's necessary. (discuss.kotlinlang.org)
Thanks to Tom for the tip on tldr pages, they are a community effort to simplify the beloved man pages with practical examples. (tldr.sh)
Looking for some new coding music? Check out these albums from popular guitar heroes!
In this episode, we're talking about the history of "man" pages, console apps, team leadership, and Artificial Intelligence liability. Also, Allen's downloading the internet, Outlaw has fallen in love with the sound of a morrvair, and Joe says TUI like two hundred times as if it were a real word.
DevFest Florida is a community-run one-day conference aimed to bring technologists, developers, students, tech companies, and speakers together in one location to learn, discuss and experiment with technology. (devfestfl.org)
What are (were?) man pages?
"man" is a command-line "pager" similar to "more" or "less" that was designed specifically to display documentation - ahem, "manuals"
"man" pages would show you documentation for many apps in a (mostly) consistent manner that was available offline
Do people still use them?
People would print these out in the 70's and beyond!
Meta has been making serious strides in AI with LLAMA and...it's open source! Does that make them any more or less liable for the information? Does "publically available information" change things
Resources we like
Software Engineering at Google: Lessons Learned from Programming Over Time (amazon)
Want to learn something new while also making your life easier? Why not try writing a TUI!? Here's an article that will kindly introduce you to terminal user interfaces, libraries like "Clap", "TUI", and "Crossterm" that people are using to write them, and…you can get some XP with Rust while you're at it! (blog.logrocket.com)
Are you looking to upgrade your Kubernetes cluster? Check for API problems first!
Are you a browser tab fiend? Did you know you can reload all your tabs simultaneously with a simple shortcut? (groups.google.com)
No more nasty wiring jobs, get yourself to the hardware store website and pick up some wire and splicing connectors. Keep things nice, tidy, and organized. (wago.com)
Matt’s Off-road recovery channel is amazing if you're into cars or... beautiful-sounding things.
Are you tired of manually correlating logs and events? No more! Check out the Open Telemetry project for your distributed tracing and analytics needs! (opentelemetry.io)
In this episode, we're talking about lessons learned and the lessons we still need to learn. Also, Michael shares some anti-monetization strategies, Allen wins by default, and Joe keeps it real 59/60 days a year!
Unit Testing Principles, Practices, and Patterns: Effective testing styles, patterns, and reliable automation for unit testing, mocking, and integration testing with examples in C# (Amazon)
In this sequence of sound, we compute Joe's unexpected pleasure in commercial-viewing algorithms, Michael's intricate process of slicing up the pizza, and Allen's persistent request for more cheese data augmentation. Will you engage in this data streaming session?
MusicLM lets you create music from descriptive text, similar to Dalle-2. The output is a little strange, but could still potentially be really useful and inspiring with a little bit of effort. It's in private beta now, as part of the "AI Test Kitchen" but you can sign up to join the waitlist today.
In this episode we talk about several things that have been on our mind. We find that Joe has been taken over by AI's, Michael now understands our love of Kotlin, and Allen wants to know how to escape supporting code you wrote forever.
We're doing a water cooler talk today. Also, Allen can tell you how not to leak secrets, Michael knows how to work a spreadsheet, and Joe has been replaced by an AGI.
Have any experience with Twilio? It's work! (twilio.com)
Resources we like
docker init is a tool (in beta) built into the latest Docker Desktop that you can use to get a leg up on your next project. It makes it easy to create docker files with best practices, as well as a docker-compose file to get you up and running. (docker.com)
screen is an open-source powerful terminal multiplexer that allows users to create, manage, and switch between multiple terminal sessions, enabling seamless multitasking and persistent remote connections in a single window.
The VIVO Universal Treadmill Desk Riser is an adjustable, ergonomic workspace solution designed to fit most treadmills, allowing users to seamlessly combine their work and exercise routines for a healthy, productive lifestyle. (amazon.com)
The LifeSpan Fitness Under Desk Walking Treadmill is a compact, low-profile treadmill designed to fit under standing desks, enabling remote workers to maintain an active lifestyle by seamlessly integrating walking or light jogging into their daily work routine, promoting better health and increased productivity. (amazon.com)
Kubernetes Network Policies are a set of rules that define how pods within a cluster can communicate with each other and with external resources, allowing administrators to enforce fine-grained access control and enhance the security of their containerized applications. (kubernetes.io)
What are lost updates, and what can we do about them? Maybe we don't do anything and accept the write skew? Also, Allen has sharp ears, Outlaw's gort blah spotterfiles, and Joe is just thinking about breakfast.
Last episode we talked about weak isolation, committed reads, and snapshot isolation
There is one major problem we didn't discuss called "The Lost Update Problem"
Consider a read-modify-write transaction, now imagine two of them happening at the same time
Even with snapshot isolation, it's possible that read can happen for transaction A before B, but the write for A happens first
Incrementing/Decrementing values (counters, bank accounts)
Updating complex values (JSON for example)
CMS updates that send the full page as an update
Solutions:
Atomic Writes - Some databases support atomic updates that effectively combine the read and write
Cursor Stability - locking the read object until the update is performed
Single Threading - Force all atomic operations to happen serially through a single thread
Explicit Locking
The application can be responsible for explicitly locking objects, placing responsibility in the devs hands
This makes sense in certain situations - imagine a multiplayer game where multiple players can move a shared object. It's not enough to lock the data and then apply both updates in order since the shared game world can react. (ie: showing that the item is in use)
Detecting Lost Updates
Locks can be tricky, what if we reused the snapshot mechanism we discussed before?
We're already keeping a record of the last transactionId to modify our data, and we know our current transactionId. What if we just failed any updates where our current transaction id was less than the transactionId of the last write to our data?
This allows for naive application code, but also gives you fewer options…retry or give up
Note: MySQL's InnoDB's Repeatable Read feature does not support this, so some argue it doesn't qualify as snapshot isolation
What if you didn't have transactions?
If you didn't have transactions, let alone a snapshot number, you could get similar behavior by doing a compare-and-set
Example: update account set balance = 10 where balance = 9 and id = ABC
This works best in simple databases that support atomic updates, but not great with snapshot isolation
Note: it's up to the application code to check that updates were successful - Updating 0 records is not an error
Conflict resolution and replication
We haven't talked much about replicas lately, how do we handle lost updates when we have multiple copies of data on multiple nodes?
Compare-and-Set strategies and locking strategies assume a single up-to-date copy of the data….uh oh
The options are limited here, so the strategy is to accept the writes and have an application process to decide what to do
Merge: Some operations, like incrementing a counter, can be safely merged. Riak has special datatypes for these
Last Write Wins: This is a common solution. It's simple but inaccurate. Also the most common solution.
Write Skew and Phantoms
Write skew - when a race condition occurs that allows writes to different records to take place at the same time that violates a state constraint
The example given in the book is the on-call doctor rotation
If one record had been modified after another record's transaction had been completed, the race condition would not have taken place
write-skew is a generalization of the lost update problem
Preventing write-skew
Atomic single-object locks won't work because there's more than one object being updated
Snapshot isolation also doesn't work in many implementations - SQL Server, PostgreSQL, Oracle, and MySQL won't prevent write skew
Requires true serializable isolation
Most databases don't allow you to create constraints on multiple objects but you may be able to work around this using triggers or materialized views as your constraint
They mention if you can't use serializable isolation, your next best option may be to lock the rows for an update in a transaction meaning nothing else can access them while the transaction is open
Phantoms causing write skew
Pattern
The query for some business requirement - ie there's more than one doctor on call
The application decides what to do with the results from the query
If the application decides to go forward with the change, then an INSERT, UPDATE, or DELETE operation will occur that would change the outcome of the previous step's Application decision
They mention the steps could occur in different orders, for instance, you could do the write operation first and then check to make sure it didn't violate the business constraint
In the case of checking for records that meet some condition, you could do a SELECT FOR UPDATE and lock those rows
In the case that you're querying for a condition by checking on records to exist, if they don't exist there's nothing to lock, so the SELECT FOR UPDATE won't work and you get a phantom write - a write in one transaction changes the search result of a query in another transaction
Snapshot isolation avoids phantoms in read-only queries, but can't stop them in read-write transactions
Materializing conflicts
The problem we mentioned with phantom is there'd no record/object to lock because it doesn't exist
What if you were to have a set of records that could be used for locking to alleviate the phantom writes?
Create records for every possible combination of conflicting events and only use those to lock when doing a write
"materializing conflicts" because you're taking the phantom writes and turning them into lock records that will prevent those conflicts
This can be difficult and prone to errors trying to create all the combinations of locks AND this is a nasty leakage of your storage into your application
Docker's Buildkit is their backend builder that replaces the "legacy" builder by adding new non-backward compatible functionality. The way you enable buildkit is a little awkward, either passing flags or setting variables as well as enabling the features per Dockerfile, but it's worth it! One of the cool features is the "mount" flag that you can pass as part of a RUN statement to bring in files that are not persisted past that layer. This is great for efficiency and security. The "cache" type is great for utilizing Docker's cache to save time in future builds. The "bind" type is nice for mounting files you only need temporarily. like source code in for a compiled language. The "secret" is great for temporarily bringing in environment variables without persisting them. Type "ssh" is similar to "secret", but for sharing ssh keys. Finally "tmpfs" is similar to swap memory, using an in-memory file system that's nice for temporarily storing data in primary memory as a file that doesn't need to be persisted. (github.com)
Did you know Google has a Google Cloud Architecture diagramming tool? It's free and easy to use so give it a shot! (cloud.google.com)
ChatGTP has an app for slack. It's designed to deliver instant conversation summaries, research tools, and writing assistance. Is this the end of scrolling through hundreds of messages to catch up on whatever is happening? /chatgpt summarize (salesforce.com)
Have you heard about ephemeral containers? It's a convenient way to spin up temporary containers that let you inspect files in a pod and do other debugging activities. Great for, well, debugging! (kubernetes.io)
There's this thing called ChatGPT you may have heard of. Is it the end for all software developers? Have we reached the epitome of mankind? Also, should you write your own or find a FOSS solution? That and much more as Allen gets redemption, Joe has a beautiful monologue, and Outlaw debates a monitor that is a thumb size larger than his current setup.
This probably isn't the first time and it won't be the last we ask the question - should you write your own version of something if there's a good Free Open Source Software alternative out there?
Typed vs Untyped Languages
Another topic that we've touched on over the years - which is better and why?
Any considerations when working with teams of developers?
What are the pros and cons of each?
Cloud Pricing
If you're spending a good amount of money in the cloud, you should probably talk to a sales rep for your given cloud and try to negotiate rates. You may be surprised how much you can save. And...you never know until you ask!
Outlaw has the Itch to get a new Monitor
Is it worth upgrading from a 34" ultrawide to a 38" ultrawide?
Did you know that the handy, dandy application jq is great for formatting json AND it's also Turing complete? You can do full on programming inside jq to make changes - conditionals, variables, math, filtering, mapping...it's Turing Complete! https://stedolan.github.io/jq/
Want to freshen up your space, but you just don't have the vision? Give interiorai.com a chance, upload a picture of your room and give it a description. It works better than it should.
You can sort your command line output when doing something like an ls sort -k2 -b
On macOS you can drag a non-fullscreen window to a fullscreen desktop
When using the ls -l command in a terminal, that first numeric column shows the number of hard links to a file - meaning the number of names an inode has for that file
Ever wonder how database backups work if new data is coming in while the backup is running? Hang with us while we talk about that, while Allen doesn't stand a chance, Outlaw is in love, and Joe forgets his radio voice.
It’s time we learn about multi-object transactions as we continue our journey into Designing Data-Intensive Applications, while Allen didn’t specifically have that thought, Joe took a marketing class, and Michael promised he wouldn’t cry.
Multi-object transactions need to know which reads and writes are part of the same transaction.
In an RDBMS, this is typically handled by a unique transaction identifier managed by a transaction manager.
All statements between the BEGIN TRANSACTIONandCOMMIT TRANSACTION are part of that transaction.
Many non-relational databases don’t have a way of grouping those statements together.
Single object transactions must also be atomic and isolated.
Reading values while in the process of writing updated values would yield really weird results.
It’s for this reason that nearly all databases must support single object atomicity and isolation.
Atomicity is achievable with a log for crash recovery.
Isolation is achieved by locking the object to be written.
Some databases use a more complex atomic setup, such as an incrementer, eliminating the need for a read, modify, write cycle.
Another operation used is a compare and set.
These types of operations are useful for ensuring good writes when multiple clients are attempting to write the same object concurrently.
Transactions are more typically known for grouping multiple object writes into a single operational unit
Need for multi object transactions
Many distributed databases / datastores don’t have transactions because they are difficult to implement across partitions.
This can also cause problems for high performance or availability needs.
But there is no technical reason distributed transactions are not possible.
The author poses the question in the book: “Do we even need transactions?”
The short answer is, yes sometimes, such as:
Relational database systems where rows in tables link to rows in other tables,
In non-relational systems when data is denormalized for “object” reasons, those records need to be updated in a single shot, or
Indexes against tables in relational databases need to be updated at the same time as the underlying records in the tables.
These can be handled without database transactions, but error handling on the application side becomes much more difficult.
Lack of isolation can cause concurrency problems.
Handling errors and aborts
ACID transactions that fail are easily retry-able.
Some systems with leaderless replication follow the “best effort” basis. The database will do what it can, and if something fails in the middle, it’ll leave anything that was written, meaning it won’t undo anything it already finished.
This puts all the burden on the application to recover from an error or failure.
The book calls out developers saying that we only like to think about the happy path and not worry about what happens when something goes wrong.
The author also mentioned there are a number of ORM’s that don’t do transactions proud and rather than building in some retry functionality, if something goes wrong, it’ll just bubble an error up the stack, specifically calling out Rails ActiveRecord and Django.
Even ACID transactions aren’t necessarily perfect.
What if a transaction actually succeeded but the notification to the client got interrupted and now the application thinks it needs to try again, and MIGHT actually write a duplicate?
If an error is due to “overload”, basically a condition that will continue to error constantly, this could cause an unnecessary load of retries against the database.
Retrying may be pointless if there are network errors occurring.
Retrying something that will always yield an error is also pointless, such as a constraint violation.
There may be situations where your transactions trigger other actions, such as emails, SMS messages, etc. and in those situations you wouldn’t want to send new notifications every time you retry a transaction as it might generate a lot of noise.
When dealing with multiple systems such as the previous example, you may want to use something called a two-phase commit.
Tip of the Week
Manything is an app that lets you use your old devices as security cameras. You install the app on your old phone or tablet, hit record, and configure motion detection. A much easier and cheaper option than ordering a camera! (apps.apple.com, play.google.com)
The Linux Foundation offers training and certifications. Many great training courses, some free, some paid. There’s a nice Introduction to Kubernetes course you can try, and any money you do spend is going to a good place! (training.linuxfoundation.org)
Kubernetes has recommendations for common-labels. The labels are helpful and standardization makes it easier to write tooling and queries around them. (kubernetes.io)
Markdown Presentation for Visual Studio Code, thanks for the tip Nathan V! Marp lets you create slideshows from markdown in Visual Studio Code and helps you separate your content from the format. It looks great and it’s easy to version and re-use the data! (marketplace.visualstudio.com)
We decided to knock the dust off our copies of Designing Data-Intensive Applications to learn about transactions while Michael is full of solutions, Allen isn’t deterred by Cheater McCheaterton, and Joe realizes wurds iz hard.
Great statement from one of the creators of Google’s Spanner where the general idea is that it’s better to have transactions as an available feature even if it has performance issues and let developers decide if the performance is worth the tradeoff, rather than not having transactions and putting all that complexity on the developer.
Number of things that can go wrong during database interactions:
DB software or underlying hardware could fail during a write,
An application that uses the DB might crash in the middle of a series of operations,
Network problems could arise,
Multiple writes to the same records from multiple places causing race conditions,
Reads could happen to partially updated data which may not make sense, and/or
Race conditions between clients could cause weird problems.
“Reliable” systems can handle those situations and ensure they don’t cause catastrophic failures, but making a system “reliable” is a lot of work.
Transactions are what have been used for decades to address those issues.
A transaction is a way to group all related reads and writes into a single operation.
Either a transaction as a whole completes successfully as a “commit” or fails as an “abort, rollback”.
If the transaction fails, the application can choose what to do, like retry for example.
In general, transactions make error handling much simpler for an application.
That was their purpose, to make developing against a database much simpler.
Not all applications need transactions.
In some cases, it makes sense not to use transactions for performance and/or availability reasons.
How do you know if you need a transaction?
What are the safety guarantees?
What are the costs of using them?
Concepts of a transaction
Most relational DBs support transactions and some non-relational DBs support transactions.
The general idea of a transaction has been around mostly unchanged for over 40 years, originally introduced in IBM System R, the first relational database.
With the introduction of a lot of the NoSQL (non-relational) databases, transactions were left out.
In some NoSQL implementations, they redefined what a transaction meant with a weaker set of guarantees.
A popular belief was put out there that transactions meant anti-scalable.
Another popular belief was that to have a “serious” database, it had to have transactions.
The book calls out both as hyperbole.
The reality is there are tradeoffs for both having or not having transactions.
ACID is the acronym to describe the safety guarantees of databases and stands for Atomicity, Consistency, Isolation, and Durability.
Coined in 1983 by Theo Harder and Andreas Reuter.
The reality is that each database’s implementation of ACID may be very different.
Lots of ambiguity for what Isolation means.
Because ACID doesn’t specify the actual guarantees, it’s basically a marketing term.
Systems that don’t support ACID are often referred to as BASE, BAsically available, Soft state, and Eventual consistency.
Even more vague than ACID! BASE, more or less, just means anything but ACID.
Atomicity
Atomicity refers to something that can not be broken into smaller parts.
In terms of multi-threaded programming, this means you can only see the state of something before or after a complete operation and nothing in-between.
In the world of database and ACID, atomicity has nothing to do with concurrency. For instance, if multiple actions are trying to processes the same data, that’s covered under Isolation.
Instead, ACID describes what should happen if there is a fault while performing multiple related writes.
For example, if a group of related writes are to be performed in an operation and there is some underlying error that occurs before the transaction of writes can be committed, then the operation is aborted and any writes that occurred during that operation must be undone, i.e. rolled back.
Without atomicity, it is difficult to know what part of the operation completed and what failed.
The benefit of the rollback is you don’t have to have any special logic in your application to figure out how to get back to the original state. You can just simply try again because the transaction took care of the cleanup for you.
This ability to get rid of any writes after an abort is basically what the atomicity is all about.
Consistency
In ACID, consistency just means the database is in a good state.
But consistency is a property of the application as it’s what defines the invariants for its operations.
This means that you must write your application transactions properly to satisfy the invariants that have been defined.
The database can take care of certain invariants, such as foreign key constraints and uniqueness constraints, but otherwise it’s left up to the application to set up the transactions properly.
The book suggests that because the consistency is on the application’s shoulders, the C shouldn’t be part of ACID.
Isolation
Isolation is all about handling concurrency problems and race conditions.
The author provided an example of two clients trying to increment a single database counter concurrently, the value should have gone from 3 to 5, but only went to 4 because there was a race condition.
Isolation means that the transactions are isolated from each other so the previous example cannot happen.
The book doesn’t dive deep on various forms of isolation implementations here as they go deeper in later sections, however one that was brought up was treating every transaction as if it was a serial transaction. The problem with this is there is a rather severe performance hit for forcing everything serially.
The section that describes the additional isolation levels is “Weak Isolation Levels”.
Durability
Durability just means that once the database has committed a write, the data will not be forgotten, even if a database failure or hardware failure occurs.
This notion of durability typically means, in a single node database, that the data has been written to the drive, typically to a write-ahead log or similar implementation.
The write-ahead log ensures if there is any data corruption in the database, that it can be rebuilt, if necessary.
In a replicated database, durability means that the data has been written to the other nodes successfully.
The performance implication here is that for the database to guarantee that it’s durable, it must wait for those distributed writes to complete before committing the transaction.
PERFECT DURABILITY DOES NOT EXIST.
If all your databases and backups somehow got destroyed at the same time, there’s absolutely nothing you could do.
Longevity of Recordable CDs, DVDs and Blu-rays – Canadian Conservation Institute (CCI) Notes 19/1 (canada.ca)
Tip of the Week
The Bad Plus is an instrumental band that makes amazing music that’s perfect for programming. It’s a little wild, and a little strange. Maybe like Radiohead, but a saxophone instead of Thom Yorke? Maybe? (YouTube)
Correction, Piano Rock will quickly become your new favorite channel. (YouTube)
docker builder is a command prefix that you can use that specifically operates against the builder. For example you can prune the builder’s cache without wiping out your local cache. It can really save your bacon if you’re working with a lot of images. (docs.docker.com)
Ever want to convert YAML to JSON so you can see nesting issues easier? There’s a VSCode plugin for that! Search for hilleer.yaml-plus-json or find it on GitHub. (GitHub)
Spotify has a great interface, but Apple Audio has lossless audio, sounds great, and pays artists more. Give it a shot! If you sign up for Apple One you can get Apple Music, Apple TV+, Apple Arcade, Apple News+ and a lot more for one unified price. (Apple)
Michael spends the holidays changing his passwords, Joe forgot to cancel his subscriptions, and Allen’s busy playing Call of Duty: Modern Healthcare as we discuss the our 2023 resolutions.
You can pipe directly to Visual Studio Code (in bash anyway), much easier than outputting to a file and opening it in Code … especially if you end up accidentally checking it in!
Is your trackpad not responding on your new(-ish) MacBook? Run a piece of paper around the edge to clean out any gunk. Also maybe avoid dripping BBQ sauce on it.
How does the iOS MFA / Verification Code settings work? We want MFA, but we we’re tired of the runaround!
Jump around – nope, not Kris Kross, great tip from Thiyagarajan – keeps track of your most “frecent” directories to make navigation easier (GitHub)
There’s a version for PowerShell too – thank you Brad Knowles! (GitHub)
We take a few to step back and look at how things have changed since we first started the show while Outlaw is dancing on tables, Allen really knows his movie monsters, and Joe's math is on point.
We've wrapped up 9 years…how have we changed the most…why?
Bonus: Buying a window with 3 huge tvs (youtube.com)
Top 3 things you've gotten out of it …
Alphabetize all the things in your class
A better understanding of DB technologies and the impact of their underlying data structures
It's forced us to study various topics …
Amazing friends, community
The application tier can / should be your most powerful
Don't make your tech-du-jour a hammer
Tip of the Week
If you want to enable Markdown support, open a document in Google Docs, head over to the top of the screen, go to “Tools” then “Preferences” and enable “Automatically detect Markdown.” After that, you’re good to go..except this only works for the current doc. (techcrunch.com)
Markdown Viewer is also a plugin for Chrome that lets you support .md files in Google Drive (workspace.google.com)
DataGrip's useless "error at position" messages are frustrating, but the IDE actually does give you the info you need. Check your cursor!
Minikube's "profile" feature makes it easy to swap between clusters. No more tearing down and rebuilding if you need to switch to a new task! (minikube.sigs.k8s.io)
SQLforDevs.com has a free ebook: Next-Level Database Techniques for Developers. (sqlfordevs.com)
We talk about career management and interview tips, pushing data contracts "left", and our favorite dev books while Outlaw is [redacted], Joe's trying to figure out how to hire junior devs, and Allen's trying to screw some nails in.
Interesting article about AI potentially replacing recruiters at Amazon (vox.com)
From 'Round the Water-Cooler
Why don't companies want junior developers?
You see a lot of advice out there for developers to get that first job, but what advice does the industry have to trying to hire and support them? …not much
How long do you need to stay at a job?
What do you do if you're worried about being a "job hopper"?
Interviewing…know what the company is creating so you'll have an idea of what challenges they may have technically and so you can look up how you might solve some of those problems
How do you decide when to bring in new tech?
Right tool for the job - don't always be jumping ship to the newest, shiniest thing - it might be you just need to augment your stack with a new piece of technology rather than thinking something new will solve ALL your problems
Tip of the Week
Did you know Obsidian has a command palette similar to Code? Same short-cut (Cmd/Ctrl-P) as VS Code and it makes for a great learning curve! Don't know how to make something italic? Cmd-P. Insert a template? Cmd-P. Pretty much anything you want to do, but don't know how to do. Cmd P! (help.obsidian.md)
Ghostery plugin for Firefox cuts down on ads and protects your privacy. Thanks for the tip Aaron Jeskie! (addons.mozilla.org)
Amazing prank to play on Windows user, hit F-11 to full screen this website next time your co-worker or family member leaves their computer unlocked. Thanks Scott Harden! (fakeupdate.net)
We take a peak into some of the challenges Twitter has faced while solving data problems at large scale, while Michael challenges the audience, Joe speaks from experience, and Allen blindsides them both.
In 2019, over 100 million people per day would visit Twitter.
Every tweet and user action creates an event that is used by machine learning and employees for analytics.
Their goal was to democratize data analysis within Twitter to allow people with various skillsets to analyze and/or visualize the data.
At the time, various technologies were used for data analysis:
Scalding which required programmer knowledge, and
Presto and Vertica which had performance issues at scale.
Another problem was having data spread across multiple systems without a simple way to access it.
Moving pieces to Google Cloud Platform
The Google Cloud big data tools at play:
BigQuery, a cost-effective, serverless, multicloud enterprise data warehouse to power your data-driven innovation.
DataStudio, unifying data in one place with ability to explore, visualize and tell stories with the data.
History of Data Warehousing at Twitter
2011 – Data analysis was done with Vertica and Hadoop and data was ingested using Pig for MapReduce.
2012 – Replaced Pig with Scalding using Scala APIs that were geared towards creating complex pipelines that were easy to test. However, it was difficult for people with SQL skills to pick up.
2016 – Started using Presto to access Hadoop data using SQL and also used Spark for ad hoc data science and machine learning.
2018 …
Scalding for production pipelines,
Scalding and Spark for ad hoc data science and machine learning,
Vertica and Presto for ad hoc, interactive SQL analysis,
Druid for interactive, exploratory access to time-series metrics, and
Tableau, Zeppelin, and Pivot for data visualization.
So why the change? To simplify analytical tools for Twitter employees.
BigQuery for Everyone
Challenges:
Needed to develop an infrastructure to reliably ingest large amounts of data,
Support company-wide data management,
Implement access controls,
Ensure customer privacy, and
Build systems for:
Resource allocation,
Monitoring, and
Charge-back.
In 2018, they rolled out an alpha release.
The most frequently used tables were offered with personal data removed.
Over 250 users, from engineering, finance, and marketing used the alpha.
Sometime around June of 2019, they had a month where 8,000 queries were run that processed over 100 petabytes of data, not including scheduled reports.
The alpha turned out to be a large success so they moved forward with more using BigQuery.
They have a nice diagram that’s an overview of what their processes looked like at this time, where they essentially pushed data into GCS from on-premise Hadoop data clusters, and then used Airflow to move that into BigQuery, from which Data Studio pulled its data.
Ease of Use
BigQuery was easy to use because it didn’t require the installation of special tools and instead was easy to navigate via a web UI.
Users did need to become familiar with some GCP and BigQuery concepts such as projects, datasets, and tables.
They developed educational material for users which helped get people up and running with BigQuery and Data Studio.
In regards to loading data, they looked at various pieces …
Cloud Composer (managed Airflow) couldn’t be used due to Domain Restricted Sharing (data governance).
Google Data Transfer Service was not flexible enough for data pipelines with dependencies.
They ended up using Apache Airflow as they could customize it to their needs.
For data transformation, once data was in BigQuery, they created scheduled jobs to do simple SQL transforms.
For complex transformations, they planned to use Airflow or Cloud Composer with Cloud Dataflow.
Performance
BigQuery is not for low-latency, high-throughput queries, or for low-latency, time-series analytics.
It is for SQL queries that process large amounts of data.
Their requirements for their BigQuery usage was to return results within a minute.
To achieve these requirements, they allowed their internal customers to reserve minimum slots for their queries, where a slot is a unit of computational capacity to execute a query.
The engineering team had to analyze 800+ queries, each processing around 1TB of data, to figure out how to allocate the proper slots for production and other environments.
Data Governance
Twitter focused on discoverability, access control, security, and privacy.
For data discovery and management, they extended their DAL to work with both their on-premise and GCP data, providing a single API to query all sets of data.
In regards to controlling access to the data, they took advantage of two GCP features:
Domain restricted sharing, meaning only users inside Twitter could access the data, and
VPC service controls to prevent data exfiltration as well as only allow access from known IP ranges.
Authentication, Authorization, and Auditing
For authentication, they used GCP user accounts for ad hoc queries and service accounts for production queries.
For authorization, each dataset had an owner service account and a reader group.
For auditing, they exported BigQuery stackdriver logs with detailed execution information to BigQuery datasets for analysis.
Ensuring Proper Handling of Private Data
They required registering all BigQuery datasets,
Annotate private data,
Use proper retention, and
Scrub and remove data that was deleted by users.
Privacy Categories for Datasets
Highly sensitive datasets are available on an as-needed basis with least privilege.
These have individual reader groups that are actively monitored.
Medium sensitivity datasets are anonymized data sets with no PII (Personally identifiable information) and provide a good balance between privacy and utility, such as, how many users used a particular feature without knowing who the users were.
Low sensitivity datasets are datasets where all user level information is removed.
Public datasets are available to everyone within Twitter.
Scheduled tasks were used to register datasets with the DAL, as well as a number of additional things.
Cost
Roughly the same for querying Presto vs BigQuery.
There are additional costs associated with storing data in GCS and BigQuery.
Utilized flat-rate pricing so they didn’t have to figure out fluctuating costs of running ad hoc queries.
In some situations where querying 10’s of petabytes, it was more cost-effective to utilize Presto querying data in GCS storage.
Could you build Twitter in a weekend?
Resources
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Characters Sets (No Excuses!) (JoelOnSoftware.com)
Scaling data access by moving an exabyte of data to Google Cloud (blog.twitter.com)
Democratizing data analysis with Google BigQuery (blog.twitter.com)
Google BigQuery, Cloud data warehouse to power your data-driven innovation (cloud.google.com)
Elon Musk and Twitter employees engage in war of words (NewsBytesApp.com)
Tip of the Week
VS Code has a plugin for Kubernetes and it’s actually very nice! Particularly when you “attach” to the container. It installs a couple bits on the container, and you can treat it like a local computer. The only thing to watch for … it’s very easy to set your local context! (marketplace.visualstudio.com)
kafkactl is a great command line tool for managing Apache Kafka and has a consistent API that is intuitive to use. (deviceinsight.github.io)
Cruise Control is a tool for Apache Kafka that helps balance resource utilization, detect and alert on problems, and administrate. (GitHub)
iTerm2 is a terminal emulator for macOS that does amazing things. Why aren’t you already using it? (iterm2.com)
Message compression in Kafka will help you save a lot of space and network bandwidth, and the compression is per message so it’s easy to enable in existing systems! (cwiki.apache.org)
It’s that time of year where we’ve got money burning a hole in our pockets. That’s right, it’s time for the annual shopping spree. Meanwhile, Fiona Allen is being gross, Joe throws shade at Burger King, and Michael has a new character encoding method.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Well, you know Joe has to be a little different so the format’s a bit different here! What if there was a way to spend money that could actually make you happy? Check out this article: Yes, you can buy happiness … if you spend it to save time (CNBC).
Ideas for ways to spend $2k to save you time
A good mattress will improve your sleep, and therefore your amount of quality time in a day! ($1k),
Cleaning Service ($100 – $300 per month),
Massage ($50 per month),
Car Wash Subscription ($20 per month),
Grocery Delivery Service (Shipt is $10 a month + up charges on items),
How do you fix a typo on your phone? Try pressing and then sliding your thumb on the space bar! It’s a nifty trick to keep you in the flow. And it works on both Android and iOS.
Heading off to holiday? Here’s an addendum to episode 191‘s Tip of the Week … Don’t forget your calendar!
On iOS, go to Settings -> Mail -> Accounts -> Select your work account -> Turn off the Mail and Calendar sliders.
Also, in Slack, you can pause notifications for an extended period and if you do, it’ll automatically change your status to Vacationing .
Did you know that Docker only has an image cache locally, there isn’t a local registry installed? This matters if you go to use something like microk8s instead of minikube! (microk8s.io)
What if you want to see what process has a file locked?
In Windows, Ronald Sahagun let us know you can use File Locksmith in PowerToys from Microsoft. (learn.microsoft.com)
In Linux based systems, Dave Follett points out you can just cat the process ID file in your /proc directory: cat /proc/<processId> to see what’s locked. LS Locks makes it easy too, just run the command and grep for your file. (Stack Exchange)
We gather around the watercooler to discuss the latest gossip and shenanigans have been called while Coach Allen is not wrong, Michael gets called out, and Joe gets it right the first time.
DuckDB is an in-process SQL OLAP database management system. You can use it from the command line, drop it into your POM file, pip install it, or npm install it, and then you can easily work with CSV or Parquet files as if they were a database. (duckdb.org)
It’s really easy to try out in the browser too! (shell.duckdb.org)
Want to be sure a file or URL is safe? Use Virus Total to find out. From VirusTotal: VirusTotal inspects items with over 70 antivirus scanners and URL/domain blocklisting services, in addition to a myriad of tools to extract signals from the studied content. (virustotal.com)
How to Show & Verify Code Signatures for Apps in Mac OS X (osxdaily.com)
tldr: codesign -dv --verbose=4 /path/to/some.app
How to Get GitHub-like Diff Support in Git on the Command-Line (matthewsetter.com)
Speed up development cycles when working in Kubernetes with Telepresence. (telepresence.io)
We wrap up Git from the Bottom Up by John Wiegley while Joe has a convenient excuse, Allen gets thrown under the bus, and Michael somehow made it worse.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
News
Thanks for the reviews on iTunes jessetsilva, Marco Fernandooo, and sysadmike702!
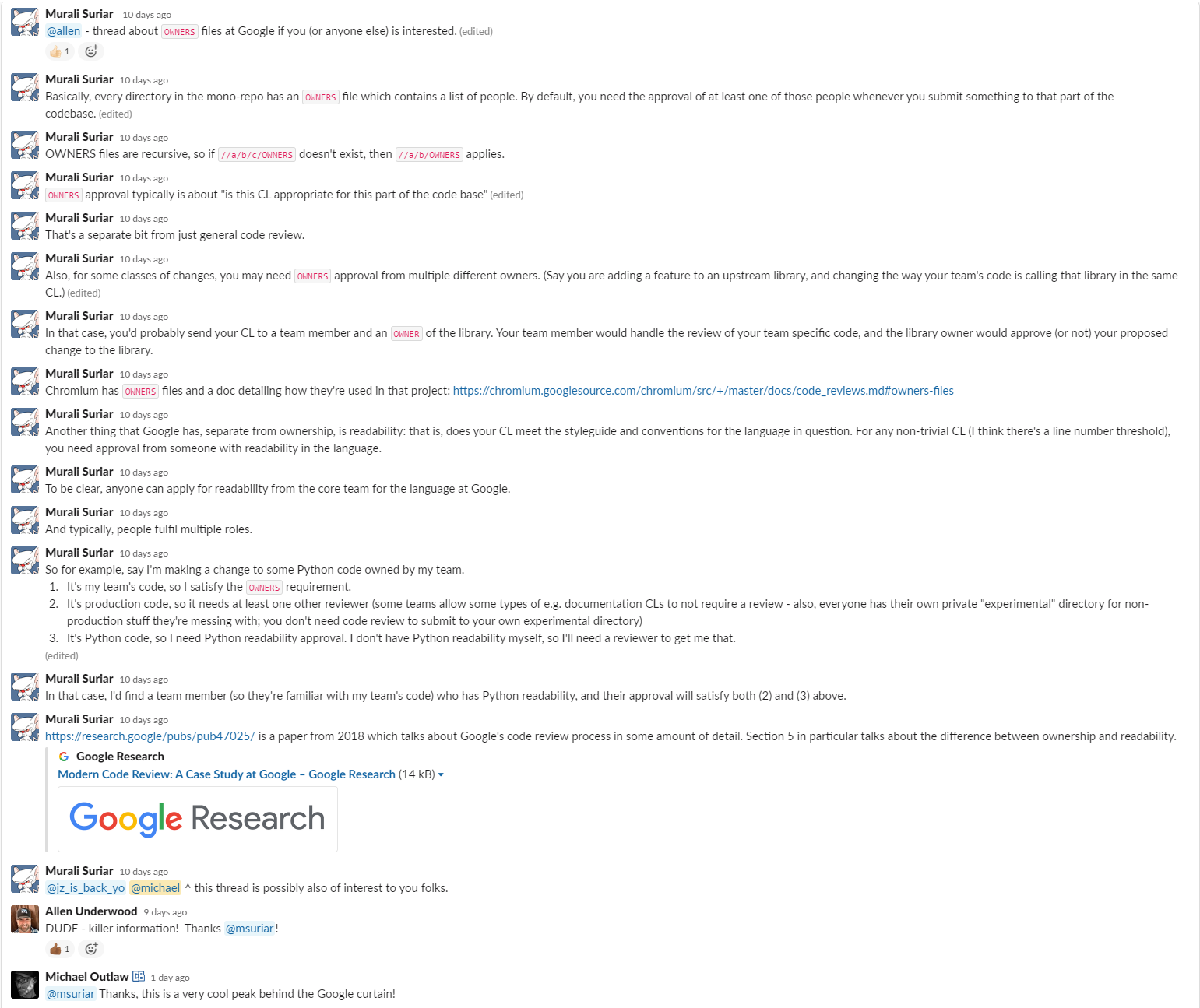
Git’s reset is likely one of the commands that people shy away from using because it can mess with your working tree as well as what commit HEAD references.
reset is a reference editor, an index editor and a working tree editor.
git reset
Modifies HEAD?
Modifies the index?
Modifies the working tree?
--mixed
YES
YES. Removes all staged changes from the index, effectively unstaging them back to the working tree.
YES. All changes from the reset commit(s) are put in the working tree. Any previous changes are merged with the reset commit(s)’s changes in the working tree.
--soft
YES
YES. All changes from the reset commit(s) are put in the index. Any previously staged changes are merged with the reset commit(s)’s changes in the index.
NO. Any changes in the working tree are left untouched.
--hard
YES
YES. Clears the index of any staged changes.
YES. Clears the working tree of any unstaged changes.
What do the git reset mode flags change?
Mixed reset
--mixed is the default mode.
If you do a reset --mixed of more than one commit, all of those changes will be put back in the working tree together essentially setting you up for a squash of those commits.
Soft Reset
These two commands are equivalent, both effectively ignoring the last commit:
git reset --soft HEAD^
git update-ref HEAD HEAD^
If you did a git status after either of the previous commands, you’d see more changes because your working tree is now being compared to a different commit, assuming you previously had changes in your working tree.
This effectively allows you to create a new commit in place of the old one.
Instead of doing this, you can always do git commit --amend.
Similar to the use of --mixed for multiple commits, if you do a reset --soft of more than one commit, all of those changes will be put back in the index together essentially setting you up for a squash of those commits.
Hard Reset
This can be one of the most consequential commands.
Performing git reset --hard HEAD will get rid of any changes in your index and working tree to all tracked files, such that all of your files will match the contents of HEAD.
If you do a reset --hard to an earlier commit, such as git reset --hard HEAD~3, Git is removing changes from your working tree to match the state of the files from the earlier commit, and it’s changing HEAD to reference that earlier commit. Similar to the previous point, all uncommitted changes to tracked files are undone.
Again, this is a destructive/dangerous way to do something like this and there is another way that is safer:
Instead, perform a git stash followed by git checkout -b new-branch HEAD~3.
This will save, i.e. stash, your index and working tree changes, and then check out a new branch that references HEAD‘s great grandparent.
git stash saves your work in a stash that you can then apply to any branch you wish in the future; it is not branch specific.
Checking out a new branch to the older state allows you to maintain your previous branch and still make the changes you wanted on your new branch.
If you decide that you like what is in your new branch better than your old branch, you can run these commands:
git branch -D oldbranch
git branch -m newbranch oldbranch
After learning all of this, the author’s recommendation is to always do the stashing/branch creation as it’s safer and there’s basically no real overhead to it.
If you do accidentally blow away changes, the author mentions that you can do a restore from the reflog such as git reset --hard HEAD@{1}.
The author also recommends ALWAYS doing a git stash before doing a git reset --hard
This allows you to do a git stash apply and recover anything you lost, i.e. nice backup plan.
As mentioned previously, if you have other consumers of your branch/commits, you should be careful when making changes that modify history like this as it can force unexpected merges to happen to your consumers.
Stashing and the Reflog
There are two new ways that blobs can make their way into the repository.
The first is the reflog, a metadata repository that records everything you do in your repository.
So any time you make a commit in your repository, a commit is also being made to the reflog.
You can view the reflog with git reflog.
The glorious thing about the reflog is even if you did something like a git reset and blew away your changes, any changes previously committed would still exist in the reflog for at least 30 days, before being garbage collected (assuming you don’t manually run garbage collection).
This allows you to recover a commit that you deleted in your repository.
The other place that a blob can exist is in your working tree, albeit not directly noticeable.
If you modified foo.java but you didn’t add it to the index, you can still see what the hash would be by running git hash-object foo.java.
In this regard, the change exists on your filesystem instead of Git’s repository.
The author recommends stashing any changes at the end of the day even if you’re not ready to add anything to your index or commit it.
By doing so, Git will store all of your working tree changes and current index as the necessary trees and blobs in your git repository along with a couple of commits for storing the state of the working tree and index.
The next day, you come back in, run a git stash apply and all of your changes are back in your working tree.
So why do that? You’re just back in the same state you were the night before, yeah? Well, except now those commits that happened due to the stash are something you can go back to in your reflog, in case of an emergency!
Another special thing, because stashes are stored as commits, you can interact with them just like any other branch, at any time!
git checkout -b temp stash@{32}
In the above command, you can checkout a stash you did 32 days ago, assuming you were doing a single stash per day!
If you want to cleanup your stash history, DO NOT USE git stash clear as it kills all your stash history.
Instead, use git reflog expire --expire=30.days refs/stash to let your stashes expire.
One last tip the author mentioned is you could even roll your own snapshot type command by simply doing a git stash && git stash apply.
The Pragmatic Programmer – How to Build Pragmatic Teams (Episode 114)
Tip of the Week
A couple episodes back (episode 192), Allen mentioned Obsidian, a note taking app that operates on markdown files so you can use it offline if you want or you can keep the files in something like DropBox or pay a monthly fee for syncing. Good stuff, and if you ever want to leave the service … you have the markdown files! That’s an old tip, but Joe has been using it lately and wanted add a couple supplemental tips now that he’s gotten more experience with it.
If Obsidian just manages markdown files, then why bother? Why not just use something like VSCode? Because, Obsidian is also a rich client that is designed to help you manage markdown with features built in for things like search, tags, cross-linking etc.
Obsidian supports templates, so you can, for example, create a template for common activities … like if you keep a daily TODO list that has the same items on it every day, you can just {{include}} it to dump a copy of that checklist or whatever in. (help.obsidian.md)
Obsidian is designed to support multiple “vaults” up front. This lets you, for example, have one vault that you use for managing your personal life that you choose to sync to all of your devices, and one for work that is isolated in another location and doesn’t sync so you don’t have to worry about exfiltrating my work notes.
Community extensions! People have written interesting extensions, like a Calendar View or a Kanban board, but ultimately they serialize down to markdown files so if the extension (for example) doesn’t work on mobile then you can still somewhat function.
All of the files that Obsidian manages have to have a .md file extension. Joe wanted to store some .http files in his vault because it’s easy to associate them with his notes, but he also wanted to be able to execute them using the REST Client extension … which assumes a .http extension. The easiest solution Joe found was just to change the file type in the lower right hand corner in VSCode and it works great. This works for other extensions, too, of course! (GitHub)
[Wireless] How to improve compatibility of IoT device with ASUS WiFi 6(AX) Router? (ASUS)
Google’s new mesh Wi-Fi solution with support for Wi-Fi 6e is out, Google Nest Wifi Pro, and looks promising. (store.google.com)
Terran Antipodes sent Allen a tip that we had to share, saying that you can place your lower lip between your teeth to hold back a sneeze. No need to bite down or anything, it just works! All without the worry of an aneurysm.
This episode, we learn more about Git’s Index and compare it to other version control systems while Joe is throwing shade, Michael learns a new command, and Allen makes it gross.
Ludum Dare is a bi-annual game jam that’s been running for over 20 years now. Jam #51 is coming up September 30th to October 3rd. (ldjam.com)
We previously talked about Ludum Dare in episode 146.
The Index
Meet the Middle Man
The index refers to the set of blobs and trees created when running a git add, when you “stage” files.
These trees and blobs are not a part of the repository yet!
If you were to unstage the changes using a reset, you’d have an orphaned blob(s) that would eventually get cleaned up.
The index is a staging area for your next commit.
The staging area allows you to build up your next commit in stages.
You can almost ignore the index by doing a git commit -a (but shouldn’t).
In Subversion, the next set of changes is always determined by looking at the differences in the current working tree.
In Git, the next set of changes is determined by looking at your index and comparing that to the latest HEAD.
git add allows you to make additional changes before executing your commit with things like git add --patch and git add --interactive parameters.
For Emacs fans out there, the author mentioned gitsum. (GitHub)
Taking the Index Further
The author mentions “Quilt!”, is it this? (man7.org)
The primary difference between Git and Quilt is Git only allows one patch to be constructed at a time.
Situation the author describes is: What if I had multiple changes I wanted to test independently with each other?
There isn’t anything built into Git to allow you to try out parallel sets of changes on the fly.
Multiple branches would allow you to try out different combinations and the index allows you to stage your changes in a series of commits, but you can’t do both at the same time.
To do this you’d need an index that allows for more than a single commit at a time.
Stacked Git is a tool that lets you prepare more than one index at a time. (stacked-git.github.io)
The author gives an example of using regular Git to do two commits by interactively selecting a patch.
Then, the author gives the example of how you’d have to go about disabling one set of changes to test the other set of changes. It’s not great … swapping between branches, cherry-picking changes, etc.
If you find yourself in this situation, definitely take a look at Stacked Git. Using Stacked Git, you are basically pushing and popping commits on a stack.
Diffusion Bee is GUI for running Stable Diffusion on M1 macs. It’s got a one-click installer that you can get up and generating weird computer art in minutes … as long as you’re on a recent version of macOS and M1 hardware. (GitHub)
No M1 Mac? You can install the various packages you need to do it yourself, some assembly required! (assembly.ai)
Git Tower is a fresh take on Git UI that lets you drag-n-drop branches, undo changes, and manage conflicts. Give it a shot! (git-tower.com)
Git Kraken is the Gold Standard when it comes to Git UIs. It’s a rich, fully featured environment for managing all of your branches and changes. They are also the people behind the popular VS Code Extension GitLens (gitkraken.com)
GitHub CLI is an easy to use command line interface for interacting with GitHub. Reason 532 to love it … draft PR creation via gh pr create --draft ! (cli.github.com)
It’s time to understand the full power of Git’s rebase capabilities while Allen takes a call from Doc Brown, Michael is breaking stuff all day long, and Joe must be punished.
Ludum Dare is a bi-annual game jam that’s been running for over 20 years now. Jam #51 is coming up September 30th to October 3rd. (ldjam.com)
We previously talked about Ludum Dare in episode 146.
Branching and the power of rebase
Every branch you work in typically has one or more base commits, i.e. the commits the branch started from.
git branch shows the branches in your local repo.
git show-branch shows the branch ancestry in your local repo.
Reading the output from the bottom up takes you from oldest to newest history in the branches
Plus signs, are used to indicate commits on divergent branches from the one that’s currently checked out.
An asterisk, is used to indicate commits that happened on the current branch.
At the top of the output above the dashed line, the output shows the branches, the column and color that will identify their commits, and the label used when identifying their commits.
Consider an example repo where we have two branches, T and F, where T = Trunk and F = Feature and the commit history looks like this:
What we want to do is bring Feature up to date with what’s in Trunk, so bring T2, T3, and T4 into F3.
In most source control systems, your only option here is to merge, which you can also do in Git, and should be done if this is a published branch where we don’t want to change history.
After a merge, the commit tree would look like this:
The F3' commit is essentially a “meta-commit” because it’s showing the work necessary to bring T4 and F3 together in the repository but contains no new changes from the working tree (assuming there were no merge conflicts to resolve, etc.)
If you would rather have your work in your Feature branch be directly based on the commits from Trunk rather than merge commits, you can do a git rebase, but you should only do this for local development.
The resulting branch would look like this:
You should only rebase local branches because you’re potentially rewriting commits and you should not change public history.
When doing the merge, the merge commit, F3' is an instruction on how to transform F3 + T4.
When doing the rebase, the commits are being rewritten, such that F1' is based on T4 as if that’s how it was originally written by the author.
Use rebase for local branches that don’t have other branches off it, otherwise use merge for anything else.
Interactive rebasing
git rebase will try to automatically do all the merging.
git rebase -i will allow you to handle every aspect of the rebase process.
pick – This is the default behavior when not using -i. The commit should be applied to its rewritten parent. If there are conflicts, you’re allowed to resolve them before continuing.
squash – Use this option when you want to combine the contents of a commit into the previous commit rather than keeping the commits separate. This is useful for when you want multiple commits to be rewritten as a single commit.
edit – This will stop the rebasing process at that commit and let you make any changes before doing a git rebase --continue. This allows you to make changes in the middle of the process, making it look like the edit was always there.
drop – Use when you want to remove a commit from the history as if it had never been committed. You can also remove the commit from the list or comment it out from the rebase file to get the same results. If there were any commits later that depended on the dropped commit, you will get merge conflicts.
Interactive gives you the ability to reshape your branch to how you wish you’d done it in the first place, such as reordering commits.
Site Reliability Engineering – Embracing Risk (episode 182)
Tip of the Week
Russian Circles is a rock band that makes gloomy, mid-tempo, instrumental music that’s perfect for coding. They just put out a new album and, much like the others, it’s great for coding to! (YouTube)
GitLens for Visual Studio Code is an open-source extension for Visual Studio Code that brings in a lot more information from your Git repository into your editor. (marketplace.visualstudio.com)
JSON Crack is a website that makes it easy to “crack” JSON documents and view them hierarchically. Great for large docs. Thanks for the tip Thiyagu! (JsonCrack.com)
Handle is a Windows utility that you can use to see which process has a “handle” on your resource. Thanks for the tip Larry Weiss! (docs.microsoft.com)
Crunchy Data has made it so you can run PostgreSQL in the browser thanks to WASM. Technically very cool, and it’s a great way to learn Postgres. Thanks for the tip Mikerg! (Crunchy Data)
Divvy is a cool new window manager for macOS. It’s cool, modern, and much more powerful than the built in manager! Thanks for the tip jonasbn! (apps.apple.com)
We are committed to continuing our deep dive into Git from the Bottom Up by John Wiegley, while Allen puts too much thought into onions, Michael still doesn’t understand proper nouns, and Joe is out hat shopping.
Ludum Dare is a bi-annual game jam that’s been running for over 20 years now. Jam #51 is coming up Sept 30th to October 3rd. (ldjam.com)
We previously talked about Ludum Dare in episode 146.
Commitment Issues
Commits
A commit can have one or more parents.
Those commits can have one more parents.
It’s for this reason that commits can be treated like branches, because they know their entire lineage.
You can examine top level referenced commits with the following command: git branch -v.
A branch is just a named reference to a commit!
A branch and a tag both name a commit, with the exception that a tag can have a description, similar to a commit.
Branches are just names that point to a commit.
Tags have descriptions and point to a commit.
Knowing the above two points, you actually don’t technically need branches or tags. You could do everything pointing to the commit hash id’s if you were insane enough to do so.
Here’s a dangerous command:
git reset --hard commitHash – This is dangerous. --hard says to erase all changes in the working tree, whether they were registered for a check-in or not and reset HEAD to point to the commitHash.
Here’s a safer command:
git checkout commitHash – This is a safer option, because files changed in the working tree are preserved. However, adding the -f parameter acts similar as the previous command, except that it doesn’t change the branch’s HEAD, and instead only changes the working tree.
Some simple concepts to grasp:
If a commit has multiple parents, it’s a merge commit.
If a commit has multiple children, it represents the ancestor of a branch.
Simply put, Git is a collection of commits, each of which holds a tree which reference other trees and blobs, which store data.
All other things in Git are named concepts but they all boil down to the above statement.
A commit by any other name
The key to knowing Git is to truly understand commits.
Learning to name your commits is the way to mastering Git.
branchname – The name of a branch is an alias to the most recent commit on that branch.
tagname – Similar to the branch name in that the name points to a specific commit but the difference is a tag can never change the commit id it points to.
HEAD – The currently checked out commit. Checking out a specific commit takes you out of a “branch” and you are then in a “detached HEAD” state.
The 40 character hash id – A commit can always be referenced by the full SHA1 hash.
You can refer to a commit by a shorter version of the hash id, enough characters to make it unique, usually 6 or 7 characters is enough.
name^ – Using the caret tells Git to go to the parent of the provided commit. If a commit has more than one parent, the first one is chosen.
name^^ – Carets can be stacked, so doing two carets will give the parent of the parent of the provided commit.
name^2 – If a commit has multiple parents, you can choose which one to retrieve by using the caret followed by the number of the parent to retrieve. This is useful for things like merge commits.
name~10 – Same thing as using the commit plus 10 carets. It refers to the named commit’s 10th generation ancestor.
name:path – Used to reference a specific file in the commit’s content tree, excellent when you need to do things like compare file diffs in a merge, like: git diff HEAD^1:somefile HEAD^2:somefile.
name^{tree} – Reference the tree held by a commit rather than the commit itself.
name1..name2 – Get a range of commits reachable from name2 all the way back to, but not including, name1. Omitting name1 or name2 will substitute HEAD in the place.
name1…name2 – For commands like log, gets the unique commits that are referenced by name1 or name2. For commands like diff, the range is is between name2 and the common ancestor of name1 and name2.
main.. – Equivalent to main..HEAD and useful when comparing changes made in the current branch to the branch named main.
..main – Equivalent to HEAD..main and useful for comparing changes since the last rebase or merge with the branch main, after fetching it.
-since=”2 weeks ago” – All commits from a certain relative date.
–until=”1 week ago” – All commits before a certain relative date.
–grep=pattern – All commits where the message meets a certain regex pattern.
–committer=pattern — Find all the commits where the committer matches a regex pattern.
–author=pattern – All commits whose author matches the pattern.
So how’s that different than the committer? “The author of a commit is the one who created the changes it represents. For local development this is always the same as the committer, but when patches are being sent by e-mail, the author and the committer usually differ.”
–no-merges – Only return commits with a single parent, i.e. ignore all merge commits.
Not sure where the history of your branch started from and want an easy button? Check out Allen’s TotW from episode 182.
Need to search the entire history of the repo for some content (text, code, etc.) that’s not part of the current branch? Content, not a commit comment, not a commit ID, but content. Check out Michael’s TotW from episode 31.
Nobody Likes Onions, a podcast that has been making audiences laugh at the absurd, the obvious, and the wrong, for a very long time. (NobodyLikesOnions.com)
Tip of the Week
Supabase is an open-source alternative to Google’s Firebase that is based on PostgreSQL. The docs are great and it’s really easy to work through the “Getting Started” guide to set up a new project in the top framework of your choice, complete with a (for now) free, hosted PostgreSQL database on Heroku, with authentication (email/password or a myriad of providers). RBAC is controlled via database policies and everything can be administered through the portal. You can query the database with a simple DSL. Joe was able to work through a small project and get it hosted on Netlify (with SSL!) all for free in under 2 hours. (supabase.com)
Obsidian is a really cool way to associate markdown data with your files. (Thanks Simon Barker!) (obsidian.md)
Ever use a “mind map” tool? MindNode is a great, free, mind mapping tool to help you organize your thoughts (Thanks Sean Martz!) (mindnode.com)
Ink Drop is a cool way to organize and search your markdown files (inkdrop.app) (Thanks Lars!)
Tired of git log knocking the rest of your content off screen? You can configure Git to run a custom “core.pager” command with the args you prefer: (serebrov.github.io)
To configure just Git: git config --global --replace-all core.pager "less -iXFR"
Or, to modify how less prints to the screen and commands that rely on it, including Git, edit your ~/.bashrc or ~/.zshrc, etc. and add export LESS=-iXFR to the file.
It’s surprising how little we know about Git as we continue to dive into Git from the Bottom Up, while Michael confuses himself, Joe has low standards, and Allen tells a joke.
Thanks for all the great feedback on the last episode and for sticking with us!
Directory Content Tracking
Put simply, Git just keeps a snapshot of a directory’s contents.
Git represents your file contents in blobs (binary large object), in a structure similar to a Unix directory, called a tree.
A blob is named by a SHA1 hashing of the size and contents of the file.
This verifies that the blob contents will never change (given the same ID).
The same contents will ALWAYS be represented by the same blob no matter where it appears, be it across commits, repositories, or even the Internet.
If multiple trees reference the same blob, it’s simply a hard link to the blob.
As long as there’s one link to a blob, it will continue to exist in the repository.
A blob stores no metadata about its content.
This is kept in the tree that contains the blob.
Interesting tidbit about this: you could have any number of files that are all named differently but have the same content and size and they’d all point to the same blob.
For example, even if one file were named abc.txt and another was named passwords.bin in separate directories, they’d point to the same blob.
The author creates a file and then calculates the ID of the file using git hash-object filename.
If you were to do the same thing on your system, assuming you used the same content as the author, you’d get the same hash ID, even if you name the file different than what they did.
git cat-file -t hashID will show you the Git type of the object, which should be blob.
git cat-file blob hashID will show you the contents of the file.
The commands above are looking at the data at the blob level, not even taking into account which commit contained it, or which tree it was in.
Git is all about blob management, as the blob is the fundamental data unit in Git.
Blobs are Stored in Trees
Remember there’s no metadata in the blobs, and instead the blobs are just about the file’s contents.
Git maintains the structure of the files within the repository in a tree by attaching blobs as leaf nodes within a tree.
git ls-tree HEAD will show the tree of the latest commit in the current directory.
git rev-parse HEAD decodes the HEAD into the commit ID it references.
git cat-file -t HEAD verifies the type for the alias HEAD (should be commit).
git cat-file commit HEAD will show metadata about the commit including the hash ID of the tree, as well as author info, commit message, etc.
To see that Git is maintaining its own set of information about the trees, commits and blobs, etc., use find .git/objects -type f and you’ll see the same IDs that were shown in the output from the previous Git commands.
How Trees are Made
There’s a notion of an index, which is what you use to initially create blobs out of files.
If you just do a git add without a commit, assuming you are following along here (jwiegly.github.io), git log will fail because nothing has been committed to the repository.
git ls-files --stage will show your blob being referenced by the index.
At this point the file is not referenced by a tree or a commit, it’s only in the .git/index file.
git write-tree will take the contents of the index and write it to a tree, and the tree will have it’s own hash ID.
If you followed along with the link above, you’d have the same hash from the write-tree that we get.
A tree containing the same blob and sub-trees will always have the same hash.
The low-level write-tree command is used to take the contents of the index and write them into a new tree in preparation for a commit.
git commit-tree takes a tree’s hash ID and makes a commit that holds it.
If you wanted that commit to reference a parent, you’d have to manually pass in the parent’s commit ID with the -p argument.
This commit ID will be different for everyone because it uses the name of the creator of the commit as well as the date when the commit is created to generate the hash ID.
Now you have to overwrite the contents of .git/refs/heads/master with the latest commit hash ID.
This tells Git that the branch named master should now reference the new commit.
A safer way to do this, if you were doing this low-level stuff, is to use git update-ref refs/heads/master hashID.
git symbolic-ref HEAD refs/heads/master then associates the working tree with the HEAD of master.
What Have We Learned?
Blobs are unique!
Blobs are held by Trees, Trees are held by Commits.
HEAD is a pointer to a particular commit.
Commits usually have a parent, i.e. previous, commit.
We’ve got a better understanding of the detached HEAD state.
What a lot of those files mean in the .git directory.
Resources We Like
Things I wish everyone knew about Git (Part 1) (blog.plover.com)
Have you ever heard the tale of … the forbidden files in Windows? Windows has a list of names that you cannot use for files. Twitter user @foone has done the unthinkable and created a repository of these files. What would happen if you checked this repository out on Windows?
Check out this convenient repository in Windows. (GitHub)
When you use mvn dependency:tree, grep is your enemy. If you want to find out who is bringing in a specific dependency, you really need to use the -Dincludes flag.
Thanks to @ttutko for this tip about redirecting output:
kafkacat 2>&1 | grep "". If you’re not familiar with that syntax, it just means pipe STDERR to STDOUT and then pipe that to grep.
Thanks Volkmar Rigo for this one!
Dangit, Git!? Git is hard: messing up is easy, and figuring out how to fix your mistakes is impossible. This website has some tips to get you out of a jam. (DangitGit.com)
How to vacay … step 1 temporarily disable your work email (and silence Slack, Gchat, whateves).
On iOS, go to Settings -> Mail -> Accounts -> Select your work account -> Turn off the Mail slider.
After working with Git for over a decade, we decide to take a deep dive into how it works, while Michael, Allen, and Joe apparently still don’t understand Git.
This is the book Outlaw was trying to remember … we think!
How to approach Git; general strategy
This episode was inspired by an article written by Mark Dominus.
Git commits are immutable snapshots of the repository.
Branches are named sequences of commits.
Every object gets a unique id based on its content.
The author is not a fan of how the command set has evolved over time.
With Git, you need to think about what state your repository is in, and what state you would like to be in.
There are likely a number of ways to achieve that desired state.
If you try to understand the commands without understanding the model, you can get lost. For example:
git reset does three different things depending on the flags used,
git checkout even worse (per the author), and
The opposite of git-push is not git-pull, it’s git-fetch.
Possibly the worst part of the above is if you don’t understand the model and what’s happening to the model, you won’t know the right questions to ask to get back into a good state.
Mark said the thing that saved him from frustration with Git is the book Git from the Bottom Up by John Wiegley (jwiegley.github.io)
Mark doesn’t love Git, but he uses it by choice and he uses it effectively. He said that reading Wiegley’s book is what changed everything for him. He could now “see” what was happening with the model even when things went wrong.
It is very hard to permanently lose work. If something seems to have gone wrong, don’t panic. Remain calm and ask an expert.
Mark Dominus
Git from the Bottom Up
A repository – “is a collection of commits, each of which is an archive of what the project’s working tree looked like at a past date, whether on your machine or someone else’s.” It defines HEAD, which identifies the branch or commit the current tree started from, and contains a set of branches or tags that allow you to identify commits by a name.
The index is what will be committed on the next commit. Git does not commit changes from the working tree into the repository directly so instead, the changes are registered into the index, which is also referred to as a staging area, before committing the actual changes.
A working tree is any directory on your system that is associated with a Git repository and typically has a .git folder inside it.
Why typically? Thanks to the git-worktree command, one .git directory can be used to support multiple working trees, as previously discussed in episode 128.
A commit is a snapshot of your working tree at some point in time. “The state of HEAD (see below) at the time your commit is made becomes that commit’s parent. This is what creates the notion of a ‘revision history’.”
A branch is a name for a commit, also called a reference. This stores the history of commits, the lineage and is typically referred to as the “branch of development”
A tag is also a name for a commit, except that it always points to the same commit unlike a branch which doesn’t have to follow this rule as new commits can be made to the branch. A tag can also have its own description text.
master was typically, maybe not so much now, the default branch name where development is done in a repository. Any branch name can be configured as the default branch. Currently, popular default branch names include main, trunk, and dev.
HEAD is an alias that lets the repository identify what’s currently checked out. If you checkout a branch, HEAD now symbolically points to that branch. If you checkout a tag, HEAD now refers only to that commit and this state is referred to as a “detached HEAD“.
The typical work flow goes something like:
Create a repository,
Do some work in your working tree,
Once you’ve achieved a good “stopping point”, you add your changes to the index via git add, and then
Once your changes are in the state you want them and in your index, you are ready to put your changes into the actual repository, so you commit them using git commit.
Resources We Like
Things I wish everyone knew about Git (Part 1) (blog.plover.com)
Designing Data-Intensive Applications – SSTables and LSM-Trees (episode 128)
Celeste is quite a game, it’s challenging but rewarding…or accessible and rewarding. Just go play it already!
Tip of the Week
Celeste is a tough, but forgiving game that is on all major platforms. It was developed by a tiny team, 2 programmers, and it’s a really rewarding and interesting experience. Don’t sleep on this game any longer! (CelesteGame.com)
Enforcer Maven plugin is a tool for unknotting dependency version problems, which can easily get out of control and be a real problem when trying to upgrade!
Maven Enforcer Plugin – The Loving Iron Fist of MavenTM (maven.apache.org)
Tired of sending messages too early in Slack? You can set your Slack preferences to make ENTER just do a new line! Then use CMD + ENTER on MacOS or CTRL + ENTER on Windows to send the message! Thanks for the amazing tip from Jim Humelsine! (Slack)
Using Docker Desktop, and want to run a specific version? Well … you can’t really! You have to pick a version of Docker Desktop that corresponds to your target version of Kubernetes!
Alternatively you can just use Minikube to target a specific Kubernetes version (minikube.sigs.k8s.io)
Save a life, donate blood, platelets, plasma, or marrow (redcrossblood.org)
What if you want to donate blood marrow or cord blood? You need to be matched with a recipient first. Check eligibility on the website at Be The Match. (bethematch.org)
Also, not quite as important, you can disable all of the stupid sounds (bells) in WSL!
Disable beep in WSL terminal on Windows 10 (Stack Overflow)
Once again, Stack Overflow takes the pulse of the developer community where we have all collectively decided to switch to Clojure, while Michael is changing things up, Joe is a future predicting trailblazer, and Allen is “up in the books”.
Joe’s going to be speaking at the Orlando Elastic Meetup about running Elasticsearch in Kubernetes on July 27th 2022 (Meetup)
Recommendation, keep your API interface in separate modules from your implementation! That makes it easier to re-use that code in new ways without having to refactor first.
Do you worry about talking too much in virtual meetings? This app monitors your mic and lets you know when you’re waffling on. (unblah.me)
Did you know you can do a regex search in grep? Example: grep -Pzo "(?s)^(\s)\Nmain.?{.?^\1}" *.c (Stack Overflow)
But what if you want to do that in vim? By default vim treats characters literally, but you can turn on “magic” characters with :set magic and then you’re off to the races! (Stack Overflow)
Looking for some great IntelliJ Code Completion Tips? Check out this video! (YouTube)
Did you know yum install will not return an error code when installing multiple packages at the same time if one succeeds and another fails. Yikes! So be sure to install your dependencies independent of their dependents. (Stack Overflow)
We’re going back in time, or is it forward?, as we continue learning about Google’s automation evolution, while Allen doesn’t like certain beers, Joe is a Zacker™, and Michael poorly assumes that UPSes work best when plugged in.
A cautionary, err, educational tale of automating MySQL for Ads and automating replica replacements.
Migrating MySQL to Borg (Google Cluster Manager)
Large-scale cluster management at Google with Borg (research.google)
Desired goals of the project:
Eliminate machine/replica maintenance,
Ability to run multiple instances on same machine.
Came with additional complications – Borg task moving caused problems for master database servers.
Manual failovers took a long time.
Human involvement in the failovers would take longer than the required 30 seconds or less downtime.
Led to automating failover and the birth of MoB (MySQL on Borg).
Again, more problems because now application code needed to become much more failure tolerant.
After all this, mundane tasks dropped by 95%, and with that they were able to optimize and automate other things causing total operational costs to drop by 95% as well.
Automating Cluster Delivery
Story about a particular setup of Bigtable that didn’t use the first disk of a 12 disk cluster.
Some automation thought that if the first disk wasn’t being utilized, then none of the disks weren’t configured and were safe to be wiped.
Automation should be careful about implicit “safety” signals.
Cluster delivery automation depended on a lot of bespoke shell scripts which turned out to be problematic over time.
Detecting Inconsistencies with ProdTest
ProdTest contained chained “unit” tests that would figure out where problems began
Cluster automations required custom flags, which led to constant problems / misconfigurations.
Shell scripts became brittle over time.
Were all the services available and configured properly?
Were the packages and configurations consistent with other deployments?
Could configuration exceptions be verified?
For this, ProdTest was created.
Tests could be chained to other tests and failures in one would abort causing subsequent tests to not run.
The tests would show where something failed and with a detailed report of why.
If something new failed, they could be added as new tests to help quickly identify them in the future.
These tools gave visibility into what was causing problems with cluster deployments.
While the finding of things quicker was nice, that didn’t mean faster fixes. Dozens of teams with many shell scripts meant that fixing these things could be a problem.
The solution was to pair misconfigurations with automated fixes that were idempotent
This sounded good but in reality some fixes were flaky and not truly idempotent and would cause the state to be “off” and other tests would now start failing.
There was also too much latency between a failure, the fix, and another run.
Specializing
Automation processes can vary in one of three ways:
Competence,
Latency,
Relevance: the proportion of real world processes covered by automation.
They attempted to use “turnup” teams that would focus on automation tasks, i.e. teams of people in the same room. This would help get things done quicker.
This was short-lived.
Could have been over a thousand changes a day to running systems!
When the automation code wasn’t staying in sync with the code it was covering, that would cause even more problems. This is the real world. Underlying systems change quickly and if the automation handling those systems isn’t kept up, then more problems crop up.
This created some ugly side effects by relieving teams who ran services of the responsibility to maintain and run their automation code, which created ugly organizational incentives:
A team whose primary task is to speed up the current turnup has no incentive to reduce the technical debt of the service-owning team running the service in production later.
A team not running automation has no incentive to build systems that are easy to automate.
A product manager whose schedule is not affected by low-quality automation will always prioritize new features over simplicity and automation.
Turnups became inaccurate, high-latency, and incompetent.
They were saved by security by the removal of SSH approaches to more auditable / less-privileged approaches.
Service Oriented Cluster Turnup
Changed from writing shell scripts to RPC servers with fine-grained ACL (access control lists).
Service owners would then create / own the admin servers that would know how their services operated and when they were ready.
These RPC’s would send more RPC’s to admin server’s when their ready state was reached.
This resulted in low-latency, competent, and accurate processes.
Autonomous systems that need no human intervention”
Borg: Birth of the Warehouse-Scale Computer
In the early days, Google’s clusters were racks of machines with specific purposes.
Developers would log into machines to perform tasks, like delivering “golden” binaries.
As Google grew, so did the number and type of clusters. Eventually machines started getting a descriptor file so developers could act on types of machines.
Automation eventually evolved to storing the state of machines in a proper database, with sophisticated monitoring tools.
This automation was severely limited by being tied to physical machines with physical volumes, network connections, IP addresses, etc.
Borg let Google orchestrate at the resource level, allocating compute dynamically. Suddenly one physical computer could have multiple types of workloads running on it.
This let Google centralize it’s logic, making it easier to make systemic changes that improve efficiency, flexibility, and reliability.
This allowed Google to greatly scale it’s resources without scaling it’s labor.
Thousands of machines are born, die, and go into repair daily without any developer interaction.
They effectively turned a hardware problem into a software problem, which allowed them to take advantage of well known techniques and algorithms for scheduling processes.
This couldn’t have happened if the system wasn’t self-healing. Systems can’t grow past a certain point without this.
Reliability is the Fundamental Feature
Internal operations that automation relies on needs to be exposed to the people as well.
As systems become more and more automated, the ability for people to reason about the system deteriorates due to lack of involvement and practice.
They say that the above is true when systems are non-autonomous, i.e. the manual actions that were automated are assumed to be able to be done manually still, but doesn’t reflect the current reality.
While Google has to automate due to scale, there is still a benefit for software / systems that aren’t that at their scale and this is reliability. Reliability is the ultimate benefit to automation.
Automation also speeds processes up.
Best to start thinking about automation in the design phase as it’s difficult to retrofit.
Beware – Enabling Failure at Scale
Story about automation that wiped out almost all the machines on a CDN because when they re-ran the process to do a Diskerase, it found that there were no machines to wipe, but the automation then saw the “empty set” as meaning, wipe everything.
This caused the team to build in more sanity checks and some rate limiting!
Resources We Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Apple’s Self Service Repair now available (apple.com)
Tip of the Week
Jetbrains makes it easy to log values at debug time!
kubectl debug is a useful utility command that helps you debug issues. Here are a couple examples from the docs using kubectl debug (kubernetes.io)
Adding ephemeral debug containers to pods,
Copying existing pods and add additional containers,
Debugging pending pods,
Pods that immediately fail.
The Kubernetes docs feature a lot of nice tips for debugging (kubernetes.io)
Did you know that JetBrains makes it easy to add logging while you’re debugging? Just highlight the code you want to log the value of, then SHIFT-CLICK the gutter to set a logging point during debugging!
Want to copy a file out of an image, without running it? You can’t, however you can create a non-running container that will spin up a lite/idle container that will do the job. Just make sure to rm it when you’re done. Notice how helpful it was for later commands to name the container when it was created! Here’s an example workflow to copy out some.file. (docs.docker.com)
We explore the evolution of automation as we continue studying Google’s Site Reliability Engineering, while Michael, ah, forget it, Joe almost said it correctly, and Allen fell for it.
rupeshbende asks: How do you find time to do this along with your day job and hobbies as this involves so much studying on your part?
Survey Says
Automation
Why Do We Automate Things?
The famous “SRE Book” from Google
Consistency: Humans make mistakes, even on simple tasks. Machines are much more reliable. Besides, tasks like creating accounts, resetting passwords, applying updates aren’t exactly fun.
Platform: Automation begets automation, smaller tasks can be tweaked or combined into bigger ones.
Pays dividends, providing value every time it’s used as opposed to toil which is essentially a tax.
Platforms centralize logic too, making it easier to organize, find, and fix issues.
Automation can provide metrics, measurements that can be used to make better decisions.
Faster Repairs: The more often automation runs, it hits the same problems and solutions which brings down the average time to fix. The more often the process runs, the cheaper it becomes to repair.
Faster Actions: Automations are faster than humans. Many automations would be prohibitively expensive for humans to do,
Time Saving: It’s faster in terms of actions, and anybody can run it.
If we are engineering processes and solutions that are not automatable, we continue having to staff humans to maintain the system. If we have to staff humans to do the work, we are feeding the machines with the blood, sweat, and tears of human beings. Think The Matrix with less special effects and more pissed off System Administrators.
Joseph Bironas
The Value of SRE at Google
Google has a strong bias for automation because of their scale.
Google’s core is software, and they don’t want to use software where they don’t own the code and they don’t want processes in place that aren’t automated. You can’t scale tribal knowledge.
They invest in platforms, i.e. systems that can be improved and extended over time.
Google’s Use Cases for Automation
Much of Google’s automation is around managing the lifecycle of systems, not their data.
They use tools such as chef, puppet, cfengine, and PERL(!?).
The trick is getting the right level of abstraction.
Higher level abstractions are easier to work with and reason about, but are “leaky”.
Hard to account for things like partial failures, partial rollbacks, timeouts, etc.
The more generic a solution, the easier it is to apply more generally and tend to be more reusable, but the downside is that you lose flexibility and resolution.
The Use Cases for Automation
Google’s broad definition of automation is “meta-software”: software that controls software.
Examples:
Account creation, termination,
Cluster setup, shutdown,
Software install and removal,
Software upgrades,
Configuration changes, and
Dependency changes
A Hierarchy of Automation Classes
Ideally you wouldn’t need to stitch systems together to get them to work together.
Systems that are separate, and glue code can suffer from “bit rot”, i.e. changes to either system can work poorly with each other or with the havoc.
Glue code is some of the hardest to test and maintain.
There are levels of maturity in a system. The more rare and risky a task is, the less likely it is to be fully automated.
Maturity Model
When your levels of abstraction get to be very sophisticated, you can lose the ability to work effectively at a lower level. Kind of like trying to make your own toaster today (Gizmodo).
No automation: database failover to a new location manually.
Externally maintained system-specific automations: SRE has a couple commands they run in their notes.
Externally maintained generic system-specific automation: SRE adds a script to a playbook.
Internally maintained system-specific automation: the database ships with a script.
System doesn’t need automation: Database notices and automatically fails over.
Can you automate so much that developers are unable to manually support systems when a (very rare) need occurs?
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Chapter 7: The Evolution of Automation at Google (sre.google)
Ultimate List of Programmer Jokes, Puns, and other Funnies (Medium)
Shared success in building a safer open source community (blog.google)
One Man’s Nearly Impossible Quest to Make a Toaster From Scratch (Gizmodo)
The Man Who Spent 17 Years Building The Ultimate Lamborghini Replica In His Basement Wants to Sell It (Jalopnik)
Tip of the Week
There’s an easy way to seeing Mongo queries that are running in your Spring app, by just setting the appropriate logging level like: logging.level.org.springframework.data.mongodb.core.MongoTemplate=DEBUG
This can be easily done at runtime if you have actuators enabled: (Spring)
There’s a new, open-core product from Grafana called OnCall that helps you manage production support. Might be really interesting if you’re already invested in Grafana and a lot of organizations are invested in Grafana. (Grafana)
How can you configure your Docker container to run as a restricted user? It’s easy! (docs.docker.com)
User <user>[:<group>]
User <UID>[:<GID>]
iOS – Remember the days of being about to rearrange your screens in iTunes? Turns out you still can, but in iOS. Tap and hold the dots to rearrange them! (support.apple.com)
We finished. A chapter, that is, of the Site Reliability Engineering book as Allen asks to make it weird, Joe has his own pronunciation, and Michael follows through on his promise.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Another great post from @msuriar, this time about the value of hiring junior developers. (suriar.net)
Survey Says
More about Monitoring Less
The famous “SRE Book” from Google
Instrumentation and Performance
Need to be careful and not just track times, such as latencies, on medians or means.
A better way is to bucketize the data as a histogram, meaning to count how many instances of a request occurred in the given bucket, such as the example latency buckets in the book of 0ms – 10ms, 10ms – 30ms, 30ms-100ms, etc.
Choosing the Appropriate Resolution for Measurements
The gist is that you should measure at intervals that support the SLO’s and SLA’s.
For example, if you’re targeting a 99.9% uptime, there’s no reason to check for hard-drive fullness more than once or twice a minute.
Collecting measurements can be expensive, for both storage and analysis.
Best to take an approach like the histogram and keep counts in buckets and aggregate the findings, maybe per minute.
As Simple as Possible, No Simpler
It’s easy for monitoring to become very complex:
Alerting on varying thresholds and measurements,
Code to detect possible causes,
Dashboards, etc.
Monitoring can become so complex that it becomes difficult to change, maintain, and it becomes fragile.
Some guidelines to follow to keep your monitoring useful and simple include:
Rules that find incidents should be simple, predictable and reliable,
Data collection, aggregation and alerting that is infrequently used (the book said less than once a quarter) should be a candidate for the chopping block, and
Data that is collected but not used in any dashboards or alerting should be considered for deletion.
Avoid attempting to pair simple monitoring with other things such as crash detection, log analysis, etc. as this makes for overly complex systems.
Tying these Principles Together
Google’s monitoring philosophy is admittedly maybe hard to attain but a good foundation for goals.
Ask the following questions to avoid pager duty burnout and false alerts:
Does the rule detect something that is urgent, actionable and visible by a user?
Will I ever be able to ignore this alert and how can I avoid ignoring the alert?
Does this alert definitely indicate negatively impacted users and are there cases that should be filtered out due to any number of circumstances?
Can I take action on the alert and does it need to be done now and can the action be automated? Will the action be a short-term or long-term fix?
Are other people getting paged about this same incident, meaning this is redundant and unnecessary?
Those questions reflect these notions on pages and pagers:
Pages are extremely fatiguing and people can only handle a few a day, so they need to be urgent.
Every page should be actionable.
If a page doesn’t require human interaction or thought, it shouldn’t be a page.
Pages should be about novel events that have never occurred before.
It’s not important whether the alert came from white-box or black-box monitoring.
It’s more important to spend effort on catching the symptoms over the causes and only detect imminent causes.
Monitoring for the Long Term
Monitoring systems are tracking ever-changing software systems, so decisions about it need to be made with long term in mind.
Sometimes, short-term fixes are important to get past acute problems and buy you time to put together a long term fix.
Two case studies that demonstrate the tension between short and long term fixes
Bigtable SRE
Originally Bigtable’s SLO was based on an artificial, good client’s mean performance.
Bigtable had some low level problems in storage that caused the worst 5% of requests to be significantly slower than the rest.
These slow requests would trip alerts but ultimately the problems were transient and unactionable.
People learned to de-prioritize these alerts, which sometimes were masking legitimate problems.
Google SRE’s temporarily dialed back the SLO to the 75th percentile to trigger fewer alerts and disabled email alerts, while working on the root cause, fixing the storage problems.
By slowing the alerts it gave engineers the breathing room they needed to deep dive the problem.
Gmail
Gmail was originally built on a distributed process management system called Workqueue which was adapted to long-lived processes.
Tasks would get de-scheduled causing alerts, but the tasks only affected a very small number of users.
The root cause bugs were difficult to fix because ultimately the underlying system was a poor fit.
Engineers could “fix” the scheduler by manually interacting with it (imagine restarting a server every 24 hours).
Should the team automate the manual fix, or would this just stall out what should be the real fix?
These are 2 red flags: Why have rote tasks for engineers to perform? That’s toil. Why doesn’t the team trust itself to fix the root cause just because an alarm isn’t blaring?
What’s the takeaway? Do not think about alerts in isolation. You must consider them in the context of the entire system and make decisions that are good for the long term health of the entire system.
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Python has built in functionality for dynamically reloading modules: Reloading modules in Python. (GeeksForGeeks)
Dockerfile tips-n-tricks:
Concatenate RUN statements like RUN some_command && some_other_command instead of splitting it out into two separate RUN command strings to reduce the layer count.
Prefer apk add --no-cache some_package over apk update && apk add some_package to reduce the layer and image size. And if you’re using apt-get instead of apk, be sure to include apt-get clean as the final command in the RUN command string to keep the layer small.
When using ADD and COPY, be aware that Docker will need the file(s)/directory in order to compute the checksum to know if a cached layer already exists. This means that while you can ADD some_url, Docker needs to download the file in order to compute the checksum. Instead, use curl or wget in a RUN statement when possible, because Docker will only compute the checksum of the RUN command string before executing it. This means you can avoid unnecessarily downloading files during builds (especially on a build server and especially for large files). (docs.docker.com)
We haven’t finished the Site Reliability Engineering book yet as we learn how to monitor our system while the deals at Costco as so good, Allen thinks they’re fake, Joe hasn’t attended a math class in a while, and Michael never had AOL.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
News
Thank you for the reviews! just_Bri, 1234556677888999900000, Mannc, good beer hunter
Post-Incident Review on the Atlassian April 2022 outage (Atlassian)
Great episode on All The Code featuring Brandon Lyons and his journey to Microsoft. (ListenNotes.com)
Couldn’t resist posting this:
Survey Says
Monitor Some of the Things
Terminology
Monitoring – Collecting, processing, and aggregating quantitative information about a system.
White-box monitoring – Monitoring based on metrics exposed by a system, i.e. logs, JVM profiling, etc.
Black-box monitoring – Monitoring a system as a user would see it.
Dashboard – Provides a summary view of the most important service metrics. May display team information, ticket queue size, high priority bugs, current on call engineer, recent pushes, etc.
Alert – Notification intended to be read by a human, such as tickets, email alerts, pages, etc.
Root cause – A defect, that if corrected, creates a high confidence level that the same issue won’t be seen again. There can be multiple root causes for a particular incident (including a lack of testing!)
Node and machine – A single instance of a running kernel.
Kernel – The core of the operating system. Generally controls everything on the system, always resident in memory, and facilitates interactions between the system hardware and software. (Wikipedia)
There could be multiple services worth monitoring on the same node that could be either related or unrelated.
Push – Any change to a running service or it’s configuration.
Why Monitor?
The famous “SRE Book” from Google
Some of the main reasons include:
To analyze trends,
To compare changes over time, and
Alerting when there’s a problem.
To build dashboards to answer basic questions.
Ad hoc analysis when things change to identify what may have caused it.
Monitoring lets you know when the system is broken or may be about to break.
You should never alert just if something seems off.
Paging a human is an expensive use of time.
Too many pages may be seen as noise and reduce the likelihood of thorough investigation.
Effective alerting systems have good signal and very low noise.
Setting Reasonable Expectations for Monitoring
Monitoring complex systems is a major undertaking.
The book mentions that Google SRE teams with 10-12 members have one or two people focused on building and maintaining their monitoring systems for their service.
They’ve reduced the headcount needed for maintaining these systems as they’ve centralized and generalized their monitoring systems, but there’s still at least one human dedicated to the monitoring system.
They also ensure that it’s not a requirement that an SRE stare at the screen to identify when a problem comes up.
Google has since moved to simpler and faster monitoring systems that provide better tools for ad hoc analysis and avoid systems that try to determine causality
This doesn’t mean they don’t monitor for major changes in common trends.
SRE’s at Google seldom use tiered rule triggering.
Why? Because they’re constantly changing their service and/or infrastructure.
When they do alert on these dependent types of rules, it’s when there’s a common task that’s carried out that is relatively simple.
It is critical that from the instant a production issue arises, that the monitoring system alert a human quickly, and provide an easy to follow process that people can use to find the root cause quickly.
Alerts need to be simple to understand and represent the failure clearly.
Symptoms vs Causes
A monitoring system should answer these two questions:
What is broken? This is the symptom.
Why is it broken? This is the cause.
The book says that drawing the line between the what and why is one of the most important ways to make a good monitoring system with high quality signals and low noise.
An example might be:
Symptom: The web server is returning 500s or 404s,
Cause: The database server ran out of hard-drive space.
Black-Box vs White-Box
Google SRE’s use white-box monitoring heavily, and much less black-box monitoring except for critical uses.
White-box monitoring relies on inspecting the internals of a system.
Black-box monitoring is symptom oriented and helps identify unplanned issues.
Interesting takeaway for the white-box monitoring is this exposes issues that may be hidden by things like retries.
A symptom for one team can be a cause for another.
White-box monitoring is crucial for telemetry.
Example: The website thinks the database is slow, but does the database think itself is slow? If not, there may be a network issue.
Benefit of black-box monitoring for alerting is black-box monitoring indicates a problem that is currently happening, but is basically useless in letting you know that a problem may happen.
Four Golden Signals
Latency – The time it takes to service a request.
Important to separate successful request latency vs failed request latency.
A slow error is worse than a fast error!
Traffic – How much demand is being placed on your system, such as requests per second for a web request, or for streaming audio/video, it might be I/O throughput.
Errors – The rate of requests that fail, either explicitly or implicitly.
Explicit errors are things like a 500 HTTP response.
Implicit might be any request that took over 2 seconds to finish if your goal is to respond in less than 2 seconds.
Saturation – How full your service is.
A measure of resources that are the most constrained, such as CPU or I/O, but note that things usually start to degrade before 100% utilization.
This is why having a utilization target is important.
Latency increases are often indicators of saturation.
Measuring 99% response time over a small interval can be an early signal of saturation.
Saturation also concerns itself when predicting imminent issues, like filling up drive space, etc.
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Post-Incident Review on the Atlassian April 2022 outage (Atlassian)
Great episode on All The Code featuring Brandon Lyons and his journey to Microsoft. (ListenNotes.com)
Tip of the Week
Prometheus has configurations that let you tune how often it looks for metrics, i.e. the scrape_interval. Too much and you’re wasting resources, not enough and you can miss important information and get false alerts. (Prometheus)
There’s a reason WordPress is so popular. It’s fast and easy to setup, especially if you use Webinonly. (Webinonly.com)
Looking for great encryption libraries for Java or PHP? Check out Bouncy Castle! (Bouncy Castle)
Big thanks to @bicylerepairmain for the tip on the running lines of code in VS Code with a keyboard shortcut. The option workbench.action.terminal.runSelectedText is under File -> Preferences -> Keyboard Shortcuts. (Stack Overflow)
Need to see all of the files you’ve changed since you branched off of a commit? Use git diff --name-only COMMIT_ID_SHA HEAD. (git-scm.com)
Couple with Allen’s tip from episode 182 to make it easier to find that starting point!
We say “toil” a lot this episode while Joe saw a movie, Michael says something controversial, and Allen’s tip is to figure it out yourself, all while learning how to eliminate toil.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Reviews
Thank you for the reviews! AA, Franklin MacDunnaduex, BillyVL, DOM3ag3
Toil is not just work you don’t wanna do, nor is it just administrative work or tedious tasks.
Toil is different for every individual.
Some administrative work has to be done and is not considered toil but rather it’s overhead.
HR needs, trainings, meetings, etc.
Even some tedious tasks that pay long term dividends cannot be considered toil.
Cleaning up service configurations was an example of this.
Toil further defined is work that is often times manual, repetitive, can be automated, has no real value, and/or grows as the service does.
Manual – Something a human has to do.
Repetitive – Running something once or twice isn’t toil. Having to do it frequently is.
Automatable – If a machine can do it, then it should be done by the machine. If the task needs human judgement, it’s likely not toil.
Tactical – Interrupt driven rather than strategy driven. May never be able to eliminate completely but the goal is to minimize this type of work.
No enduring value – If your service didn’t change state after the task was completed, it was likely toil. If there was a permanent improvement in the state of the service then it likely wasn’t toil.
O(n) with service growth – If the amount of work grows with the growth of your service usage, then it’s likely toil.
Why is Less Toil Better?
At Google, the goal is to keep each SRE’s toil at less than 50%.
The other 50% should be developing solutions to reduce toil further, or make new features for a service.
Where features mean improving reliability, performance, or utilization.
The goal is set at 50% because it can easily grow to 100% of an SRE’s time if not addressed.
The time spent reducing toil is the “engineering” in the SRE title.
This engineering time is what allows the service to scale with less time required by an SRE to keep it running properly and efficiently.
When Google hires an SRE, they promise that they don’t run a typical ops organization and mention the 50% rule. This is done to help ensure the group doesn’t turn into a full time ops team.
Calculating Toil
The book gave the example of a 6 person team and a 6 week cycle:
Assuming 1 week of primary on-call time and 1 week of secondary on-call time, that means an SRE has 2 of 6 weeks with “interrupt” type of work, or toil, meaning 33% is the lower bound of toil.
With an 8 person team, you move to an 8 week cycle, so 2 weeks on call out of 8 weeks mean a 25% toil lower bound.
At Google, SRE’s report their toil is spent most on interrupts (non-urgent, service related messages), then on-call urgent responses, then releases and pushes.
Surveys at Google with SRE’s indicate that the average time spent in toil is closer to 33%.
Like all averages, it leaves out outliers, such as people who spend 0 time toiling, and others who spend as much as 80% of their time on toil.
If there is someone taking on too much toil, it’s up to the manage to spread that out better.
What Qualifies as Engineering?
Work that requires human judgement,
Produces permanent improvements in a service and requires strategy,
Design driven approach, and
The more generic or general, the better as it may be applied to multiple services to get even greater gains in efficiency and reliability.
Typical SRE Activities
Software engineering – Involves writing or modifying code.
Systems engineering – Configuring systems, modifying configurations, or documenting systems that provide long term improvements.
Toil – Work that is necessary to run a service but is manual, repetitive, etc.
Overhead – Administrative work not directly tied to a service such as hiring, HR paperwork, meetings, peer-reviews, training, etc.
The 50% goal is over a few quarters or year. There may be some quarters where toil goes above 50%, but that should not be sustained. If it is, management needs to step in and figure out how to bring that back into the goal range.
“Let’s invent more, and toil less”
Site Reliability Engineering: How Google Runs Production Systems
Is Toil Always Bad?
The fact that some amount of toil is predictable and repeatable makes some individuals feel like they’re accomplishing something, i.e. quick wins that may be low risk and low stress.
Some amount of toil is expected and unavoidable.
When the amount of time spent on toil becomes too large, you should be concerned and “complain loudly”.
Potential issues with large amounts of toil:
Career stagnation – If you’re not spending enough time on projects, your career progression will suffer.
Low morale – Too much toil leads to burnout, boredom, and being discontent.
Too much time on toil also hurts the SRE team.
Creates confusion – The SRE team is supposed to do engineering, and if that’s not happening, then the goal of the team doesn’t match the work being done by the team.
Slows progress – The team will be less productive if they’re focused on toil.
Sets precedent – If you take on too much toil regularly, others will give you more.
Promotes attrition – If your group takes on too much toil, talented engineers in the group may leave for a position with more development opportunities.
Causes breach of faith – If someone joins the team but doesn’t get to do engineering, they’ll feel like they were sold a bill of goods.
Commit to cleaning up a bit more toil each week with engineering activities.
Resources We Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
The Greatest Inheritance, uh stars Jaleel White (IMDb)
Clean Code – How to Write Amazing Unit Tests (episode 54)
DevOps Vs SRE: Enabling Efficiency And Resiliency (harness.io)
Tip of the Week
Pandas is a great tool for data analysis. It’s fast, flexible and easy to use. Easy to work with information from GCS buckets. (pandas.pydata.org)
7 GUIs you can build to study graphical user interface design. Start with a counter and build up to recreating Excel, programming language agnostic! (eugenkiss.github.io)
Did you know there’s a bash util for sorting, i.e. sort? (manpages.ubuntu.com)
Using Minikube? Did you know you can transfer images with minikube image save from your Minikube environment to Docker easily? Useful for running things in a variety of ways. (minikube.sigs.k8s.io)
Ever have a multi-stage docker, where you only wanted to build one of the intermediary stages? Great for debugging as well as part of your caching strategy, use docker build --target <stage name> to build those intermediary stages. (docs.docker.com)
Welcome to the morning edition of Coding Blocks as we dive into what service level indicators, objectives, and agreements are while Michael clearly needs more sleep, Allen doesn’t know how web pages work anymore, and Joe isn’t allowed to beg.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Survey Says
News
Monolithic repos … meh. But monolithic builds … oh noes.
Chapter 4: Service Level Objectives
The famous “SRE Book” from Google
Service Level Indicators
A very well and carefully defined metric of some aspect of the service or system.
Response latency, error rate, system throughput are common SLIs.
SLIs are typically aggregated over some predefined period of time.
Usually, SLIs directly measure some aspect of a system but it’s not always possible, as with client side latency.
Availability is one of the most important SLIs often expressed as a ratio of the number of requests that succeed, sometimes called yield.
For storage purposes, durability, i.e. the retention of the data over time, is important.
Service Level Objectives
The SLO is the range of values that you want to achieve with your SLIs.
Choosing SLOs can be difficult. For one, you may not have any say in it!
An example of an SLO would be for response latency to be less than 250ms.
Often one SLI can impact another. For instance, if your number of requests per second rises sharply, so might your latency.
It is important to define SLOs so that users of the system have a realistic understanding of what the availability or reliability of the system is. This eliminates arbitrary “the system is slow” or the “system is unreliable” comments.
Google provided an example of a system called Chubby that is used extensively within Google where teams built systems on top of Chubby assuming that it was highly available, but no claim was made to that end.
Sort of crazy, but to ensure service owners didn’t have unrealistic expectations on the Chubby’s up-time, they actually force downtime through the quarter.
Service Level Agreements
These are the agreements of what is to happen if/when the SLOs aren’t met.
If there is no consequence, then you’re likely talking about an SLO and not an SLA.
Typically, SLA’s consequences are monetary, i.e. there will be a credit to your bill if some service doesn’t meet it’s SLO.
SLAs are typically decided by the business, but SREs help in making sure SLO consequences don’t get triggered.
SREs also help come up with objective ways to measure the SLOs.
Google search doesn’t have an SLA, even though Google has a very large stake in ensuring search is always working.
However, Google for Work does have SLAs with its business customers.
What Should You Care About?
You should not use every metric you can find as SLIs.
Too many and it’s just noisy and hard to know what’s important to look at.
Too few and you may have gaps in understanding the system reliability.
A handful of carefully selected metrics should be enough for your SLIs.
Some Examples
User facing services:
Availability – could the request be serviced,
Latency – how long did it take the request to be serviced, and
Throughput – how many requests were able to be serviced.
Storage systems:
Latency – how long did it take to read/write,
Availability – was it available when it was requested, and
Durability – is the data still there when needed.
Big data systems:
Throughput – how much data is being processed, and
End to end latency – how long from ingestion to completion of processing.
Everything should care about correctness.
Collecting Indicators
Many metrics come from the server side.
Some metrics can be scraped from logs.
Don’t forget about client-side metric gathering as there might be some things that expose bad user experiences.
Example Google used is knowing what the latency before a page can be used is as it could be bad due to some JavaScript on the page.
Aggregation
Typically aggregate raw numbers/metrics but you have to be careful.
Aggregations can hide true system behavior.
Example given averaging requests per second: if odd seconds have 200 requests per second and even seconds have 0, then your average is 100 but what’s being hidden is your true burst rate of 200 requests.
Same thing with latencies, averaging latencies may paint a pretty picture but the long tail of latencies may be terrible for a handful of users.
Using distributions may be more effective at seeing the true story behind metrics.
In Prometheus, using a Summary metric uses quantiles so that you can see typical and worst case scenarios.
Quantile of 50% would show you the average request, while
Quantile of 99.99% would show you the worst request durations.
A really interesting takeaway here is that studies have shown that users prefer a system with low-variance but slower over a system with high variance but mostly faster.
In a low-variance system, SREs can focus on the 99% or 99.99% numbers, and if those are good, then everything else must be, too.
At Google, they prefer distributions over averages as they show the long-tail of data points, as mentioned earlier, averages can hide problems.
Also, don’t assume that data is distributed normally. You need to see the real results.
Another important point here is if you don’t truly understand the distribution of your data, your system may be taking actions that are wrong for the situation. For instance, if you think that you are seeing long latency times but you don’t realize that those latencies actually occur quite often, your systems may be restarting themselves prematurely.
Standardize some SLIs
This just means if you standardize on how, when, and what tools you use for gathering some of the metrics, you don’t have to convince or describe those metrics on every new service or project. Examples might include:
Aggregation intervals – distribution per minute, and
Frequency of metrics gathered – pick a time such as every 5 seconds, 10, etc.
Build reusable SLI templates so you don’t have to recreate the wheel every time.
Objectives in Practice
Find out what the users care about, not what you can measure!
If you choose what’s easy to measure, your SLOs may not be all that useful.
Defining Objectives
SLOs should define how they’re measured and what conditions make them valid.
Example of a good SLO definition – 99% of RPC calls averaged over one minute return in 100ms as measured across all back-end servers.
It is unrealistic to have your SLOs met 100%..
As we mentioned in the previous episode, striving for 100% takes time away from adding new features or makes your team design overly conservatively.
This is why you should operate with an error budget.
An error budget is just an SLO for meeting other SLOs!
Site Reliability Engineering: How Google Runs Production Systems
Choosing Targets
Don’t choose SLO targets based on current performance.
Keep the SLOs simple. Making them overly complex makes them hard to understand and may be difficult to see impacts of system changes.
Avoid absolutes like “can scale infinitely”. It’s likely not true, and if it is, that means you had to spend a lot of time designing it to be that way and is probably overkill.
Have as few SLOs as possible. You want just enough to be able to ensure you can track the status of your system and they should be defendable.
Perfection can wait. Start with loose targets that you can refine over time as you learn more.
SLOs should be a major driver in what SREs work on as they reflect what the business users care about
Control Measures
Kubernetes is great but … it’s complicated!
Monitor system SLIs.
Compare SLIs to SLOs and see if action is needed.
If action is needed, figure out what action should be taken.
Take the action.
Example that was given is if you see latency climbing, and it appears to be CPU bound, then increasing the CPU capacity should lower latencies and not trigger an SLO consequence.
SLOs Set Expectations
Publishing SLOs make it so users know what to expect.
You may want to use one of the following approaches:
Keep a safety margin by having a stricter internal SLO than the public facing SLO.
Don’t overachieve. If your performance is consistently better than your SLO, it might be worth introducing purposeful downtime to set user expectations more in line with the SLO, i.e. failure injection.
Agreements in Practice
The SRE’s role is to help those writing SLAs understand the likelihood or difficulty of meeting the SLOs/SLA being implemented.
You should be conservative in the SLOs and SLAs that you make publicly available.
These are very difficult to change once they’ve been made public.
SLAs are typically misused when actually talking about an SLO. SLA breaches may trigger a court case.
If you can’t win an argument about a particular SLO, it’s probably not worth having an SRE team work on it.
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
If you switch to a Mac and you’re struggling with the CMD / CTRL switch from Windows, look for driver software from the keyboard manufacturer as they likely have an option to swap the keys for you!
Metrics aren’t free! Be careful to watch your costs or you can get up to babillions quickly!
Did you know there is a file format you can use to import bookmarks? It’s really simple, just an HTML file. You can even use it for onboarding! (j11g.com)
Powerlevel10k is a Zsh theme that looks nice and is easy to configure, but it’s also good about caching your git status so it doesn’t bog down your computer trying to pull the status on every command, a must for Zsh users with large repos! (GitHub)
We learn how to embrace risk as we continue our learning about Site Reliability Engineering while Johnny Underwood talked too much, Joe shares a (scary) journey through his mind, and Michael, Reader of Names, ends the show on a dark note.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Survey Says
Reviews
Thanks for the help Richard Hopkins and JR! Want to help out the show? Leave us a review!
Sadly, O’Reilly is ending their partnership with ACM, so you’ll no longer get access to their Learning Platform if you’re a member. (news.ycombinator.com)
Chapter 3: Embracing Risk
Google aims for 100% reliability right? Wrong…
Increasing reliability is always better for the service, right? Not necessarily.
It’s very expensive to add another 9 of reliability, and
Can’t iterate on features as you spend more time and resources making the service more stable.
Users don’t typically notice the difference between very reliable and extremely reliable services.
The systems using these services usually aren’t 100% reliable, so the chances of noticing are very low.
SRE’s try to balance the risk of unavailability with innovation, new features, and efficient service operations by optimizing for the right balance of all.
Managing Risk
Unstable systems diminish user confidence. We want to avoid that.
Cost does not scale with improvements to reliability.
As you improve reliability the cost can actually increase many times over.
Two dimensions of cost:
Cost of redundancy in compute resources, and
The opportunity cost of trading features for reliability focused time.
SREs try to balance business goals in reliability with the risk of service reliability.
If the business goal is 99.99% reliable, then that’s exactly what the SRE will aim for, with maybe just a touch more.
They treat the target like a minimum and a maximum
The famous “SRE Book” from Google
Measuring Service Risk
Identify an objective metric for a property of the system to optimize.
Only by doing this can you measure improvements or degradation over time.
At Google, they focus on unplanned downtime.
Unplanned downtime is measured in relation to service availability.
Availability = Uptime / (Uptime + Downtime).
A 99.99% target means a maximum of 52.56 minutes downtime in a year.
At Google, they don’t use uptime as the metric as their services are globally distributed and may be up in many regions while being down in another.
Rather, they use the successful request rate.
Success rate = total successful requests / total requests.
A 99.99% target here would mean you could have 250 failures out of 2.5M requests in a day.
NOTE: not all services are the same.
A new user signup is likely way more important than a polling service for checking for new emails for a user.
At Google they also use this success rate for non-customer facing systems.
Google often sets quarterly availability targets and may track those targets weekly or even daily.
Doing so allows for fixing any issues as quickly as possible.
Risk Tolerance Services
SRE’s should work directly with the business to define goals that can be engineered.
Sometimes this can be difficult because measuring consumer services is clearly definable whereas infrastructure services may not have a direct owner.
Identifying the Risk Tolerance of Consumer Services
Often a service will have its own dedicated team and that team will best know the reliability requirements of that service.
If there is no owning team, often times the engineers will assume the role of defining the reliability requirements.
Factors in assessing the risk tolerance of a service
What level of availability is needed?
Do different failures have different effects on the service?
Use the service cost to help identify where on the risk continuum it belongs.
What are the important metrics to track?
Target level of availability
What do the users expect?
Is the service linked directly to revenue, either for Google or for a customer?
Is it a free or paid service?
If there’s a competing service, what is their level of service?
What’s the target market? Consumers or enterprises?
Consider Google Apps that drive businesses, externally they may have a 99.9% reliability because downtime really impacts the end businesses ability to do critical business processes. Internally they may have a higher targeted reliability to ensure the enterprises are getting the best level of customer service.
When Google purchased YouTube, their reliability was lower because Google was more focused on introducing features for the consumer.
Types of failures
Know the shapes of errors.
Which is worse, a constant trickle of errors throughout the day or a full site outage for a short amount of time?
Example they provided:
Intermittent avatars not loading so it’d show a missing icon on a page, vs
Potential issue where private user information may be leaked.
A large trust impact is worth having a short period of full outage to fix the problem rather than have the potential of leaking sensitive information.
Another example they used was for ads:
Because most users used the ads system during working hours, they deemed it ok to have service periods (planned downtime) in off hours.
Cost
Very high on the deciding factors for how reliable to make a service.
Questions to help determine cost vs reliability:
If we built in one more 9 of reliability, how much more revenue would it bring in?
Does the additional revenue offset the cost of that reliability goal?
Other service metrics
Knowing which metrics are important and which ones aren’t, allow you to make better informed decisions.
Search’s primary metric was speed to results, i.e. lowest latency possible.
AdSense’s primary metric was making sure it didn’t slow down a page load it appeared on rather than the latency at which it appears.
Because of the looser goal on appearance latency, they could reduce their costs by reducing the number of regions AdSense is served by.
Identifying the Risk Tolerance of Infrastructure Services
Infrastructure services different requirements than consumer services typically because they are serving multiple clients.
Target level of availability
One approach of reliability may not be suitable for all needs.
Bigtable example:
Real time querying for online applications means it has a high availability/reliability requirement.
Offline analytical processing, however, has a lower availability requirement.
Using an always highly available reliability target for both use cases would be hyper expensive due to the amount of compute that would be required.
Types of failures
Real-time querying wants request queues to almost always be empty so it can service requests ASAP.
Offline analytical processing cares more about throughput, so it never wants the queues to be empty, i.e. always be processing.
Success and failure for both use cases are opposites in this scenario. Its the same underlying infrastructure systems serving different use-cases.
Cost
Can partition the services into different clusters based on needs.
Low latency/high availability Bigtable cluster is a high level of service and more costly.
Throughput cluster can be built with less redundancy and need less headroom meaning they’re constantly processing making it much more cost effective.
Exposing those cost savings to the end customer helps customers choose the right availability model for their real needs.
This is all done via delineated service levels.
Much of this can all be done via configurations of the various services, i.e. redundancy, amount of compute resources, etc.
… Google SRE’s unofficial motto is “Hope is not a strategy”.
Site Reliability Engineering: How Google Runs Production Systems
Motivation for Error Budgets
Tensions form between feature development teams and SRE teams.
Software fault tolerance: How fault tolerant should the software be? How does it handle unexpected events?
Testing: Too little and it’s a bad end-user experience, too much and you never ship.
Push frequency: Code updates are risky. Should you reduce pushes or work on reducing the risks?
Canary duration and size: Test deploys on a subset of a usual workload. How long do you wait on canary testing and how big do you make the canary?
Anatomy of an Incident: Google’s Approach to Incident Management for Production Services
Forming Your Error Budget
Both teams should define a quarterly error budget based on the service’s SLO (service level objectives).
This determines how unreliable a service can be within a quarter.
This removes the politics between the SREs and product development teams.
Product management sets the SLO of the required uptime for the quarter.
Actual uptime is measured by an uninvolved third party, in Google’s case, “their monitoring system”.
The difference between actual downtime and allowed downtime is the budget.
As long as there is budget remaining, new releases and pushes are allowed.
Benefits
This approach provides a good balance for both teams to succeed.
If the budget is nearly empty, the product developers will spend more time testing, hardening, or slowing release velocity.
This sort of has the effect of having a product development team become self-policing.
What about some uncontrollable event, such as hardware failures, etc.?
Everyone shares the same SLO objectives, so the number of releases will be reduced for the remainder of the quarter.
This also helps bring to light some of the overly aggressive reliability targets that can slow new features from being released. This may lead to renegotiating the SLO to allow for more feature releases.
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Anatomy of an Incident: Google’s Approach to Incident Management for Production Services (sre.google)
There are a couple convenient flags for git checkout. Next time you are switching branches, try the --track or -t flag. It makes sure that your branch has your checkout.defaultRemote upstream set (typically “origin”), making for easier pulling and pushing. (git-scm.com)
git checkout -b <branchname> -t
There is a -vv flag you can pass to git branch to list all the branches you have locally, including the remote info if they are tracked so you can find any branches that don’t have the upstream set. (git-scm.com)
git branch -vv
You can configure git to always set up new branches so that git pull will automatically merge from the starting point branch (assuming you are tracking an upstream branch, see previous 2 tips.) (git-scm.com)
git config --global branch.autoSetupMerge always
From Michael Warren on the comments from last episode, Caffeine is an updated take on the caching code founding in the Java Guava library from google (GitHub)
Great tips from @msuriar!
Great talk from Tanya Reilly about “glue work”, some of the most important work can be hard to see and appreciate. How do we make this better? Technical leadership and glue work – Tanya Reilly | #LeadDevNewYork (YouTube)
Google has a free book available on Incident Response! Great advice on handling and preventing incidents. Anatomy of an Incident: Google’s Approach to Incident Management for Production Services (sre.google)
Minikube!
Minikube is a great way to run Kubernetes clusters locally. It’s cross platform and has a lot of nice features while also still being relatively simple to use and user-friendly. (minikube.sigs.k8s.io)
Minikube has addons that you can install that add additional capabilities, like a metrics server you can use to see what resources are being used, and by what!
minikube addons enable metrics-server
You can also run a “top” style command to see utilization once you have enabled the metrics. (linuxhint.com)
kubectl top pods
There’s also a dashboard that’s available that you can use to deploy, troubleshoot, manage resources, and make changes. (minikube.sigs.k8s.io)
It’s finally time to learn what Site Reliability Engineering is all about, while Jer can’t speak nor type, Merkle got one (!!!), and Mr. Wunderwood is wrong.
Thanks for the review “Amazon Customer”! (You, er, we know who you are.)
Site Reliability Engineering
Site Reliability Engineering: How Google Runs Production Systems is a collections of essays, from Google’s perspective, released in 2016 … and it’s free. (sre.google)
There’s a free workbook to go along with it too. (sre.google)
These essays are what one company did, that company being Google.
The book is told from the perspective of people within the company.
It is about scaling a business process, rather than just the machinery.
Site Reliability Engineering: How Google Runs Production Systems
Their tale should be used for emulating, not copying.
40-90% of your effort is after you have deployed a system.
The notion that once your software is “stable”, the easy part starts is just plain wrong.
Yeah, but what is a Site Reliability Engineering role?
It’s engineers who apply the principles of computer science and engineering to the design and development of computing systems, usually large distributed ones.
It includes writing software for those systems.
Including building all the additional pieces those systems need, i.e. backups, load balancers, etc.
Reliability … the most fundamental feature of any product?
Software doesn’t matter much if it can’t be used.
Software need only to be reliable “enough”.
Once you’ve accomplished this, you spend time building more features or new products.
SRE’s also focus on operating services on top of the distributed computing systems. Examples include:
Storage,
Email, and
Search.
Reliability is regarded as the primary focus of the SRE.
The book was largely written to help the community as a whole by exposing what Google did to solve the post deploy problems as well as to help define what they believe the role and function is for an SRE.
They also call out in the book that they hope the information in the book will work for small to large businesses. Even though they know small businesses don’t have the budget and manpower of larger businesses, the concepts here should help any software development shop.
However, we acknowledge that smaller organizations may be wondering how they can best use the experience represented here: much like security, the earlier you care about reliability, the better.
Site Reliability Engineering: How Google Runs Production Systems
It’s less costly to implement the beginnings of lightweight reliability support early in the software process rather than introduce something later that’s not present at all or has no foundation.
Who was the first SRE? Maybe Margaret Hamilton? (Wikipedia)
The SRE way:
Thoroughness,
Dedication,
Belief in the value of preparation and documentation, and
Awareness of what could go wrong, and the strong desire to prevent it.
Hope is not a strategy.
Site Reliability Engineering: How Google Runs Production Systems
Chapter 1 – Introduction
The famous “SRE Book” from Google
Consider the sysadmin approach to system management:
The sysadmins run services and respond to events and updates as they happen.
Teams typically grow as the capacity is needed.
Usually the skills for a product developer and a sysadmin are different, therefore they end up on different teams, i.e. a development team and an operations team (i.e. the sysadmins).
This approach is easy to implement.
Disadvantages of the sysadmin approach:
Direct costs that are not subtle and are easy to see.
As the size and complexity of the services managed by the operations team grows, so does the operations team.
Doesn’t scale well because manual intervention with regards to change management and process updates requires more manpower.
Indirect costs that are subtle and often more costly than the direct costs.
Both teams speak about things with different vocabularies (i.e. no ubiquitous language from back in the DDD days).
Each team has different assumptions about risk and possibilities for technical solutions.
Each team has different assumptions about target level of product stability.
Due to these differences, these teams usually end up in conflict.
How quickly should software be released to production?
Developers want their features out as soon as possible for their customers.
Operations teams want to make sure the software won’t break and be a pain to manage in production.
A developer always wants their software released as fast as possible.
An ops person would want to minimize the amount of changes to ensure the system is as stable as possible.
This results in trench warfare between the two groups!
Operations introduces launch and change gates, such as test for every problem that’s ever happened.
Development teams introduce fewer changes and introduce more feature flags, such as sharding the features so they’re not beholden to the launch review.
What exactly is Site Reliability Engineering, as it has come to be defined at Google? My explanation is simple: SRE is what happens when you ask a software engineer to design an operations team.
Site Reliability Engineering: How Google Runs Production Systems
Google’s Approach to this Problem?
Focus on hiring software engineers to run their products (not sysadmins).
Create systems to accomplish the work that would have historically been done by sysadmins.
SRE can be broken down into two main categories:
50-60% are Google software engineers, that is people who were hired via the standard hiring procedure.
40-50% are candidates who were very close to the Google software engineer qualifications but didn’t quite make the original cut.
Additionally, they had skills that would be very valuable for SRE’s but not as common in typical software engineers, like Unix system internals and networking knowledge.
SREs believe in building software to solve complex technical problems.
Google has tracked the progress career-wise of the two groups and have found very little difference in their performance over time.
Software engineers get bored by nature doing repetitive work and are mentally geared towards automating problems with software solutions.
SRE teams must be focused on engineering.
Traditional ops groups scale linearly by service size, hiring more people to do the same tasks over and over.
For this reason, Google puts a 50% utilization cap on SRE’s doing traditional ops work.
This ensures the SRE team has time to automate and stabilize the software through means of automation.
Over time, as the SRE team has automated most of the tasks, their operations workload should be reduced to minimal amounts as the software runs and heals itself.
The goal is that the other 50% of the SRE’s time is on development.
Only way to maintain those rates is to measure them.
Google has found that SRE teams are cheaper than traditional ops teams with fewer employees because they know the systems well and prevent problems.
… we want systems that are automatic, not just automated.
Site Reliability Engineering: How Google Runs Production Systems
Challenges
Hiring is hard and the SRE role competes with product teams.
Pager duty!
Requires developer skills as well as system engineering.
This is a new discipline.
Requires strong management to protect the budgets, such as stopping releases, respecting the 50% rules, etc.
One could view DevOps as a generalization of several core SRE principles to a wider range of organizations, management structures, and personnel. One could equivalently view SRE as a specific implementation of DevOps with some idiosyncratic extensions.
Site Reliability Engineering: How Google Runs Production Systems
Tenants of SRE
Availability
Latency
Performance
Efficiency
Change Management
Monitoring
Emergency Response
Capacity Planning
Durable Focus on Engineering
In order to keep time for project work, SREs should receive a maximum of 2 events per 8-12 hour on-call shift.
This low volume allows the engineer to spend adequate time for accuracy, cleanup, and postmortem.
More than events that mean you have a problem to solve or more SREs to hire, less and you have too many SREs.
Postmortems should be written for all significant incidents, whether paged or not.
Non-paged work might be even more important since it can point to a hole in the monitoring.
Cultivate a blame-free postmortem culture.
Max Change Velocity
An error budget is an interesting way to balance innovation and reliability.
Too many problems and you need to slow down and focus more on reliability, not enough problems and you’re probably gold plating.
Ever have a manager push back on tech-debt? Maybe they aren’t aware of this balance? What can you do to quantity it?
100% uptime is generally considered to not be worth it, as gets more expensive as you get closer to the mark and your customers generally don’t have 100% uptime, so it’s wasteful.
What is the right reliability number though? That’s a business decision.
What downtime percentage will the users allow, based on their usage of the product?
How critical is your service? Is there a workaround?
How well does the experience degrade?
What could a team do if there’s not anymore room in the budget?
What if there’s too much?
Monitoring
Monitoring is how to track the system’s health and availability.
Classic approach was to have an alert get sent when some event or threshold is crossed.
This is flawed though because anything that requires human intervention is by it’s very definition, not automated and introduces latency.
Software should be interpreting and people should only be involved when the software can’t do what it needs to do.
Three types of valid monitoring:
Alerts – a person needs to take immediate action.
Tickets – a person needs to take action but not immediately. The event cannot automatically be handled but can wait a few days to be resolved.
Logging – nobody needs to do anything. The logs should only be viewed if something prompts them to do so.
Reliability is a function of mean time to failure (MTTF) and mean time to repair (MTTR).
Site Reliability Engineering: How Google Runs Production Systems
Emergency Response
The best metric for determining effectiveness of an emergency response is the MTTR, i.e. how quickly things got back into a healthy state.
People add latency. Even if there are more failures, a system that can avoid emergencies that require people to do something, will still have higher availability.
Thinking through problems before they happen and creating a playbook resulted in 3x improvement in MTTR as opposed to “winging it”.
On call SRE’s always have on-call playbooks while also doing exercises they dub the Wheel of Misfortune to prepare for on call events.
Change Management
70% of outages are due to changes in a live system.
Best practices:
Progressive rollouts,
Quickly and accurately detecting problems, and
Ability to rollback safely when something goes wrong.
Removing people from the loop, the practices above help improve release velocity and safety.
Demand Forecasting and Capacity Planning
Forecasting helps you ensure service availability and keep costs in check and understood.
Be sure to account for both organic growth, i.e. normal usage, and inorganic growth, such as launches, marketing, etc.
Three mandatory steps:
Accurate organic forecast, extending beyond the leadtime for adding capacity,
Accurate incorporation of inorganic demand sources, and
Regular load testing.
Provisioning
The faster provisioning is, the later you can do it.
The later you can do it, the less expensive it is.
Not all scaling is created equally. Adding a new instance may be cheap but repartitioning can be very risky and time consuming.
Efficiency and Performance
Since SRE are in charge of provisioning and usage, they are close to the costs.
It’s important to maximize resources, which fundamentally affect the success of the project.
Systems get slower as load is added, and slowness can also be viewed as a loss of capacity.
There is a balance between cost and speed. SREs are responsible for defining and maintaining SLOs.
Resources we Like
Links to Google’s free books on Site Reliability Engineering (sre.google)
Why is SRE Becoming 2021’s Hottest Hire? (GlobalDots.com)
We’re living through the tail end, maybe?, of the Great Resignation, so we dig into how that might impact software engineering careers while Allen is very somber, Joe’s years are … different, and Michael pronounces each hump.
Mergify – Save time by automating your pull requests and securing the code merge using a merge queue.
Survey Says
Reviews
Thanks for the review Chuck Rugged (or is it Rugged?).
What is “the great resignation”?
The Great Resignation is an ongoing economic trend where a lot of people started quitting their jobs in 2021 and peaked at 3% unemployment (up roughly 50% from the pre-COVID unemployment average).
Primarily, but not exclusively, in the US, but also trended in Europe, China, India, Australia as well.
Some interesting factors:
High worker demand and labor shortages.
High unemployment.
Employees between 30 and 45 years old have had the greatest increase in resignation rates, with an average increase of more than 20% between 2020 and 2021.
Resignation rates actually dropped for people in their 20s.
Tech and healthcare led the trend, 4.5% for US, 3.6% for healthcare.
Reasons cited included stagnant wages and working conditions.
Why is this a big deal?
Hiring is expensive! Think of thinks like referral fees, recruiter’s percentage, takes a while for people to become productive, onboarding, etc.
What does this mean for working conditions? More remote, better compensation, more flexibility, etc.?
Senior engineers are senior developers who may specialize in a specific area, oversee projects, and manage junior developers.
Principal Engineer is a highly experienced engineer who oversees a variety of projects from start to finish.
Staff engineer is a senior, individual contributor role in a software engineering organization. There is no “one” kind of staff engineer and many fall into one of four archetypes: Tech Lead, Architect, Solver, and Right Hand. (staffeng.com)
Is there a hiring level cap? What does that mean?
What can you lose?
The people,
The grass isn’t always greener,
Seniority (don’t be the “At X we …” person), and/or
Did you know you can expand or collapse all the files in a pull request on GitHub? Press Alt + Click on any file chevron in the pull request to collapse or expand them all! (github.blog)
Thanks to Dave Follett for sharing How to securely erase your hard drive or SSD! (pcworld.com)
Thanks to Fuzzy Muffin for sharing Nvchad, a nice face for Neovim (Nvim) that adds some nice features, like directory access and tabs. (nvchad.github.io)
Use git-sizer to get various statistics about your repository. (GitHub)
How to find/identify large commits in git history? (Stack Overflow)
Then forget about BFG and filter-branch, git filter-repo is the way to remove large files from your Git repo (GitHub)
Use --shallow-exclude to exclude commits found in the supplied ref in either (or both) your git clone (git-scm.com) or git fetch operations. (git-scm.com)
Limit your git push operation “up to” a commit by using the format git push <remote name> <commit ID>:refs/heads/<branch name>. (If the <branch name> already exists on the <remote name>, you can leave off the refs/heads/ portion. (git-scm.com)
We dive into what it takes to adhere to minimum viable continuous delivery while Michael isn’t going to quit his day job, Allen catches the earworm, and Joe is experiencing full-on Stockholm syndrome.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Survey Says
Sidebar
Revisiting unit testing private methods in 2022, what would you do?
Minimum Viable Continuous Integration
CD is the engineering discipline of delivering all changes in a standard way safely.
minimumcd.org
The belief is that you must at least put a certain core set of pieces in play to reap the benefits of Continuous Delivery.
The outcome that they’re looking for is the improved speed, quality, and safety of the deployment pipeline.
Minimum requirements:
Use continuous integration, continuously integrating work into the trunk of your version control and ensuring, as much as possible, that the product is releasable.
The application pipeline is the ONLY way to deploy to an environment.
The pipeline decides if the work is releasable.
The artifacts created by the pipeline meet the organization’s requirement for being deployable.
The artifacts are considered immutable, nobody may change them after they were created by the pipeline.
All feature work stops if the pipeline status is red.
Must have a production like test environment.
Must have rollback on demand capability.
Application configuration is deployed with the artifacts.
If the pipeline says everything looks good, that should be enough – it forces the focus on what ‘releasable’ means.
Dave Farley
Continuous Integration
Use trunk based development.
Integrated daily at a minimum.
Automated testing before merging work code to the trunk.
Work is tested with other work automatically during a merge.
All feature work stops when the build is red.
New work does not break already delivered work.
Trunk Based development
What is trunk based development?
Developers collaborate on a single branch, usually named trunk, main, or something similar.
You must resist any pressure to create other long-lived development branches.
The argument is that the simplicity of this structure is more than worth anything you might gain by any other structure.
For small teams, this is easy, each committer commits straight to trunk, after a build/test gate.
For larger teams, you use short-lived feature branches that might live for a couple days max and end with a PR review and build/test gate.
What does this buy us?
The codebase is always releasable on demand.
Google, Facebook, authors of Continuous Delivery and The DevOps Handbook advocate for it.
But how do we …
Big feature? Feature flag it off.
Hot fix? Fix forward.
But …
What if you need multiple CONSECUTIVE releases? i.e. think of the Kubernetes release cycle.
What if you need multiple CONCURRENT releases? i.e. think of Microsoft support for multiple versions of Windows.
Our discussions of The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Coding Blocks)
Tip of the Week
Did you know you cannot set environment variables in Java?
Terms & Conditions Apply is a game where you have to avoid giving up all your juicy data to Evil Corp by carefully avoiding accepting the terms and conditions. Good luck. Thanks Lars Onselius! (TermsAndConditions.game)
Test Containers is a Java library that gives you a way to interact with and automate containers for testing purposes. Thanks Rionmonster! (TestContainers.org)
Maybe it’s time for JSON to die? YAML is finicky, but it’s easier to read and it allows comments.
YamlDotNet is a library that makes this easy in C#. (YamlDotNet.org)
PowerToys are a collection of utilities from Microsoft that extend Window with some really powerful and easy to use features. Thanks Scott Harden! (Microsoft)
Did you know you can now include diagrams inside your markdown files on Github? Mermaid is the name and you can create the diagrams directly in your files and keep it versioned along with your code. Thanks Murali and Scott Harden! (github.blog)
We have a retrospective about our recent Game Ja Ja Ja Jam, while Michael doesn’t know his A from his CNAME, Allen could be a nun, and Joe still wants to be a game developer.
Followers is a clever 2D platformer puzzle game where you play as 2 different characters in 2 different levels at the same time. You hit the jump button, they both jump. You move left or right, they both attempt to move left or right. The task is to safely collect all the fruit in the level but you “safely” is the keyword here because you have to be really thoughtful about your actions. The trick is utilize the various obstacles in the different levels to position your characters just right to get through. Doing this is a real mind bender, but it’s really satisfying when you figure out how to get through. The art and music fit perfectly and it’s such a cool riff on the the theme since both characters literally follow along with whatever you tell them…which usually leads to their demise!
Knock ‘Em is a 3D arcade style action game where you play as a bowling ball tasked with knocking down bowling pins…that sounds pretty normal, but once you start the game you realize that you are in for a treat. You have full reign of the bowling alley, and the characters in this game are all bowling pins. That’s right, you are a bowling ball blasting around in an alley full of bowling pins that are…bowling! You get a point for every pin and are chased by alley staff pins and police pins that will ultimately wear down your health and end the game. The action is frantic and fun and funny, with a lot of attention to details.
Michael M. – Programming Lead, Game Design, Level Design, UI Design
Cheyenne M. – Art, Programming, Game Design, Sound Design
Alex M. – Game Testing, Special Thanks
Just Down the Hall is a spooky 2D action platformer. In the game a deadly shadow is following behind you, jumping when you jump. If you clear an obstacle the shadow will plow into it, slowing it down. If you hit an obstacle, you slow down and the shadow catches up. The game has a really cool split screen feature where you can watch the shadow following you and smacking into obstacles. This is really cool to watch and it leads to some really tense and rewarding moments as it gets closer and closer to you. The art is beautiful as well so it actually feels good when it inevitably ends.
Live & Evil is a 2D puzzle platformer game about a robot named “Live” and their show “Evil”…which is also the word “live” spelled backwards and the the logo reflects that in a cool way. This is important to note because in this game you swap between the two characters by hitting the Q button. Live walks on top of the platforms, Evil on the bottom. Items like collectables, switches or platforms may only be visible or usable by one of the characters so you’ll have to use both of them to win. This plays out in increasingly interesting ways as the game progresses…and again, you’ll have to see it to believe it.
Light of the World is a 2D puzzle platformer with dark atmospheric and spooky levels, you are charged with rushing between beautiful beacons of light before the your enemy can attack. It has a light but powerful narrative with a really cool bouncing shield mechanic that you can throw and retrieve to solve some light, but clever, puzzles. It’s hard to really talk about this game because every aspect of it is done so well that your jaw is on the floor the whole time. Even the YouTube video trailer for the game was expertly done and you can tell that user experience was always the top priority. This game was rated highest in all 3 categories!
“a path alone” is a thoughtful 2D box pushing puzzle game. It’s dark, and moody, and beautiful and strange. Every level features a beautiful pixel art animal that will grant you a new ability in exchange for a favor. The advice they give you is somber and there’s something about the music and the animations and the mood that gives these interactions some emotional weight, so you are feeling something as you play this game. It’s hard to pin down exactly what that feeling is, and that’s part of the fun. The amount of polish is really evident here and you can really see how much that care and attention given to user experience pays off.
What am I supposed to do is 2D drag and drop puzzle / action game in which the player is charged with helping a character escape from a terrifying and really cool looking “windy monstrosity”. You don’t directly control the character, but you do have items that you can drop into the stages to help the character out. Drop a sword and a character will slash, drop a cloud if there’s a long fall to help your character land softly. The music adds to the frantic pace and the game really steps it up in later levels where you get random items and have to quickly figure out how to make do with what you have available.
It Follows Me from Fussenkuh was a really fun and unique take on the theme, where you have to thumbs up or thumbs down pairs of words based on whether the first word has the letters “me” and the second word has “it”. Get it? You up vote the pairs of words where “it” follows “me”. You only have a few seconds to make each decision so even though this is a word game, I’m probably more likely to classify it as an action game. Slapping the thumbs up and thumbs down actions are reminiscent of social media, and given the popularity of a little game called wordle, this game has an interesting contemporary tone that gives you this odd feeling that you’re playing an fun artifact from…right now.
I became a Treasure Hunter to Pay Off My Student Debt, but now an Immortal Snail is Coming after me with a Knife (itch.io)
“I became a Treasure Hunter to Pay Off My Student Debt, but now an Immortal Snail is Coming after me with a Knife”, which also wins the award for best title. In this game you try to collect all the treasure before you are caught by a knife wielding snail. The snail is slow at first, but speeds up as you collect each treasure making for a really tense end game experience.
Ducks in Space is a beautiful 3D snake like game where you gather little ducklings who follow you as you swim around a cool spherical planet. If you run into your duckling tail, the game is over, but you also have to avoid some hungry herons. The game looks, sounds, and plays great and was written in native html and JavaScript, which makes everything even the game even more impressive!
Tip of the Week
We just couldn’t help ourselves and we took all of our tips from Simon Barker this week!
Having a tough time trying to figure out a name for your new app? Check out this site, it’ll help you find that name and tell you what platforms are available for it! (namae.dev)
Check out the rebranded/relaunched podcast “All The Code” from Simon Barker (podcasts.apple.com)
Crontab guru makes it easy to build and understand cron schedule expressions (crontab.guru)
We wrap up our discussion of PagerDuty’s Security Training, while Joe declares this year is already a loss, Michael can’t even, and Allen says doody, err, duty.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Survey Says
News
Ja Ja Ja Jamuary is complete and there are 46 new games in the world. Go play! (itch.io)
Session Management
Session management is the ability to identify a user over multiple requests.
HTTP is stateless, so there needs to be a way to maintain state.
Cookies are commonly used to store information on the client to be sent back to the server on subsequent requests.
They usually contains a session token of some sort, which should be a random unique string.
Do NOT store sensitive information in the cookie, such as no usernames, passwords, etc.
Besides tampering, it can be difficult to revoke the cookies.
Session Hijacking
Session hijacking is stealing a user’s session, possibly by:
Guessing or stealing the session identifiers, or
Taking over cookies that weren’t properly locked down.
Session Fixation
Session fixation is when a bad actor creates a session that you will unknowingly take over, thus giving the bad actor access to the data in the user’s session.
This used to be more of an issue when session tokens were passed around in the URL (remember CFID and CFTOKEN?!).
Always treat cookies like any other user input, don’t implicitly trust it, because it can be manipulated on the client.
How to Secure / Verify Sessions
Add extra pieces of data to the session you can verify when requests are made.
Ensure you actually created the session.
Make sure it hasn’t expired and ensure you set expirations for sessions.
All of this just catches the easy stuff.
Session ID’s should be unique and random.
Ensure the following when sending cookies to the client:
Secure flag is set,
httpOnly flag is set, and
The domain is set on the cookie so it can only be used by your application.
To avoid the session fixation we mentioned earlier, ALWAYS make sure to send a new session ID when privileges are elevated, i.e. a login.
Always keep information stored on the server side, not on the client.
Make sure you have an expiration that is set on the server side session. This should be completely independent of the cookie because the cookie values can be manipulated.
When a user logs out or the session expires, ensure you fully destroy all session information.
NEVER TRUST USER INPUT!
Permissions
Try to avoid using sudo in any shell scripts if you can.
If you can’t avoid it, use it with care.
The the principle of least privilege, i.e. more restrictive permissions, as in, can you live with read-only perms?
Revoke permissions you don’t need.
Create separate users for separate needs.
If you need to delete files from a storage bucket, have a service account or user set up with just that permission.
Same for managing compute instances.
Use the least permissive approach you can as it greatly reduces risks.
Other Classic Vulnerabilities
Buffer overflow: This is when a piece of data is stored somewhere it shouldn’t be able to access.
From Wikipedia, a buffer overflow _”is an anomaly where a program, while writing data to a buffer, overruns the buffer’s boundary and overwrites adjacent memory locations.”_
Typically these are used to execute malicious code by putting instructions in a piece of memory that is to be executed after a previous statement completes.
One malicious use of a buffer overflow is using a NOP sled (no-operation sled) to fill up the buffer with a lot of NOPs with your malicious code at the end of the ride.
Apparently you can use this method to easily get a root shell – article linked in the resources
Path Traversal: This is when you “break out” of the web server’s directory and are able to access, or serve up, content from elsewhere on the server
Remember, your dependencies may also have vulnerabilities such as this. You need to run scans on your apps, code, and infrastructure.
Side Channel Attacks: This is when the attacker is using information that’s not necessarily part of a process to get information about that process. Examples include:
Timing attack: Understanding how long certain processes take can allow you to infer information about the process. For example, multiplication takes longer than addition so you might be able to determine that there’s multiplication happening.
Power analysis: This is when you can actually figure out what a processor is doing by analyzing the electrical power being consumed. An example of this process is called differential power analysis.
Acoustic cryptanalysis: This is when the attacker is analyzing sounds to find out what’s going on, such as using a microphone to listen to the sounds of typing a password.
Data remanence: This is when an attacker gets sensitive data after it was thought to have been deleted.
Did you know you can use your phone as a pro level webcam? Thanks Simon Barker! (reincubate.com)
From the tip hotline (cb.show/tips) – Mikerg sent us a great site for learning VSCode. Some are free, some require a $3 monthly subscription, but the ones Joe has done have been really good. Not just VSCode either! IntelliJ, Gmail, lots of other stuff! (keycombiner.com)
How to use Visual Studio Code as the default editor for Git MergeTool (stackoverflow.com)
Five Easy to Miss PostgreSQL Query Performance Bottlenecks (pawelurbanek.com)
We’re pretty sure we’re almost done and we’re definitely all present for the recording as we continue discussing PagerDuty’s Security Training, while Allen won’t fall for it, Joe takes the show to a dark place, and Michael knows obscure, um, stuff.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Survey Says
News
Thanks for the reviews!
iTunes: YouCanSayThisNickname
Game Ja Ja Ja Jam is coming up! Just a few days away! (itch.io)
XSS – Cross Site Scripting
Q: What is XSS? A: XSS is injecting snippets of code onto webpages that will be viewed by others.
This can allow the attacker to basically have access to everything a user does or types on a page.
Consider something like a comment on a forum, or blog that allows one to save malicious code.
The attacker could potentially access cookies and session information,
As well as gain access to keyboard entry on the page.
You can sanitize the inputs, but that’s not good enough.
You can’t check for everything in the world.
You really need to be encoding the stored information before you present it back to any users.
This allows things to be displayed as they were entered, but not executed by the browser.
Different languages, frameworks, libraries, etc., have their own ways of encoding information before it’s rendered by the browser. Get familiar with your library’s specific ways.
User supplied data should ALWAYS be encoded before being rendered by the browser. ALWAYS.
This goes for HTML, JS, CSS, etc.
Use a library for encoding because the chances are they’ve been vetted.
Just like we mentioned before, you still have to be diligent about using 3rd party libraries. Using a 3rd party library doesn’t mean you can wash your hands of it.
Content Security Policy (CSP) is another way to handle this. (Wikipedia)
OWASP considers XSS a type of Injection attack in 2021.
CSRF – Cross Site Request Forgery
Q: What is CSRF? A: CSRF is tricking someone into doing something they didn’t want to do, or didn’t know they were doing.
A couple of examples were given:
For example, set the img src to the logout for the site so that when someone visits the page, they’re automatically logged out.
Just imagine if the image source pointed to something a little more nefarious.
Another example is a button that tricked you into performing an action such as an account deletion on another site. Can be done using a form post and a simple button click.
How do you avoid this?
Synchronizer token:
This is a hidden field on every user submittable form on a site that has a value that’s private to the user’s session.
These tokens should be cryptographically strong random values so they can never be guessed or reverse engineered.
These tokens should never be shared with anyone else.
When the form is submitted, the token is validated against the user’s session token, and if it matches, go ahead with the action, otherwise abort.
Again, there are a number of frameworks and libraries out there that have anti-forgery built in. Check with your specific documentation.
They go on to say that anything that is not a READ operation should have CSRF tokens.
NEVER use GET requests for state changing operations!
PagerDuty had a funny mention about an administrative site that included links to delete rows from the database using GET requests. However, as the browser pre-fetched the links, it deleted the database.
OWASP dropped CSRF from the Top 10 in 2017 because the statistical data didn’t rank it highly enough to make the list.
Click-jacking
Q: What is click-jacking? A: Click-jacking is when you are fooled into clicking on something you didn’t intend to.
For example, rendering a page over the top of an iframe, and anything that was clicked on that top page (that seemed innocent) would actually make the click happen on the iframe‘d page, like clicking a Buy it Now button.
Another example is moving a window as soon as you click causing you to click on something you didn’t intend to click.
The best way to prevent click-jacking is to lock down what an iframe can load using the HTTP header X-FRAME-OPTIONS, set to either SAMEORIGIN or DENY. (developer.mozilla.org)
Account Enumeration
Q: What is account enumeration? A: Account enumeration is when an attacker attempts to extract users or information from a website.
Failed logins that take longer for one user than another may indicate that the one that took longer was a real user, maybe because it takes longer as it tries to hash the password.
Similar type of thing could happen if customers are subdomained. One subdomain shows properly and another fails. This reveals information about the customers.
These may be frustrating, as they pointed out, as you have to walk the line between user experience and security.
Just be aware of what type of data you might be exposing with these types of operations.
Regarding logins:
If the user exists or doesn’t, run the same hashing algorithm to not give away which is real or not.
If a user does a password reset, don’t give a message indicating whether the account really existed or not. Keep the flow and messaging the same.
CloudFlare let’s you deploy JAMStack websites for free using their edge network. (pages.cloudflare.com)
Amazon has their own open-source game engine, Open 3D Engine, aka O3DE. It’s the successor to Lumber Yard, a AAA-capable, cross-platform, open source, 3D engine licensed under Apache 2.0. (aws.amazon.com, o3de.org)
Let’s talk about CSS! Ever use border to try and figure out layout issues? Why not use outline instead? Thanks Andrew Diamond! (W3Schools.com)
We discussed a similar technique as a TotW for episode 81.
Have you seen those weird mobile game ads? Click this link, maybe when you’re not at work, and embrace the weird world of mobile game ads. (Reddit)
Nostalgia for the 80’s? People have uploaded some of the tapes that used to play on the loudspeakers at US department store, K-Mart (Nerdist.com)
We continue our discussion of PagerDuty’s Security Training presentation while Michael buys a vowel, Joe has some buffer, and Allen hits everything he doesn’t aim for.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Shortcut – Project management has never been easier. Check out how Shortcut is project management without all the management.
Survey Says
News
Thanks for the reviews!
iTunes: aodiogo
Game Ja-Ja-Ja-Jamuary is coming up, sign up is open now! (itch.io)
Encryption
OWASP has the more generic “Cryptographic Failures” at #2, up from #3 in 2017.
PagerDuty defines encryption as encoding information in such a way that only authorized readers can access it.
Note that this is an informal definition that speaks to the most common use of the word.
Encryption is really, really difficult to get right. There are people that spend their whole lives thinking about encryption, and breaking encryption. You may think you’re a genius by coming up with a non-standard implementation, but unfortunately the attackers are really sophisticated and this strategy has shown to fail over and over.
There are different types of encryption:
Symmetric/Asymmetric – refers to whether the keys for reading and writing the encrypted data are the same.
Block Cipher – Lets you encrypt and decrypt the data in whole chunks. You need to have an entire block to encrypt or decrypt the whole block at once.
Public/Private Key – A kind of asymmetric encryption intended for situations where you want groups to be able to share one of the keys. For example, you can publish a public PGP key and then people can use that to send you a message. You keep the private key private, so you’re the only entity that can read the message.
Stream Cipher – Encode “on the fly”, think about HTTPS, great for streaming. You can start reading before you have the entire message. Great for situations where performance is important, or you might miss data.
Encryption in Transit
Also known by other names such as data in motion.
Designed to protect against entities that can snoop (or manipulate!) our communications.
You can do this with HTTPS, TLS, IPsec.
Perfect Forward Secrecy is the key to protecting past communications, by generating a new key for a single session so that compromised keys only affect the specific session they were used for.
From Wikipedia “In cryptography, forward secrecy (FS), also known as perfect forward secrecy (PFS), is a feature of specific key agreement protocols that gives assurances that session keys will not be compromised even if long-term secrets used in the session key exchange are compromised.” (Wikipedia)
Encryption at Rest
Simply means that data is encrypted where it’s stored.
An example of this is full disk encryption on laptops and desktops. The entire drive is encrypted so if someone were to steal the drive, it’d essentially be useless without the keys to decrypt the data on the drive.
For PagerDuty, and many other companies, the most important information to protect is customer data, just as important as your own passwords.
PagerDuty’s data classifications:
General data – This is anything available to the public.
Business data – Includes operating data for the business, such as payroll, employee info, etc. This type of data is expected to be encrypted in transit and at rest.
Customer data – This is data provided to the company by the customer and is expected to be encrypted in transit and at rest.
Customer data includes controls such as authentication, access control, storage, auditing, encryption, and destruction.
Business data has similar controls except without the auditing.
PagerDuty called out when using cloud systems, make sure you’re enabling the encryption on the various services, like S3, GCS, Blob storage, etc.
They mentioned it’s just a checkbox, but in reality you’re probably using scripts, templates, etc. So make sure you know the configurations to include to enable encryption.
Another interesting thing they do at PagerDuty: they get alerted when a resource is created without encryption enabled.
What about third parties you use? Should they encrypt as well? YES!!!
Perform vendor risk assessments prior to using the vendor. If they don’t pass the security assessment, use a different vendor.
Secret Management
Q. What is it? A. Protecting and auditing access to secrets.
Auditing so that you can see when someone is using your secrets that shouldn’t, as well as keep track of systems that should and are using secrets.
Hashicorp Vault has a great video to learn about the challenges of managing secrets. (YouTube)
What are secrets?
Secrets are sensitive things such as tokens, keys, passwords, user names, many others.
Secrets should NOT be stored in source control.
Although it seems to happen all the time, be it on purpose, by accident, etc.
Anyone with access to the code can now access the secrets.
PagerDuty uses Vault. Vault:
Securely stores secrets,
Provides audit access to those secrets, and
Provides mechanisms to rotate the secrets if/when necessary.
Don’t hardcode or come up with crazy ways to get secrets into your applications.
Secrets should never be shared, i.e. if two people need access to a system, they should have their own secrets to access that system.
Or maybe you have a “jump” server that has access to an external system, and users have access to the jump server.
NEVER share passwords over insecure channels. This can include channels such as:
Slack,
Email,
SMS,
But this is not an exhaustive list.
If you do accidentally post a secret in a chat or an insecure channel, you should:
Let the security team know immediately (you have a security team right?!), and
Find out how to rotate the secret and do it.
Never allow a secret to be logged!
This can be especially egregious if you’re logging customer credentials you don’t control.
Be sure you are sanitizing your log data before you log.
Hashicorp Vault is a tool for managing secrets, but did you know they have a ton of plugins? Take a look! (VaultProject.io)
Unity has tools built in for common game functionality, it’s worth taking a few minutes to google for something before you start typing. Don’t worry, there is still plenty of code to write, but these tools improve the quality and consistency of your game.
You can use animation clips to create advanced character animations, but it’s also good for simple tweens and motions that need to happen once, or in a loop. No need for “Rotator.cs” type classes that you see in a lot of Unity tutorials. (docs.unity3d.com)
NavMeshes are an efficient ways of handling pathfinding, which is an important piece of many games. You can learn the basics in just a few minutes and accomplish some amazing things. (docs.unity3d.com)
We’re taking our time as we discuss PagerDuty’s Security Training presentations and what it means to “roll the pepper” while Michael is embarrassed in front of the whole Internet, Franklin Allen Underwood is on a full name basis, and don’t talk to Joe about corn.
It’s good to learn about the common security vulnerabilities when developing software! What they are, how they are exploited, and how they are prevented.
WebGoat is a website you can run w/ known vulnerabilities. It is designed for you to poke at and find problems with to help you learn how attackers can take advantage of problems. (OWASP.org)
“But the framework takes care of that for me”
Don’t be that person!
Recent vulnerability with Grafana, CVE-2021-43798. (SOCPrime.com)
You can’t always wait for a vulnerability patch to be released. You may need to patch one yourself.
Basically, even if you’re using a framework, it doesn’t mean you can be naïve to everything about it.
You shouldn’t use the excuse “It’s just for a hackathon” or “It’s a proof of concept.”
This can include things like disabling firewalls, etc.
Don’t put things on a public repo, as you might accidentally share company secrets, intellectual property, etc.
Open sourcing may be an option later, but it should be looked through first.
NEVER use customer data when doing hackathons or proofs of concepts. Too many things can go wrong if it leaks out.
Maybe a better rule of thumb would be to never use customer data for any type of development. Instead, always use fake data.
The slides had an interesting story that was redacted: there was a software vulnerability that was discovered that existed due to a missing check-in of code, i.e. everything was functioning perfectly fine, and there was an effort already to plug a hole in the code, but it just never made it into the repo. Nearly impossible to detect by automated tools.
Vulnerability #1 – SQL Injection
OWASP has more a generic “Injection” as the #3 position, down from #1 in 2017.
An example is manipulating a query at runtime with user provided input.
This typically implies that strings are patched into a query directly, i.e. WHERE password = '$providedPassword'.
Can be attacked by doing something like providedPassword = ' OR 1=1 --.
Which effectively turns into WHERE password = '' OR 1=1 --.
This is the basis for the tale of little Bobby Tables (xkcd).
Users should NEVER be able to directly impact the runnable query.
They can provide values, and those should be parameterized, or validated first.
The real problem is that people with SQL knowledge can string multiple lines of SQL together to manipulate the original query in some scary ways.
Blind Injection
Boolean
Boolean based attacks take time but the scripting throws errors if script results are true.
Example they provided is “If the first database starts with an A, throw”, “If the first database starts with a B, throw”, etc.
Time Based
Uses the Boolean based attack, but puts them on a delay so they won’t be as easily detected.
So you can just regular expressions for keywords and escape quotes right?! Ummm … no!
There’s just too many combinations of things you’d need to know as well as weird characters and tricks you couldn’t even be aware of, double or triple encoding, exceptions, etc.
It’s surprisingly tricky. For example, how would you allow single quotes? Replace them all with \'? Unless there’s already a \ in front of it, but what if it’s \?
You can theoretically overcome all of these problems … but … why? Why not just do it the right way?
The answer is to use prepared statements and/or parameterized queries.
The difference between a prepared statement and what was mentioned above is the user’s input doesn’t directly modify a query, rather the input is substituted in the appropriate place.
Side benefit is prepared statements often execute quicker than manually constructed SQL queries.
Vulnerability #2 – Storing Passwords
OWASP has the more generic “Cryptographic Failures” at #2, up from #3 in 2017.
Never store passwords in plain text!
I’ve heard hashing is good, right?
Kind of, until you hear that there’s this thing called rainbow tables.
Rainbow tables are basically dictionaries of passwords that have been hashed using various algorithms. This allows you to quickly look up a previously known password with a common hashing algorithm.
Using a salt:
This is essentially appending a random string of data to the end of a password before hashing it.
This salt must NEVER be reused, and it should be changed every time a password is created or changes.
The sole purpose of a salt is to ensure rainbow tables will be ineffective. The salts can be stored as plain text right next to the password, they are not a secret, they just ensure the hash will be different even if the same passwords are used multiple times.
Using “a” pepper:
They referred to it as a site-wide salt, which is pretty accurate.
The pepper does the same thing as the salt, it’s appended to every password before hashing.
The biggest difference is that the pepper is not stored alongside the data, rather it’s stored in a file on a server separate from the data.
Essentially you’re double-salting your password before hashing.
Password + Salt (stored next to the password with the data) + Pepper (stored on separate server), then hash.
Pepper can make it more difficult for hackers as if they steal the database, they still don’t have the pepper.
Pepper can also make it more difficult for the owners of the system as “rolling a pepper” can be difficult, and you have to potentially keep track of all historical peppers.
Even with the salts and peppers, this still doesn’t fully solve the problem. Why?
Can’t use a rainbow table, but … if a hacker has the salt and pepper, they can try to brute force the password hashes.
They can do this because depending on the hashing algorithm chosen, the hashing is just too fast: MD5, SHA-1, etc.
Those algorithms weren’t designed for security, they were designed for speed.
Solution: Key-stretching
This is running the password through a hash algorithm a large number of times.
The output of the first hash will be the input for the second hash, and so on.
The whole point is to make it take longer to hash. If you were to hash a password 100k times, it might take a second.
This means for a legit user, it’s going to take a second to hash and compare a login, but for a hacker trying to crack passwords, at MOST they’ll be able to do one attempt per second.
Following the math here, previously with a single MD5 or similar hash, the hacker could attempt 100k password cracks per second vs one per second.
It’s still not perfect. Hardware is constantly getting better. So what’s a good and slow today, may not be in a year.
Adaptive Hashing:
Same concepts as above, except you can increase the number of hashing rounds as time goes on.
Really what you want is the cost to hack a password for a given algorithm. PagerDuty had a nice slide on this that estimated the cost of hardware to crack a password in one year.
Good algorithms for increasing the cost to hackers are bcrypt, scrypt and PBKDF2.
These were designed for hashing passwords specifically.
Salting and key stretching are also built into the algorithms so you don’t have to go do it on your own.
Tip from Jamie Taylor: DockerSlim is a tool for slimming down your Docker images to reduce your image sizes and security foot print. You can minify it by up to 30x. Free and open-source. (GitHub)
Game Jam is coming up, checking out the free assets provided by Unity in the asset store. The quality is incredible and inspiring and the items range from art work to controllers (think FPS, 3P) to full “microgames” that you can take and build with till your heart’s content. Most are free and the one’s that aren’t are cheap and interesting. (assetstore.unity.com)
while True: learn() is a puzzle video game that can help teach you machine learning techniques. Thanks to Alex from GamingFyx for sharing this!
With Game Ja-Ja-Ja-Jamuary coming up, we discuss what makes a game engine, while Michael’s impersonation is spot-on, Allen may really just be Michael, and Joe already has the title of his next podcast show at the ready.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
Game Jam ’22 is coming up in Ja-Ja-Ja-Jamuary
News
Thanks for the reviews!
Podchaser: Jamie Introcaso
Game Ja-Ja-Ja-Jamuary is coming up, sign up is open now! (itch.io)
What is a Game Engine?
What’s a…
Library,
Framework,
Toolkit,
… Engine?
Want to see terrible explanations of a thing? Google “framework vs engine”.
Other types of engines: storage engine, rendering engine, for example.
Q: Why do people use game engines? Well, they reduce costs, complexities, and time-to-market. Consistency! Q: Why do so many AAA games create their own custom engines?
Common Features of Game Engines
2D/3D rendering engine
Basic shapes (planes, spheres, lines),
Particles, Shaders,
Masking/Culling,
Progressive enhancement (either by distance or by some other means)
Physics engine
Collision detection,
Mass,
Gravity,
Torque,
Force,
Friction,
Springiness,
Fluid Dynamics,
Wind
Sound
Multiple sounds at once, looping, spatial settings, etc.
Scripting
AI
Networking
Ever thought about how this works? Peer to peer, dedicated servers?
Streaming
Streaming assets, as in, the player hasn’t installed your game.
Scene Management
Cinematics
UI
Often engines also include development tools to making working with these various systems easier … like an IDE.
Many AAA games built with Unreal. Basically think of the top 10 biggest, most beautiful, AAA games; those are probably all Unreal or custom (RAGE, Frostbyte, Last of Us)
Pricing: from free to “call for pricing”, 5% royalty after $1mm
Blood, Sweat, and Pixels by Jason Schreier (Amazon)
Tip of the Week
ProBuilder is a free tool available in Unity that is great for making polygons and great for mocking out levels or building ramps. The coolest part is the way it works, giving you a bunch of tools that you do things like create vertices, edges, surfaces, extrude, intrude, mirror, etc. You have to add it via the package manager but it’s worth it for simple games and prototypes. (Unity)
Great blog on processing billions of events in real time at Twitter, thanks Mikerg! (blog.twitter.com)
forEachIndexed is a nice Kotlin method for iterating through items in a collection, with an index for positional based computations (ozenero.com)
How can you log out of Netflix on Samsung Smart TVs? Ever heard of the Konami code? Press Up Up Down Down Left Right Left Right Up Up Up Up (help.netflix.com)
We wrap up the discussion on partitioning from our collective favorite book, Designing Data-Intensive Applications, while Allen is properly substituted, Michael can’t stop thinking about Kafka, and Joe doesn’t live in the real sunshine state.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
News
Game Ja Ja Ja Jam is coming up, sign up is open now! (itch.io)
Joe finished the Create With Code Unity Course (learn.unity.com)
New MacBook Pro Review, notch be darned!
Last Episode …
Best book evar!
In our previous episode, we talked about data partitioning, which refers to how you can split up data sets, which is great when you have data that’s too big to fit on a single machine, or you have special performance requirements. We talked about two different partitioning strategies: key ranges which works best with homogenous, well-balanced keys, and also hashing which provides a much more even distribution that helps avoid hot-spotting.
This episode we’re continuing the discussion, talking about secondary indexes, rebalancing, and routing.
Partitioning, Part Deux
Partitioning and Secondary Indexes
Last episode we talked about key range partitioning and key hashing to deterministically figure out where data should land based on a key that we chose to represent our data.
But what happens if you need to look up data by something other than the key?
For example, imagine you are partitioning credit card transactions by a hash of the date. If I tell you I need the data for last week, then it’s easy, we hash the date for each day in the week.
But what happens if I ask you to count all the transactions for a particular credit card?
You have to look at every single record. in every single partition!
Secondary Indexes refer to metadata about our data that help keep track of where our data is.
In our example about counting a user’s transactions in a data set that is partitioned by date, we could keep a separate data structure that keeps track of which partitions each user has data in.
We could even easily keep a count of those transactions so that you could return the count of a user’s transaction solely from the information in the secondary index.
Secondary indexes are complicated. HBase and Voldemort avoid them, while search engines like Elasticsearch specialize in them.
There are two main strategies for secondary indexes:
Document based partitioning, and
Term based partitioning.
Document Based Partitioning
Remember our example dataset of transactions partitioned by date? Imagine now that each partition keeps a list of each user it holds, as well as the key for the transaction.
When you query for users, you simply ask each partition for the keys for that user.
Counting is easy and if you need the full record, then you know where the key is in the partition. Assuming you store the data in the partition ordered by key, it’s a quick lookup.
Remember Big O? Finding an item in an ordered list is O(log n). Which is much, much, much faster than looking at every row in every partition, which is O(n).
We have to take a small performance hit when we insert (i.e. write) new items to the index, but if it’s something you query often it’s worth it.
Note that each partition only cares about the data they store, they don’t know anything about what the other partitions have. Because of that, we call it a local index.
Another name for this type of approach is “scatter/gather”: the data is scattered as you write it and gathered up again when you need it.
This is especially nice when you have data retention rules. If you partition by date and only keep 90 days worth of data, you can simply drop old partitions and the secondary index data goes with them.
Term Based Partitioning
If we are willing to make our writes a little more complicated in exchange for more efficient reads, we can step up to term based partitioning.
One problem with having each partition keeping track of their local data is you have to query all the partitions. What if the data’s only on one partition? Our client still needs to wait to hear back from all partitions before returning the result.
What if we pulled the index data away from the partitions to a separate system?
Now we check this secondary index to figure out the keys, which we can then go look up on the appropriate indices.
We can go one step further and partition this secondary index so it scales better. For example, userId 1-100 might be on one, 101-200 on another, etc.
The benefit of term based partitioning is you get more efficient reads, the downside is that you are now writing to multiple spots: the node the data lives on and any partitions in our indexing system that we need to account for any secondary indexes. And this is multiplied by replication.
This is usually handled by asynchronous writes that are eventually consistent. Amazon’s DynamoDB states it’s global secondary indexes are updated within a fraction of a second normally.
Rebalancing Partitions
What do you do if you need to repartition your data, maybe because you’re adding more nodes for CPU, RAM, or losing nodes?
Then it’s time to rebalance your partitions, with the goals being to …
Distribute the load equally-ish (notice we didn’t say data, could have some data that is more important or mismatched nodes),
Keep the database operational during the rebalance procedure, and
Minimize data transfer to keep things fast and reduce strain on the system.
Here’s how not to do it: hash % (number of nodes)
Imagine you have 100 nodes, a key of 1000 hashes to 0. Going to 99 nodes, that same key now hashes to 1, 102 nodes and it now hashes to 4 … it’s a lot of change for a lot of keys.
Partitions > Nodes
You can mitigate this problem by fixing the number of partitions to a value higher than the number of nodes.
This means you move where the partitions go, not the individual keys.
Same recommendation applies to Kafka: keep the numbers of partitions high and you can change nodes.
In our example of partitioning data by date, with a 7 years retention period, rebalancing from 10 nodes to 11 is easy.
What if you have more nodes than partitions, like if you had so much data that a single day was too big for a node given the previous example?
It’s possible, but most vendors don’t support it. You’ll probably want to choose a different partitioning strategy.
Can you have too many partitions? Yes!
If partitions are large, rebalancing and recovering from node failures is expensive.
On the other hand, there is overhead for each partition, so having many, small partitions is also expensive.
Other methods of partitioning
Dynamic partitioning:
It’s hard to get the number of partitions right especially with data that changes it’s behavior over time.
There is no magic algorithm here. The database just handles repartitioning for you by splitting large partitions.
Databases like HBase and RethinkDB create partitions dynamically, while Mongo has an option for it.
Partitioning proportionally to nodes:
Cassandra and Ketama can handle partitioning for you, based on the number of nodes. When you add a new node it randomly chooses some partitions to take ownership of.
This is really nice if you expect a lot of fluctuation in the number of nodes.
Automated vs Manual Rebalancing
We talked about systems that automatically rebalance, which is nice for systems that need to scale fast or have workloads that are homogenized.
You might be able to do better if you are aware of the patterns of your data or want to control when these expensive operations happen.
Some systems like Couchbase, Riak, and Voldemort will suggest partition assignment, but require an administrator to kick it off.
But why? Imagine launching a large online video game and taking on tons of data into an empty system … there could be a lot of rebalancing going on at a terrible time. It would have been much better if you could have pre-provisioned ahead of time … but that doesn’t work with dynamic scaling!
Request Routing
One last thing … if we’re dynamically adding nodes and partitions, how does a client know who to talk to?
This is an instance of a more general problem called “service discovery”.
There are a couple ways to solve this:
The nodes keep track of each other. A client can talk to any node and that node will route them anywhere else they need to go.
Or a centralized routing service that the clients know about, and it knows about the partitions and nodes, and routes as necessary.
Or require that clients be aware of the partitioning and node data.
No matter which way you go, partitioning and node changes need to be applied. This is notoriously difficult to get right and REALLY bad to get wrong. (Imagine querying the wrong partitions …)
Apache ZooKeeper is a common coordination service used for keeping track of partition/node mapping. Systems check in or out with ZooKeeper and ZooKeeper notifies the routing tier.
Kafka (although not for much longer), Solr, HBase, and Druid all use ZooKeeper. MongoDb uses a custom ConfigServer that is similar.
Cassandra and Riak use a “gossip protocol” that spreads the work out across the nodes.
Elasticsearch has different roles that nodes can have, including data, ingestion and … you guessed it, routing.
Parallel Query Execution
So far we’ve mostly talked about simple queries, i.e. searching by key or by secondary index … the kinds of queries you would be running in NoSQL type situations.
What about? Massively Parallel Processing (MPP) relational databases that are known for having complex join, filtering, aggregations?
The query optimizer is responsible for breaking down these queries into stages which target primary/secondary indexes when possible and run these stages in parallel, effectively breaking down the query into subqueries which are then joined together.
That’s a whole other topic, but based on the way we talked about primary/secondary indexes today you can hopefully have a better understanding of how the query optimizer does that work. It splits up the query you give it into distinct tasks, each of which could run across multiple partitions/nodes, runs them in parallel, and then aggregates the results.
Designing Data-Intensive Applications goes into it in more depth in future chapters while discussing batch processing.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Tip of the Week
PowerLevel10k is a Zsh “theme” that adds some really nice features and visual candy. It’s highly customizable and works great with Kubernetes and Git. (GitHub)
If for some reason VS Code isn’t in your path, you can add it easily within VS Code. Open up the command palette (CTRL+SHIFT+P / COMMAND+SHIFT+P) and search for “path”. Easy peasy!
Gently Down the Stream is a guidebook to Apache Kafka written and illustrated in the style of a children’s book. Really neat way to learn! (GentlyDownThe.Stream)
PostgreSQL is one of the most powerful and versatile databases. Here is a list of really cool things you can do with it that you may not expect. (HakiBenita.com)
We crack open our favorite book again, Designing Data-Intensive Applications by Martin Kleppmann, while Joe sounds different, Michael comes to a sad realization, and Allen also engages “no take backs”.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
News
Thank you for the review!
iTunes: Wohim321
Best book evar!
The Whys and Hows of Partitioning Data
Partitioning is known by different names in different databases:
Shard in MongoDB, ElasticSearch, SolrCloud,
Region in HBase,
Tablet in BigTable,
vNode in Cassandra and Riak,
vBucket in CouchBase.
What are they?
In contrast to the replication we discussed, partitioning is spreading the data out over multiple storage sections either because all the data won’t fit on a single storage mechanism or because you need faster read capabilities.
Typically data records are stored on exactly one partition (record, row, document).
Each partition is a mini database of its own.
Why partition? Scalability
Different partitions can be put on completely separate nodes.
This means that large data sets can be spread across many disks, and queries can be distributed across many processors.
Each node executes queries for its own partition.
For more processing power, spread the data across more nodes.
Examples of these are NoSQL databases and Hadoop data warehouses.
These can be set up for either analytic or transactional workloads.
While partitioning means that records belong to a single partition, those partitions can still be replicated to other nodes for fault tolerance.
A single node may store more than one partition.
Nodes can also be a leader for some partitions and a follower for others.
They noted that the partitioning scheme is mostly independent of the replication used.
Figure 6-1 in the book shows this leader / follower scheme for partitioning among multiple nodes.
The goal in partitioning is to try and spread the data around as evenly as possible.
If data is unevenly spread, it is called skewed.
Skewed partitioning is less effective as some nodes work harder while others are sitting more idle.
Partitions with higher than normal loads are called hot spots.
One way to avoid hot-spotting is putting data on random nodes.
Problem with this is you won’t know where the data lives when running queries, so you have to query every node, which is not good.
Partitioning by Key Range
Assign a continuous range of keys on a particular partition.
Just like old encyclopedias or even the rows of shelves in a library.
By doing this type of partitioning, your database can know which node to query for a specific key.
Partition boundaries can be determined manually or they can be determined by the database system.
Automatic partition is done by BigTable, HBase, RethinkDB, and MongoDB.
The partitions can keep the keys sorted which allow for fast lookups. Think back to the SSTables and LSM Trees.
They used the example of using timestamps as the key for sensor data – ie YY-MM-DD-HH-MM.
The problem with this is this can lead to hot-spotting on writes. All other nodes are sitting around doing nothing while the node with today’s partition is busy.
One way they mentioned you could avoid this hot-spotting is maybe you prefix the timestamp with the name of the sensor, which could balance writing to different nodes.
The downside to this is now if you wanted the data for all the sensors you’d have to issue separate range queries for each sensor to get that time range of data.
Some databases attempt to mitigate the downsides of hot-spotting. For example, Elastic has the ability specify an index lifecycle that can move data around based on the key. Take the sensor example for instance, new data comes in but the data is rarely old. Depending on the query patterns it may make sense to move older data to slower machines to save money as time marches on. Elastic uses a temperature analogy allowing you to specify policies for data that is hot, warm, cold, or frozen.
Partitioning by Hash of the Key
To avoid the skew and hot-spot issues, many data stores use the key hashing for distributing the data.
A good hashing function will take data and make it evenly distributed.
Hashing algorithms for the sake of distribution do not need to be cryptographically strong.
Mongo uses MD5.
Cassandra uses Murmur3.
Voldemort uses Fowler-Noll-Vo.
Another interesting thing is not all programming languages have suitable hashing algorithms. Why? Because the hash will change for the same key. Java’s object.hashCode() and Ruby’s Object#hash were called out.
Partition boundaries can be set evenly or done pseudo-randomly, aka consistent hashing.
Consistent hashing doesn’t work well for databases.
While the hashing of keys buys you good distribution, you lose the ability to do range queries on known nodes, so now those range queries are run against all nodes.
Some databases don’t even allow range queries on the primary keys, such as Riak, Couchbase, and Voldemort.
Cassandra actually does a combination of keying strategies.
They use the first column of a compound key for hashing.
The other columns in the compound key are used for sorting the data.
This means you can’t do a range query over the first portion of a key, but if you specify a fixed key for the first column you can do a range query over the other columns in the compound key.
An example usage would be storing all posts on social media by the user id as the hashing column and the updated date as the additional column in the compound key, then you can quickly retrieve all posts by the user using a single partition.
Hashing is used to help prevent hot-spots but there are situations where they can still occur.
Popular social media personality with millions of followers may cause unusual activity on a partition.
Most systems cannot automatically handle that type of skew.
In the case that something like this happens, it’s up to the application to try and “fix” the skew. One example provided in the book included appending a random 2 digit number to the key would spread that record out over 100 partitions.
Again, this is great for spreading out the writes, but now your reads will have to issue queries to 100 different partitions.
Couple examples:
Sensor data: as new readings come in, users can view real-time data and pull reports of historical data,
Multi-tenant / SAAS platforms,
Giant e-commerce product catalog,
Social media platform users, such as Twitter and Facebook.
The first Google computer at Stanford was housed in custom-made enclosures constructed from Mega Blocks. (Wikipedia)
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
VS Code lets you open the search results in an editor instead of the side bar, making it easier to share your results or further refine them with something like regular expressions.
Apple Magic Keyboard (for iPad Pro 12.9-inch – 5th Generation) is on sale on Amazon. Normally $349, now $242.99 on Amazon and Best Buy usually matches Amazon.(Amazon)
Compatible Devices:
iPad Pro 12.9-inch (5th generation),
iPad Pro 12.9-inch (4th generation),
iPad Pro 12.9-inch (3rd generation)
Room EQ Wizard is free software for room acoustic, loudspeaker, and audio device measurements. (RoomEQWizard.com)
The Mathemachicken strikes again for this year’s shopping spree, while Allen just realized he was under a rock, Joe engages “no take backs”, and Michael ups his decor game.
Samsung Is the Latest SSD Manufacturer Caught Cheating Its Customers (ExtremeTech.com)
Tip of the Week
VS Code … in the browser … just … there? Not all extensions work, but a lot do! (VSCode.dev)
Skaffold is a tool you can use to build and maintain Kubernetes environments that we’ve mentioned on the show several times and guess what!? You can make your life even easier with Skaffold with environment variables. It’s another great way to maintain flexibility for your environments … both local and CI/CD. (Skaffold.dev)
K9s is a Kubernetes terminal UI that makes it easy to quickly search, browse, filter, and edit your clusters and it also has skins! The Solarized Light theme is particularly awesome for customizing your experience, especially for presenting. (GitHub)
We discuss the pros and cons of speaking at conferences and similar events, while Joe makes a verbal typo, Michael has turned over a new leaf, and Allen didn’t actually click the link.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says
News
The Kinesis Gaming Freestyle Edge RGB Split Mechanical Keyboard might be the current favorite.
Thank you to everyone that left a review!
iTunes: dahol1337, Pesri
How long does it take to get the Moonlander? (ZSA.io)
Is the Kinesis Gaming Freestyle the current favorite? (Amazon)
Atlanta Code Camp was fantastic, see you again next year! (atlantacodecamp.com)
What kind of speaking are we talking about?
Conferences
Meetups
Does YouTube/Twitch count as tech presentations?
There are some similarities! Streaming has the engagement, but generally isn’t as rehearsed. Published videos are closer to the format but you have to make some assumptions about your audience and can get creative with the editing.
Risk Astley – Never Gonna Give You Up (Official Music Video) (YouTube)
Simple Minds – Don’t You (Forget About Me) (YouTube)
Foo Fighters With Rick Astley – Never Gonna Give You Up – London O2 Arena 19 September 2017 (YouTube)
Tip of the Week
Next Meeting is a free app for macOS that keeps a status message up in the top right of your toolbar so you know when your next meeting is. It does other stuff too, like making it easier to join meetings and see your day’s events but … the status is enough to warrant the install. Thanks MadVikingGod! (Mac App Store)
How do I disable “link preview” in iOS safari? (Stack Exchange)
Here is your new favorite YouTube channel, Rick Beato is a music professional who makes great videos about the music you love, focusing on what makes the songs and artists special. (YouTube)
Hot is a free app for macOS that shows you the temperate of your MacBook Pro … and the percentage of CPU you’re limited to because of the heat! Laptop feels slow? Maybe it’s too hot! (GitHub, XS-Labs)
What is the meaning of $? in a shell script? (Stack Exchange)
Did you know…You can install brew on Linux? That’s right, the popular macOS packaging software is available on your favorite distro. (docs.brew.sh, brew.sh)
Joe goes full shock jock, but only for a moment. Allen loses the "Most Tips In A Single Episode: 2021" award, and Michael didn't get the the invite notification in this week's episode.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Shortcut - Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says
Well...no survey this week, but this is where it would be!
News
This book has a whole chapter on transactions in distributed systems
Thank you to everyone that left a review!
"Podchaser: alexi*********, Nicholas G Larsen, Kubernutties,
Audible: Anonymous (we are like your mother - go clean your room and learn Docker)
Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Maintaining data consistency
Each service should have its own data store
What about transactions? microservices.io suggests the saga pattern (website)
A sequence of local transactions must occur
Order service saves to its data store, then sends a message that it is done
Customer service attempts to save to its data store…if it succeeds, the transaction is done. If it fails, it sends a message stating so, and then the Order service would need to run another update to undo the previous action
Sound complicated? It is…a bit, you can't rely on a standard 2 Phase Commit at the database level to ensure an atomic transaction
Ways to achieve this - choreography or orchestration
Choreography Saga
- The Order Service receives the POST /orders request and creates an Order in a PENDING state - It then emits an Order Created event - The Customer Service’s event handler attempts to reserve credit - It then emits an event indicating the outcome - The OrderService’s event handler either approves or rejects the Order
Each service's local transaction sends a domain event that triggers another service's local transaction
To sum things up, each service knows where to listen for work it should do, and it knows where to publishes the results of it's work. It's up to the designers of the system to set things up such that the right things happened
What's good about this approach?
"The code I wrote sux. The code I'm writing is cool. The code I'm going to write rocks!"
Thanks for the paraphrase Mike!
Orchestration Saga
- The Order Service receives the POST /orders request and creates the Create Order saga orchestrator - The saga orchestrator creates an Order in the PENDING state - It then sends a Reserve Credit command to the Customer Service - The Customer Service attempts to reserve credit - It then sends back a reply message indicating the outcome - The saga orchestrator either approves or rejects the Order
There is an orchestrator object that tells each service what transaction to run
The difference between Orchestration and Choreography is that the orchestration approach has a "brain" - an object that centralizes the logic and can make more advanced changes
These patterns allow you to maintain data consistency across multiple services
The programming is quite a bit more complicated - you have to write rollback / undo transactions - can't rely on ACID types of transactions we've come to rely on in databases
Other issues to understand
The service must update the local transaction AND publish the message / event
The client that initiates the saga (asynchronously) needs to be able to determine the outcome
The service sends back a response when the saga completes
The service sends back a response when the order id is created and then polls for the status of the overall saga
The service sends back a response when the order id is created and then submits an event via a webhook or similar when the saga completes
When would you use Orchestration vs Choreography for transactions across Microservices?
Friend of the show @swyx works for Temporal, a company that does microservice orchestration as a service, https://temporal.io/
Mentions using separate data storage / dbs per service
Can't hide implementation from other services if they can see what's happening behind the scenes - leads to tight coupling
Share as little code as possible
Tempting to share things like customer objects, but doing so tightly couples the various microservices
Better to nearly duplicate those objects in a NON-shared way - that way the services can change independently
Avoid synchronous communication where possible
This means relying on message brokers, polling, callbacks, etc
Don't use shared test environments / appliances
May not sound right, but sharing a service may lead to problems - like multiple services using the same test service could introduce performance problems
Share as little domain data as possible - ie. important pieces of information shouldn't be passed around various services in domain objects. Only the bits of information necessary should be shared with each service - ie an order number or a customer number. Just enough to let the next microservice be able to do its job
Podman is an open-source containerization tool from Red Hat that provides a drop in replacement for Docker (they even recommend aliasing it!). The major difference is in how it works underneath, spawning process directly rather than relying on resident daemons. Additionally, podman was designed in a post Kubernetes world, and it has some additional tooling that makes it easier to transition to Kubernetes- like being able to spawn pods and generate Kubernetes yaml files. Website
Check out this episode from Google's Kubernetes podcast all about it: Podcast
Unity is the most popular game engine and they have a ton of resources in their Learning Center. Including one that is focused on writing code. It walks you through writing 5 microgames with hands on exercises where you fix projects and ultimately design and write your own simple game. Also it's free! https://learn.unity.com/course/create-with-code
Bonus: Make sure you subscribe to Jason Weimann's YouTube channel if you are interested in making games. Brilliant coder and communicator has a wide variety of videos: YouTube
Educative.io has been a sponsor of the show before and we really like their approach to hands on teaching so Joe took a look to see if they had any resources on C++ since he was interested in possibly pursuing competitive programming. Not only do they have C++ courses, but they actually have a course specifically for Competitive Programming in C++. Great for devs who already know a programming language and are wanting to transition without having to start at step 1. Educative Course
The most recent Coding Blocks Mailing List contest asked for "Summer Song" recommendations, we compiled them into a Spotify Summer Playlist. These are songs that remind you of summer, and don't worry we deduped the list so there is only one song from Rick Astley on there. Spotify
Finally, one special recommendation for Coding Music. It's niche, for sure, but if you like coding to instrumental rock/hard-rock then you have to check out a 2018 album from a band called Night Verses. It's like Russian Circles had a baby with the Mercury Program. If you are familiar with either of those bands, or just want something different then make sure to check it out. Spotify
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Shortcut – Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says
News
Thank you to everyone that left a review!
iTunes: Badri Ravi
Audible: Dysrhythmic, Brent
Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Docker Announcement
Docker recently announced big changes to the licensing terms and pricing for their product subscriptions. These changes would mean some companies having to pay a lot more to continue using Docker like they do today. So…what will will happen? Will Docker start raking in the dough or will companies abandon Docker?
Resources
Docker is Updating and Extending Our Product Subscriptions (Docker)
Minkube documentation (Thanks MadVikingGod! From the Tips n’ Tools channel in Slack.)
Open Container Initiative, an open governance structure for the purpose of creating open industry standards around container formats and runtimes. (opencontainers.org)
Podman, a daemonless container engine for developing, managing, and running OCI containers. (podman.io)
How do you decide when it’s time to go back to school or get a certification? What are the determining factors for making those decisions?
Full-Stack Road Map
What’s on your roadmap? We found a full-stack roadmap on dev.to and it’s got some interesting differences from other roadmaps we’ve seen or the roadmaps we’ve made. What are those differences?
Last year’s MacBook Pros introduced new M1 processors based on a RISC architecture. Now Apple is rolling out the rest of the line. What does this mean for devs? Is there a chance you will regret purchasing one of these laptops?
Resources
Apple Silicon M1: A Developer’s Perspective (steipete.com)
Tip of the Week
Hit . (i.e. the period key) in GitHub to bring up an online VS Code editor while you are logged in. Thanks Morten Olsrud! (blog.yogeshchavan.dev)
Shoutout to Coder, cloud-powered development environments that feel local. (coder.com)
The podcast that puts together the the “perfect album” for the topic du jour: The Perfect Album Side Podcast (iTunes, Spotify, Google Podcasts)
Bon Jovi – Livin’ On A Prayer / Wanted Dead Or Alive (Los Angeles 1989) (YouTube)
Docker’s system prune command now includes a filter option to easily get rid of older docker resources. (docs.docker.com)
Example: docker system prune --filter="until=72h"
The GitHub CLI makes it easy to create PR by autofilling information, as well as pushing your branch to origin:
Apache jclouds is an open-source multi-cloud toolkit that abstracts the details of your cloud provider away so you can focus on your code and still support multiple providers. (jclouds.apache.org)
We step away from our microservices deployments to meet around the water cooler and discuss the things on our minds, while Joe is playing Frogger IRL, Allen “Eeyores” his way to victory, and Michael has some words about his keyvoard, er, kryboard, leybaord, ugh, k-e-y-b-o-a-r-d!
RethinkDB, the open-source database for the realtime web. (RethinkDB.com)
Tip of the Week
Learn C the Hard Way: Practical Exercises on the Computational Subjects You Keep Avoiding (Like C) by Zed Shaw (Amazon)
With Windows Terminal installed:
In File Explorer, right click on or in a folder and select Open in Windows Terminal.
Right click on the Windows Terminal icon to start a non-default shell.
SonarLint is a free and open source IDE extension that identifies and helps you fix quality and security issues as you code. (SonarLint.org)
Use docker buildx to create custom builders. Just be sure to call docker buildx stop when you’re done with it. (Docker docs: docker buildx, docker buildx stop)
We decide to dig into the details of what makes a microservice and do we really understand them as Joe tells us why we really want microservices, Allen incorrectly answers the survey, and Michael breaks down in real time.
Each services talks to a separate backend database – i.e., inventory service talks to inventory DB, etc.
Fronting those micro-services are a couple of API’s – a mobile gateway API and an API that serves a website When an order is placed, a request is made to the mobile API to place the order, the mobile API has to make individual calls to each one of the individual micro-services to get / update information regarding the order
This setup is in contrast to a monolithic setup where you’d just have a single API that talks to all the backends and coordinates everything itself
NeoVim is a fork of Vim 7 that aims to address some technical debt in vim in hopes of speeding up maintenance, plugin creation, and new features. It supports RPC now too, so you can write vim plugins in any language you want. It also has better support for background jobs and async tasks. Apparently the success of nvim has also led to some of the more popular features being brought into vim as well. Thanks Claus/@komoten! (neovim.io)
Portable Apple Watch charger lets you charge your watch wirelessly from an outlet, or a usb. Super convenient! (Amazon)
Free book from Linode explaining how to secure your Docker containers. Thanks Jamie! (Linode)
There is a daily.dev plugin for Chrome that gives you the dev home page you deserve, delivering you dev news by default. Thanks @angryzoot! (Chrome Web Store)
SonarQube is an open-source tool that you can run on your code to pull metrics on it’s quality. And it’s available for you to run in docker Thanks Derek Chasse! (hub.docker.com)
We dive into JetBrains’ findings after they recently released their State of the Developer Ecosystem for 2021 while Michael has the open down pat, Joe wants the old open back, and Allen stopped using the command line.
Atlanta Code Camp is coming up October 9th, come hang out at the CB booth!
Check out Allen’s Quick Tips!
Why JetBrains?
JetBrains has given us free licenses to give out for years now. Sometimes people ask us what it is that we like about their products, especially when VS Code is such a great (and 100% free) experience…so we’ll tell ya!
JetBrains produces (among other things) a host of products that are all based on the same IDEA platform, but are custom tailored for certain kinds of development. CLion for C, Rider for C#, IntelliJ for JVM, WebStorm for front-end, etc. These IDEs support plugins but they come stocked with out-of-the-box functionality that you would have to add via plugins in a generalized Editor or IDE
This also helps keep consistency amongst developers…everybody using the same tools for git, databases, formatting, etc
Integrated experience vs General Purpose Tool w/ Plugins, Individual plugins allow for a lot of innovation and evolution, but they aren’t designed to work together in the same way that you get from an integrated experience.
JetBrains has assembled a great community
Supporting user groups, podcasts, and conferences for years with things like personal licenses
Great learning materials for multiple languages (see the JetBrains Academy)
Community (free) versions of popular products (Android Studio, IntelliJ, WebStorm, PyCharm)
Advanced features that have taken many years of investment and iteration (Resharper/Refactoring tools)
TL;DR JetBrains has been making great products for 20 years, and they are still excelling because those products are really good!
Survey was comprised of 31,743 developers from 183 countries. JetBrains attempted to get a wide swath of diverse responses and they weighted the results in an attempt to get a realistic view of the world. Read more about the methodology
What would you normally expect from JetBrain’s audience? (Compare to surveys from StackOverflow or Github or State of JS)
JetBrains are mainly known for non-cheap, heavy duty tools so you might expect to see more senior or full time employees than StackOverlow, but that’s not the case…it skews younger
Professional / Enterprise (63% full-time, 70.9% on latest Stack Overflow)
JetBrains 3-5 vs StackOverflow 5-9 years of experience
Free audiobook/album from the Software Daily host: Move Fast: How Facebook Builds Software (softwareengineeringdaily.com)
Apple has great features and documentation on the different ways to take screenshots in macOS (support.apple.com)
Data, Data, Data: Let the data guide your decisions. Not feelings.
HTTPie is a utility built in Python that makes it really issue to issue web requests. CURL is great…but it’s not very user friendly. Give HTTPie a shot! (httpie.io)
It’s time to take a break, stretch our legs, grab a drink, and maybe even join in some interesting conversations around the water cooler as Michael goes off script, Joe is very confused, and Allen insists that we stay on script.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says
News
We really appreciate the latest reviews, so thank you!
iTunes: EveryNickIsTaken2858, Memnoch97
Allen finished his latest ergonomic keyboard review: Moonlander Ergonomic Keyboard Long Term Review (YouTube)
Sadly, the .http files tip from episode 161 for JetBrains IDEs is only application for JetBrains’ Ultimate version.
In short, it’s a VS Code Extension that leverages the OpenAI Codex, a product that translates natural language to code, in order to … wait for it … write code. It’s currently in limited preview.
What’s the value?
Is the code correct? Github says ~40-50% in some large scale test cases
It works best with small, documented functions
Does having the code written for you steer you towards solutions?
Could this encourage similar bugs/security holes across multiple languages by people importing the same code?
Is this any different from developers using the same common solutions from StackOverflow?
Could it become a crutch for new developers?
Better for certain kinds of code? (Boiler plate, common accessors, date math)
Boiler Plate (like angular / controller vars)
Common APIs (Twitter, Goodreads)
Common Algorithms, Design Patterns
Less Familiar Languages
But is it useful? We’ll see!
Is this the future?
We see more low, no, and now co-code solutions all the time, is this where things are going?
This probably won’t be “it”, but maybe we will see things like this more commonly – in any case it’s different, why not give it a shot?
Is it Ethical?
The “AI” or whatever has been trained on “billions of lines” of open-source code…but not strictly permissive licenses. This means a dev using this tool runs the risk of accidently including proprietary code
Quake Engine Source Code Example (GPLv2) (Twitter)
54 million public software repositories hosted on GitHub as of May 2020 (for Python) 179GB of unique Python files under 1MB in size. Some basic limitations on line and file length, sanitization: The final training dataset totaled 159GB.
There is problem with bias, especially in more niche categories
Is it ethical to use somebody else’s data to train an AI without their permission?
Can it get you sued?
Would your thoughts change if the data is public? License restricted?
Would your thoughts change if the product/model were open-sourced?
Abstractions… how far is too far?
Services should communicate with datastores and services via APIs that hide the details, these provide for a nice indirection that allows for easier maintenance in the future
Do you abstract at the service level or the feature level?
Are ORMs a foregone conclusion?
What about services that have a unique communication pattern, or assist with cross cutting concerns for things like microservices (We are looking at you hear Kafka!)
The 10 Best Practices for Remote Software Engineering
From article: The 10 Best Practices for Remote Software Engineering (ACM)
Some of Michael’s (Linux/macOS) favorites from the article:
Abbreviate your directories with tab completion when changing directories, such as cd /v/l/a, and assuming that that abbreviated path can uniquely identify something like, /var/logs/apache, tab completion will take care of the rest.
Use nl to get a numbered list of some previous command’s output, such as ls -l | nl.
ERRATUM: During the episode, Michael mentioned that the output would first list the total lines, but that just happened to be due to output from ll and was unrelated to the output from nl.
On macOS, you can use the powermetrics command to gain access to all sorts of metrics related to the internals of your computer, such as the temperature at various sensors.
Use !! to repeat the last command. This can be especially helpful when you want to do something like prepend/append the previous command, such as sudo !!.
ERRATUM: Wow, Michael really got this one wrong during the episode. It doesn’t repeat the “last sudo command” nor does it leave the command in edit mode. Listen to Allen’s description. /8)
Awesome keyboard shortcuts:
CTRL+A takes you to the start of the line and CTRL+E takes you to the end.
No need to type clear any longer as CTRL+L will clear your screen.
CTRL+U deletes the content to the left of the cursor and CTRL+K deletes the content to the right of the cursor.
Made a mistake in while typing your command? Use CTRL+SHIFT+- to undo what you last typed.
Using the history command, you can see your previous commands and even limit it with a negative number, such as history -5 to see only the last five commands.
Tip of the Week
Partial Diff is a VS Code extension that makes it easy to compare text. You can right click to compare files or even blocks of text in the same file, as well as in different files. (Visual Studio Marketplace)
StackBlitz is an online development environment for full stack applications. (StackBlitz.com)
Microcks, an open source Kubernetes native tool for API mocking and testing. (Microcks.io)
Bridging the HTTP protocol to Apache Kafka (Strimzi.io)
Difference Between grep, sed, and awk (Baeldung.com)
As an alternative to the ruler hack mentioned in episode 161, there are several compact, travel ready laptop stands. (Amazon)
We wrap up our replication discussion of Designing Data-Intensive Applications, this time discussing leaderless replication strategies and issues, while Allen missed his calling, Joe doesn’t read the gray boxes, and Michael lives in a future where we use apps.
If you’re reading this via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode162. As Joe would say, check it out and join in on the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says
News
Thank you for the latest review!
iTunes: tuns3r
Check out the book!
Single Leader to Multi-Leader to Leaderless
When you have leaders and followers, the leader is responsible for making sure the followers get operations in the correct order
Dynamo brought the trend to the modern era (all are Dynamo inspired) but also…
What if we just let every replica take writes? Couple ways to do this…
You can write to several replicas
You can use a coordinator node to pass on the writes
But how do you keep these operations in order? You don’t!
Thought exercise, how can you make sure operation order not matter?
Couple ideas: No partial updates, increments, version numbers
Multiple Writes, Multiple Reads
What do you do if your client (or coordinator) try to write to multiple nodes…and some are down?
Well, it’s an implementation detail, you can choose to enforce a “quorom”. Some number of nodes have to acknowledge the write.
This ratio can be configurable, making it so some % is required for a write to be accepted
What about nodes that are out of date?
The trick to mitigating stale data…the replicas keep a version number, and you only use the latest data – potentially by querying multiple nodes at the same time for the requested data
We’ve talked about logical clocks before, it’s a way of tracking time via observed changes…like the total number of changes to a collection/table…no timezone or nanosecond differences
How do you keep data in sync?
About those unavailable nodes…2 ways to fix them up
Read Repair: When the client realizes it got stale data from one of the replicas, it can send the updated data (with the version number) back to that replica. Pretty cool! – works well for data that is read frequently
Anti-Entropy: The nodes can also do similar background tasks, querying other replicas to see which are out of data – ordering not guaranteed!
Voldemort: ONLY uses read repair – this could lead to loss of data if multiple replicas went down and the “new” data was never read from after being written
Quorums for reading and writing
Quick Reminder: We are still talking about 100% of the data on each replica
3 major numbers at play:
Number of nodes
Number of confirmed writes
Number of reads required
If you want to be safe, the nodes you write to and the ones you write too should include some overlap
A common way to ensure that, keep the number of writes + the number of reads should be greater than the number of nodes
Example: You have 10 nodes – if you use 5 for writing and 5 for reading…you may not have an overlap resulting in potentially stale data!
Common approach – taken number of nodes (odd number) + 1, then divide that number by 2 and that’s the number of reader and writers you should have
9 Nodes – 5 writes and 5 reads – ensures non-stale data
When using this approach, you can handle Nodes / 2 (rounded down) number of failed nodes
How would you tweak the numbers for a write heavy workload?
Typically, you write and read to ALL replicas, but you only need a successful response from these numbers
What if you have a LOT of nodes?!?
Note: there’s still room for problems here – author explicitly lists 5 types of edge cases, and one category of miscellaneous timing edge cases. All variations of readers and writers getting out of sync or things happen at the same timing
If you really want to be safe, you need consensus (r = w = n) or transactions (that’s a whole other chapter)
Note that if the number of required readers or writers doesn’t return an OK, then an error is returned from the operation
Also worth considering is you don’t have to have overlap – having readers + writers < nodes means you could have stale data, but at possibly lower latencies and lower probabilities of error responses
Monitoring staleness
Single/Multi Leader lag is generally easy to monitor – you just query the leader and the replicas to see which operation they are on
Leaderless databases don’t have guaranteed ordering so you can’t do it this way
If the system only uses read repair (where the data is fixed up by clients only as it is read) then you can have data that is ancient
It’s hard to give a good algorithm description here because so much relies on the implementation details
Multi-writes and multi-reads are great when a small % of nodes or down, or slow
What if that % is higher?
Return an error when we can’t get quorum?
Accept writes and catch the unavailable nodes back up later?
If you choose to continue operating, we call it “sloppy quorum” – when you allow reads or writes from replicas that aren’t the “home” nodes – the likened it to you got locked out of your house and you ask your neighbor if you can stay at their place for the night
This increases (write) availability, at the cost of consistency
Technically it’s not a quorum at all, but it’s the best we can do in that situation if you really care about availability – the data is stored somewhere just not where it’d normally be stored
Detecting Concurrent Writes
What do you get when you write the same key at the same time with different values?
Remember, we’re talking about logical clocks here so imagine that 2 clients both write version #17 to two different nodes
This may sound unlikely, but when you realize we’re talking logical clocks, and systems that can operate at reduced capacity…it happens
What can we do about it?
Last write wins: But which one is considered last? Remember, how we catch up? (Readers fix or leaders communicate) …either way, the data will eventually become consistent but we can’t say which one will win…just that one will eventually take over
Note: We can take something else into account here, like clock time…but no perfect answer
LWW is good when your data is immutable, like logs – Cassandra recommends using a UUID as a key for each write operation
Happens-Before Relationship – (Riak has CfRDT that bundle a version vector to help with this)
This “happens-before” relationship and concurrency
How do we know whether the operations are concurrent or not? Basically if neither operation knows about the other, then they are concurrent…
Three possible states if you have writes A and B
A happened before B
B happened before A
A and B happened concurrently
When there is a happens before, then you take the later value
When they are concurrent, then you have to figure out how to resolve the conflicts
Merging concurrently written values
Last write wins?
Union the data?
No good answer
Version vectors
The collection of version numbers from all replicas is called a version vector
Riak uses dotted version vectors – the version vectors are sent back to the clients when values are read, and need to be sent back to the db when the value is written back
Doing this allows the db to understand if the write was an overwrite or concurrent
This also allows applications to merge siblings by reading from one replica and write to another without losing data if the siblings are merged correctly
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
Designing Data-Intensive Applications – Data Models: Relational vs Document (episode 123)
A GitHub repo for a list of “falsehoods”: common things that people believe but aren’t true, but targeted at the kinds of assumptions that programmers might make when they are working on domains they are less familiar with. (GitHub)
The Linux at command lets you easily schedule commands to run in the future. It’s really user friendly so you can be lazy with how you specify the command, for example echo "command_to_be_run" | at 09:00 or at 09:00 -f /path/to/some/executable (linuxize.com)
The Docker COPY cmd will need to be run if there are changes to files that are being copied. You can use a .dockerignore to skip files that you don’t care about to trim down on unnecessary work and build times. (doc.docker.com).
We continue our discussion of Designing Data-Intensive Applications, this time focusing on multi-leader replication, while Joe is seriously tired, and Allen is on to Michael’s shenanigans.
For anyone reading this via their podcast player, this episode’s show notes can be at https://www.codingblocks.net/episode161, where you can join the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
When you’re talking about single or multi-leader replication, remember all writes go through leaders
If your application is read heavy, then you can add followers to increase your scalability
That doesn’t work well with sync writes..the more followers, the higher the latency
The more nodes the more likely there will be a problem with one or more
The upside is that your data is consistent
The problem is if you allow async writes, then your data can be stale. Potentially very stale (it does dial up the availability and perhaps performance)
You have to design your app knowing that followers will eventually catch up – “eventual consistency“
“Eventual” is purposely vague – could be a few seconds, could be an hour. There is no guarantee.
Some common use cases make this particularly bad, like a user updating some information…they often expect to see that change afterwards
There are a couple techniques that can help with this problem
Techniques for mitigation replication lag
Read You Writes Consistency refers to an attempt to read significant data from leader or in sync replicas by the user that submitted the data
In general this ensures that the user who wrote the data will get the same data back – other users may get stale version of the data
But how can you do that?
Read important data from a leader if a change has been made OR if the data is known to only be changeable by that particular user (user profile)
Read from a leader/In Sync Replica for some period of time after a change
Client can keep a timestamp of it’s most recent write, then only allow reads from a replica that has that timestamp (logical clocks keep problems with clock synchronization at bay here)
But…what if the user is using multiple devices?
Centralize MetaData (1 leader to read from for everything)
You make sure to route all devices for a user the same way
Monotonic Reads: a guarantee of sorts that ensures you won’t see data moving backwards in time. One way to do this – keep a timestamp of the most recent read data, discard any reads older than that…you may get errors, but you won’t see data older than you’ve already seen.
Another possibility – ensure that the reads are always coming from the same replica
Consistent Prefix Reads: Think about causal data…an order is placed, and then the order is shipped…but what if we had writes going to more than one spot and you query the order is shipped..but nothing was placed? (We didn’t have this problem with a Single Replica)
We’ll talk more about this problem in a future episode, but the short answer is to make sure that causal data gets sent to the same “partition”
Replication isn’t as easy as it sounds, is it?
Multi-Leader Rep…lication
Single leader replication had some problems. There was a single point of failure for writes, and it could take time to figure out the new leader. Should the old leader come back then…we have a problem. Multi-Leader replication…
Allows more than one node to receive writes
Most things behave just like single-leader replication
Each leader acts as followers to other leaders
When to use Multi-Leader Replication
Many database systems that support single-leader replication can be taken a step further to make them mulit-leader. Usually. you don’t want to have multiple leaders within the same datacenter because the complexity outweighs the benefits.
When you have multiple leaders you would typically have a leader in each datacenter
An interesting approach is for each datacenter to have a leader and followers…similar to the single leader. However, each leader would be followers to the other datacenter leaders
Sort of a chained single-leader replication setup
Comparing Single-Leader vs Multi-Leader Replication
Performance – because writes can occur in each datacenter without having to go through a single datacenter, latency can be greatly reduced in multi-leader
The synchronization of that data across datacenters can happen asynchronously making the system feel faster overall
Fault tolerance – in single-leader, everything is on pause while a new leader is elected
In multi-leader, the other datacenters can continue taking writes and will catch back up when a new leader is selected in the datacenter where the failure occurred Network problems
Usually a multi-leader replication is more capable of handling network issues as there are multiple data centers handling the writes – therefore a major issue in one datacenter doesn’t cause everything to take a dive
So it’s clear right? Multi-leader all the things? Hint: No!
Problems with Multi-Leader Replication
Changes to the same data concurrently in multiple datacenters has to be resolved – conflict resolution – to be discussed later
Google Docs, Etherpad, Changes are saved to the “local” version that’s open per user, then changes are synced to a central server and pushed out to other users of the document
Conflict resolution
One of the problems with multi-leader writes is there will come times when there will be conflicting writes when two leaders write to the same column in a row with different values
How do you solve this?
If you can automate, you should because you don’t want to be putting this together by hand
Make one leader more important than the others
Make certain writes always go through the same data centers
It’s not easy – Amazon was brought up as having problems with this as well
Multi-Leader Replication Toplogogies
A replication topology describes how replicas communicate
Two leaders is easy
Some popular topologies:
Ring: Each leader reads from “right”, writes to the “left”
All to All: Very Chatty, especially as you add more and more nodes
Star: 1 special leader that all other leaders read from
Depending on the topology, a write may need to pass through several nodes before it reaches all replicas
How do you prevent infinite loops? Tagging is a popular strategy
If you have a star or circular topology, then a single node failure can break the flow
All to all is safest, but some networks are faster than others that can cause problems with “overrun” – a dependent change can get recorded before the previous
You can mitigate this by keeping “version vectors”, kind of logical clock you can use to keep from getting too far ahead
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
.http files are a convenient way of running web requests. The magic is in the IDE support. IntelliJ has it built in and VSCode has an extension. (IntelliJ Products, VSCode Extension)
iTerm2 is a macOS Terminal Replacement that adds some really nice features. Some of our Outlaw’s favorite short-cuts: (iTerm2, Features and Screenshots)
CMD+D to create a new panel (split vertically)
CMD+SHIFT+D to create a new panel (split horizontally)
CMD+Option+arrow keys to navigate between panes
CMD+Number to navigate between tabs
Ruler Hack – An architect scale ruler is a great way to prevent heat build up on your laptop by giving the hottest parts of the laptop some air to breathe. (Amazon)
Fizz Buzz Enterprise Edition is a funny, and sadly reminiscent, way of doing FizzBuzz that incorporates all the buzzwords and most abused design patterns that you see in enterprise Code. (GitHub)
From our friend Jamie Taylor (of DotNet Core Podcast, Tabs ‘n Spaces, and Waffling Taylors), mkcert is a “zero-config” way to easily generate self-signed certificates that your computer will trust. Great for dev! (GitHub)
We dive back into Designing Data-Intensive Applications to learn more about replication while Michael thinks cluster is a three syllable word, Allen doesn’t understand how we roll, and Joe isn’t even paying attention.
For those that like to read these show notes via their podcast player, we like to include a handy link to get to the full version of these notes so that you can participate in the conversation at https://www.codingblocks.net/episode160.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says
News
Thank you to everyone that left us a new review:
Audible: Ashfisch, Anonymous User (aka András)
The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair Douglas Adams
Douglas Adams
In this episode, we are discussing Data Replication, from chapter 5 of “Designing Data-Intensive Applications”.
Replication in Distributed Systems
When we talk about replication, we are talking about keeping copies of the same data on multiple machines connected by a network
For this episode, we’re talking about data small enough that it can fit on a single machine
Why would you want to replicate data?
Keeping data close to where it’s used
Increase availability
Increase throughput by allowing more access to the data
Data that doesn’t change is easy, you just copy it
3 popular algorithms
Single Leader
Multi-Leader
Leaderless
Well established (1970’s!) algorithms for dealing with syncing data, but a lot data applications haven’t needed replication so the practical applications are still evolving
Cluster group of computers that make up our data system
Node each computer in the cluster (whether it has data or not)
Replica each node that has a copy of the database
Every write to the database needs to be copied to every replica
The most common approach is “leader based replication”, two of the algorithms we mentioned apply
One of the nodes is designated as the “leader”, all writes must go to the leader
The leader writes the data locally, then sends to data to it’s followers via a “replication log” or “change stream”
The followers tail this log and apply the changes in the same order as the leader
Reads can be made from any of the replicas
This is a common feature of many databases, Postgres, Mongo, it’s common for queues and some file systems as well
Synchronous vs Asynchronous Writes
How does a distributed system determine that a write is complete?
The system could hang on till all replicas are updated, favoring consistency…this is slow, potentially a big problem if one of the replicas is unavailable
The system could confirm receipt to the writer immediately, trusting that replicas will eventually keep up… this favors availability, but your chances for incorrectness increase
You could do a hybrid, wait for x replicas to confirm and call it a quorum
All of this is related to the CAP theorem…you get at most two: Consistency, Availability and Partition Tolerance
Take a consistent snapshot of the leader at some point in time (most db can do this without any sort of lock)
Copy the snapshot to the new follower
The follower connects to the leader and requests all changes since the back-up
When the follower is fully caught up, the process is complete
Handling Outages
Nodes can go down at any given time
What happens if a non-leader goes down?
What does your db care about? (Available or Consistency)
Often Configurable
When the replica becomes available again, it can use the same “catch-up” mechanism we described before when we add a new follower
What happens if you lose the leader?
Failover: One of the replicas needs to be promoted, clients need to reconfigure for this new leader
Failover can be manual or automatic
Rough Steps for Failover
Determining that the leader has failed (trickier than it sounds! how can a replica know if the leader is down, or if it’s a network partition?)
Choosing a new leader (election algorithms determine the best candidate, which is tricky with multiple nodes, separate systems like Apache Zookeeper)
Reconfigure: clients need to be updated (you’ll sometimes see things like “bootstrap” services or zookeeper that are responsible for pointing to the “real” leader…think about what this means for client libraries…fire and forget? try/catch?
Failover is Hard!
How long do you wait to declare a leader dead?
What if the leader comes back? What if it still thinks it’s leader? Has data the others didn’t know about? Discard those writes?
Split brain – two replicas think they are leaders…imagine this with auto-incrementing keys… Which one do you shut down? What if both shut down?
There are solutions to these problems…but they are complex and are a large source of problems
Node failures, unreliable networks, tradeoffs around consistency, durability, availability, latency are fundamental problems with distributed systems
Implementation of Replication Logs
3 main strategies for replication, all based around followers replaying the same changes
Statement-Based Replication
Leader logs every Insert, Update, Delete command, and followers execute them
Problems
Statements like NOW() or RAND() can be different
Auto-increments, triggers depend on existing things happen in the exact order..but db are multi-threaded, what about multi-step transactions?
What about LSM databases that do things with delete/compaction phases?
You can work around these, but it’s messy – this approach is no longer popular
Example, MySQL used to do it
Write Ahead Log Shipping
LSM and B-Tree databases keep an append only WAL containing all writes
Similar to statement-based, but more low level…contains details on which bytes change to which disk blocks
Tightly coupled to the storage engine, this can mean upgrades require downtime
Examples: Postgres, Oracle
Row Based Log Replication
Decouples replication from the storage engine
Similar to WAL, but a litle higher level – updates contain what changed, deletes similar to a “tombstone”
Also known as Change Data Capture
Often seen as an optional configuration (Sql Server, for example)
Examples: (New MySQL/binlog)
Trigger-Based Replication
Application based replication, for example an app can ask for a backup on demand
We couldn’t decide if we wanted to gather around the water cooler or talk about some cool APIs, so we opted to do both, while Joe promises there’s a W in his name, Allen doesn’t want to say graph, and Michael isn’t calling out applets.
For all our listeners that read this via their podcast player, this episode’s show notes can be found at https://www.codingblocks.net/episode159, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
ConfigCat – The feature flag and config management service that lets you turn features ON after deployment or target specific groups of users with different features.
Survey Says
News
Thank you all for the latest reviews:
iTunes: Lp1876
Audible: Jon, Lee
Overheard around the Water Cooler
Where do you draw the line before you use a hammer to solve every problem?
When is it worth bringing in another technology?
Can you have too many tools?
APIs of Interest
Joe’s Picks
Video game related APIs
RAWG – The Biggest Video Game Database on RAWG – Video Game Discovery Service (rawg.io)
RAWG Video Games Database API (v1.0) (api.rawg.io)
Not sure what project to do? Google for an API or check out RapidAPI for a consistent way to farm ideas:
RAWG Video Games Database API Documentation (rapidapi.com)
Press F12 in Firefox, Chrome, or Edge, then go to the Elements tab (or Inspector in Firefox) to start hacking away at the DOM for immediate prototyping.
We talk about the various ways we can get paid with code while Michael failed the Costco test, Allen doesn’t understand multiple choice questions, and Joe has a familiar pen name.
This episode’s show notes can be found at https://www.codingblocks.net/episode158, where you can join the conversation, for those reading this via their podcast player.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Active income is typically has some ceiling, such as your time.
Passive Income
Passive income is income earned on an investment, any kind of investment, such as stock markets, affiliate networks, content sales for things like books, music, courses, etc.
The work you do for the passive income can blur lines, especially when that work is promotion.
Passive income is generally not tied to your time.
Passive Income Options
Create a SaaS platform to keep people coming back. Don’t let the term SaaS scare you off. This can be something smaller like a regex validator.
Affiliate links are a great example of passive income because you need to invest the time once to create the link.
Ads and sponsors: typically, the more targeted the audience is for the ad, the more the ad is worth.
Donations via services like Ko-fi, Patreon, and PayPal.
Apps, plugins, website templates/themes
Create content, such as books, courses, videos, etc. Self-publishing can have a bigger reward and offer more freedom, but doesn’t come with the built-in audience and marketing team that a publisher can offer.
Arbitrage between markets.
Grow an audience, be it on YouTube, Twitch, podcasting, blogging, etc.
Things to Consider
What’s the up-front effort and/or investment?
How much maintenance can you afford?
How much will it cost you?
Who gets hurt if you choose to quit?
What can you realistically keep up with?
What are the legal and tax liabilities?
Resources We Like
Apply for Grants To Fund Open Source Work (changeset.nyc)
We discuss all things APIs: what makes them great, what makes them bad, and what we might like to see in them while Michael plays a lawyer on channel 46, Allen doesn’t know his favorite part of the show, and Joe definitely pays attention to the tips of the week.
For those reading this episode’s show notes via their podcast player, you can find this episode’s show notes at https://www.codingblocks.net/episode157 where you can be a part of the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says
News
Big thanks to everyone that left us a new review:
iTunes: hhskakeidmd
Audible: Colum Ferry
All About APIs
What are APIs?
API stands for application programming interface and is a formal way for applications to speak to each other.
An API defines requests that you can make, what you need to provide, and what you get back.
If you do any googling, you’ll see that articles are overwhelmingly focused on Web APIs, particularly REST, but that is far from the only type. Others include:
All libraries,
All frameworks,
System Calls, i.e.: Windows API,
Remote API (aka RPC – remote procedure call),
Web related standards such as SOAP, REST, HATEOAS, or GraphQL, and
Domain Specific Languages (SQL for example)
The formal definition of APIs, who own them, and what can be done with them is complicated à la Google LLC v. Oracle America, Inc.
Different types of API have their own set of common problems and best practices
Common REST issues:
Authentication,
Rate limiting,
Asynchronous operations,
Filtering,
Sorting,
Pagination,
Caching, and
Error handling.
Game libraries:
Heavy emphasis on inheritance and “hidden” systems to cut down on complexity.
Libraries for service providers
Support multiple languages and paradigms (documentation, versioning, rolling out new features, supporting different languages and frameworks)
OData provides a set of standards for building and consuming REST API’s.
General tips for writing great APIs
Make them easy to work with.
Make them difficult to misuse (good documentation goes a long way).
Be consistent in the use of terms, input/output types, error messages, etc.
Simplicity: there’s one way to do things. Introduce abstractions for common actions.
Service evolution, i.e. including the version number as part of your API call enforces good versioning habits.
Documentation, documentation, documentation, with enough detail that’s good to ramp up from getting started to in depth detail.
Platform Independence: try to stay away from specifics of the platforms you expect to deal with.
Why is REST taking over the term API?
REST is crazy popular in web development and it’s really tough to do anything without it.
Some things about REST are great by design, such as:
By using it, you only have one protocol to support,
It’s verb oriented (commonly used verbs include GET, POST, PUT, PATCH, and DELETE), and
It’s based on open standards.
Some things about REST are great by convention, such as:
Noun orientation like resources and identifiers,
Human readable I/O,
Stateless requests, and
HATEOAS provides a methodology to decouple the client and the server.
Maybe we can steal some ideas from REST
Organize the API around resources, like /orders + verbs instead of /create-order.
Note that nouns can be complex, an order can be complex … products, addresses, history, etc.
Collections are their own resources (i.e. /orders could return more than 1).
Consistent naming conventions makes for easy discovery.
Microsoft recommends plural nouns in most cases, but their skewing heavily towards REST, because REST already has a mechanism for behaviors with their verbs. For example /orders and /orders/123.
You can drill in further and further when you orient towards nouns like /orders/123/status.
The general guidance is to return resource identifiers rather than whole objects for complex nouns. In the order example, it’s better to return a customer ID associated with the whole order.
Avoid introducing dependencies between the API and the underlying data sources or storage, the interface is meant to abstract those details!
Verb orientation is okay in some, very action based instances, such as a calculator API.
Listen to American Scandal. A great podcast with amazing production quality. (Wondery)
If you have a license for DataGrip and use other JetBrains IDEs, once you add a data source, the IDE will recognize strings that are SQL in your code, be they Java, JS, Python, etc., and give syntax highlighting and autocomplete.
Also, you can set the connection to a DB in DataGrip as read only under the options. This will give you a warning message if you try a write operation even if your credentials have write permissions.
API Blueprint. A powerful high-level API description language for web APIs. (apiblueprint.org)
Apache Superset – A modern data exploration and visualization platform. (Apache)
We discuss the parts of the scrum process that we’re supposed to pay attention to while Allen pronounces the m, Michael doesn’t, and Joe skips the word altogether.
If you’re reading this episode’s show notes via your podcast player, just know that you can find this episode’s show notes at https://www.codingblocks.net/episode156. Stop by, check it out, and join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says
News
Hey, we finally updated the Resources page. It only took a couple years.
Apparently we don’t understand the purpose of the scrum during rugby. (Wikipedia)
Standup Time
User Stories
A user story is a detailed, valuable chunk of work that can be completed in a sprint.\
Use the INVEST mnemonic created by Bill Wake:
I = Independent – the story should be able to be completed without any dependencies on another story
N = Negotiable – the story isn’t set in stone – it should have the ability to be modified if needed
V = Valuable – the story must deliver value to the stakeholder
E = Estimable – you must be able to estimate the story
S = Small – you should be able to estimate within a reasonable amount of accuracy and completed within a single sprint
T = Testable – the story must have criteria that allow it to be testable
Stories Should be Written in a Format Very Much Like…
“As a _____, I want _____ so that _____.”, like “As a user, I want MFA in the user profile so I can securely log into my account” for a functional story, or “As a developer, I want to update our version of Kubernetes so we have better system metrics” for a nonfunctional story.
Stories Must have Acceptance Criteria
Each story has it’s own UNIQUE acceptance criteria.
For the MFA story, the acceptance criteria might be:\
Token is captured and saved.
Verification of code completed successfully.
Login works with new MFA.
The acceptance criteria defines what “done” actually means for the story.
Set up Team Boundaries
Define “done”.
Same requirement for ALL stories:
Must be tested in QA environment,
Must have test coverage for new methods.
Backlog prioritization or “grooming”.
Must constantly be ordered by value, typically by the project owner.
Define sprint cadence
Usually 1-4 weeks in length, 2-3 is probably best.
Two weeks seems to be what most choose simply because it sort of forces a bit of urgency on you.
Estimates
Actual estimation, “how many hours will a task take?”
Relative estimation, “I think this task will take 2x as long as this other ticket.”
SCRUM uses both, user stories are compared to each other in relative fashion.
By doing it this way, it lets external stakeholders know that it’s an estimate and not a commitment.
Story points are used to convey relative sizes.
Estimation is supposed to be lightweight and fast.
Roadmap and Release Plan
The roadmap shows when themes will be worked on during the timeframe.\
You should be able to have a calendar and map your themes across that calendar and in an order that makes sense for getting a functional system.
Just because you should have completed, functional components at the end of each sprint, based on the user stories, that doesn’t mean you’re releasing that feature to your customer. It may take several sprints before you’ve completed a releasable feature.
It will take several sprints to find out what a team’s stabilized velocity is, meaning that the team will be able to decently predict how many story points they can complete in a given sprint.
Filling up the Sprint
Decide how many points you’ll have for a sprint.
Determine how many sprints before you can release the MVP.
Fill up the sprints as full as possible in priority order UNLESS the next priority story would overflow the sprint.
Simple example, let’s say your sprint will have 10 points and you have the following stories: Story A – 3 points Story B – 5 points Story C – 8 points Story D – 2 points
Your sprints might look like: Sprint 1 – A (3) B(5), D(2) = 10 points Sprint 2 – C (8)
Story C got bumped to Sprint 2 because the goal is to maximize the amount of work that can be completed in a given sprint in priority order, as much as possible.
The roadmap is an estimate of when the team will complete the stories and should be updated at the end of each sprint. In other words, the roadmap is a living document.
Sprint Planning
This is done at the beginning of each sprint.
Attendees – all developers, scrum master, project owner.
Project owner should have already prioritized the stories in the backlog.
The goal of the planning meeting is to ensure all involved understand the stories and acceptance criteria.
Also make sure the overarching definition of “done” is posted as a reminder.
Absolutely plan for a Q&A session.
Crucial to make sure any misunderstandings of the stories are cleared here.
Next the stories are broken down into specific tasks. These tasks are given actual estimates in time.
Once this is completed, you need to verify that the team has enough capacity to complete the tasks and stories in the sprint.
In general, each team member can only complete 6 hours of actual work per day on average.
Each person is then asked whether they commit to the work in the sprint.
Must give a “yes” or “no” and why.
If someone can’t commit with good reason, the the project owner and team need to work together to modify the sprint so that everyone can commit. This is a highly collaborative part of scrum planning.
Stakeholder Feedback
Information radiators are used to post whatever you think will help inform the stakeholders of the progress, be it a task board or burn down chart.
Task board
Lists stories committed to in the sprint.
Shows the status of any current tasks.
Lists which tasks have been completed.
Swimlanes are typically how these are depicted with lanes like: Story, Not Started, In Progress, Completed.
Sprint burndown chart
Shows ongoing status of how you’re doing with completing the sprint.
Daily Standup
The purpose of the standup is the three C’s:\
Collaboration,
Communication, and
Cadence.
The entire team must join: developers, project owner, QA, scrum master.
Should occur at the same time each day.
Each status should just be an overview and light on the details.
Tasks are moved to a new state during the standup, such as from Not Started to In Progress.
Stakeholders can come to the scrum but should hold questions until the end.
Cannot go over 15 minutes. It can be shorter, but should not be longer.
Each person should answer three questions:
What did you do yesterday?,
What are you doing today?, and
Are there any blockers?
If you see someone hasn’t made progress in several days, this is a great opportunity to ask to help. This is part of keeping the team members accountable for progressing.
Blockers are brought up during the meeting as anyone on the team needs to try and step in to help. If the issue hasn’t been resolved by the next day, then it’s the responsibility of the scrum master to try and resolve it, and escalate it further up the chain after that, such as to the project owner and so on, each consecutive day.
Again, very important, this is just the formal way to keep the entire team aware of the progress. People should be communicating throughout the day to complete whatever tasks they’re working on.
Backlog Refinement
The backlog is constantly changing as the business requirements change.
It is the job of the project owner to be in constant communication with the stakeholders to ensure the backlog represents the most important needs of the business and making sure the stories are prioritized in value order.
Stories are constantly being modified, added, or removed.
Around the midpoint of the sprint, there is usually a 30-60 minute “backlog refinement session” where the team comes together to discuss the changes in the backlog.
These new stories can only be added to future sprints.
The current sprint commitment cannot be changed once the sprint begins.
The importance of this mid-sprint session is the team can ask clarifying questions and will be better prepared for the upcoming sprint planning.
This helps the project owner know when there are gaps in the requirements and helps to improve the stories.
Marking a Story Done
The project owner has the final say making sure all the acceptance criteria has been met.
There could be another meeting called the “sprint review” where the entire team meets to get signoff on the completed stories.
Anything not accepted as done gets reviewed, prioritized, and moved out to another sprint.
This can happen when a team discovers new information about a story while working on it during a sprint.
The team agrees on what was completed and what can be demonstrated to the stakeholders.
The Demo
This is a direct communication between the team and the stakeholders and receive feedback.
This may result in new stories.
Stakeholders may not even want the new feature and that’s OK. It’s better to find out early rather than sinking more time into building something not needed or wanted.
This is a great opportunity to build a relationship between the team members and the stakeholders.
This demo also shows the overall progress towards the final goal.
May not be able to demo at the end of every sprint, but you want to do it as often as possible.
Team Retrospective
Focus is on team performance, not the product and is facilitated by the scrum master.
This is a closed door session and must be a safe environment for discussion.
Only dedicated team members present and the team norms must be observed
You want an open dialogue/
What worked well? Focus on good team collaboration.
What did not work well? Focus on what you can actually change.
During today’s standup, we focus on learning all about Scrum as Joe is back (!!!), Allen has to dial the operator and ask to be connected to the Internet, and Michael reminds us why Blockbuster failed.
If you didn’t know and you’re reading these show notes via your podcast player, you can find this episode’s show notes in their original digital glory at https://www.codingblocks.net/episode155 where you can also jump in the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Comes from the game of Rugby. A scrummage is when a team huddles after a foul to figure out their next set of plays and readjust their strategy.
Why is Scrum the Hot Thing?
Remember waterfall?
Plan and create documentation for a year up front, only to build a product with rigid requirements for the next year. By the time you deliver, it may not even be the right product any longer.
Waterfall works for things that have very repeatable steps, such as things like planning the completion of a building.
It doesn’t work great for things that require more experimentation and discovery.
Project managers saw the flaw in planning for the complete “game” rather than planning to achieve each milestone and tackle the hurdles as they show up along the way.
Scrum breaks the deliverables and milestones into smaller pieces to deliver.
The Core Tenants of Scrum
Having business partners and stakeholders work with the development of the software throughout the project,
Measure success using completed software throughout the project, and
Allow teams to self-organize.
Scrum Wants You to Fail Fast
Failure is ok as long as you’re learning from it.
But those lessons learned need to happen quickly, with fast feedback cycles.
Small scale focus and rapid learning cycles.
In other words, fail fast really means “learn fast”.
It’s super important to recognize that Scrum is *not* prescriptive. It’s more like guardrails to a process.
An Overview of the Scrum Framework
The product owner has a prioritized backlog of work for the team.
Every sprint, the team looks at the backlog and decides what they can accomplish during that sprint, which is generally 2-3 weeks.
The team develops and tests their solutions until completed. This effort needs to happen within that sprint.
The team then demonstrates their finished product to the product owner at the end of the sprint.
The team has a retrospective to see how the sprint went, what worked, and what they can improve going forward.
Focusing on creating a completed, demo-able piece of work in the sprint allows the team to succeed or fail/learn fast.
Projects are typically comprised of three basic things: time, cost, and scope. Usually time and cost are fixed, so all you can work with is the scope.
There are Two Key Roles Within Scrum
Project owner – The business representative dedicated 100% to the team.
Acts as a full time business representative.
Reviews the team’s work constantly to ensure the proper deliverable is being created.
Interacts with the stakeholders.
Is the keeper of the product vision.
Responsible for making sure the work is continuously sorted per the ongoing business needs.
The Scrum master – Responsible for helping resolve daily issues and balance ongoing changes in requirements and/or scope.
This person has a mastery of Scrum.
Also helps improve internal team processes.
Responsible for protecting the team and their processes.
Balances the demands of the product owner and the needs of the team.
This means keeping the team working at a sustainable rate.
Acts as the spokesperson for the entire team.
Provides charts and other views into the progress for others for transparency.
Responsible for removing any blockers.
Project owner focuses on what needs to be done while the Scrum master focuses on how the team gets it done.
Scrum doesn’t value heroics by teams or team members.
Scrum is all about Daily Collaboration
Whatever you can do to make daily collaboration easier will yield great benefits.
Collocate your team if possible.
If you can’t do that, use video conferencing, chat, and/or conference calls to keep communication flowing.
The Team Makeup
You must have a dedicated team. If members of your team are split amongst different projects, it will be difficult to accomplish your goals as you lose efficiency.
The ideal team size is 5 to 9 members.
You want a number of T-shaped developers.
These are people can work on more than one type of deliverable.
You also need some “consultants” you may be able to call on that have more specialized/focused skillsets that may not be core members of the team.
Team Norms
Teams will need to have standard ways of dealing with situations.
How people will work together.
How they’ll resolve conflicts.
How to come to a consensus.
Must have full team buy-in and everyone must be willing to hold each other accountable.
Agree to disagree, but move forward with agreed upon solution.
Product Vision
It’s the map for your team, it’s what tells you how to get where you want to go.
This must be established by the project owner.
The destination should be the “MVP”, i.e. the Minimum Viable Product.
Why MVP? By creating just enough to get it out to the early adopters allows you to get feedback early.
This allows for a fast feedback cycle.
Minimizes scope creep.
Must set the vision, and then decompose it.
Break the Vision Down into Themes
Start with a broad grouping of similar work.
Allows you to be more efficient by grouping work together in similar areas.
This also allows you to think about completing work in the required order.
Once You’ve Identified the Themes, You Break it Down Further into Features
If you had a theme of a User Profile, maybe your features might be things like:
Change password,
Setup MFA, and
Link social media.
To get the MVP out the door, you might decide that only the Change Password feature is required.
Using k9s makes running your Kubernetes cronjobs on demand super easy. Find the cronjob you want to run (hint: :cronjobs) and then use CTRL+T to execute the cronjob now. (GitHub)
Windows Terminal is your new favorite terminal. (microsoft.com)
We dig into recursion and learn that Michael is the weirdo, Joe gives a subtle jab, and Allen doesn’t play well with others while we dig into recursion.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
News
Thank you all for the reviews:
iTunes: ripco55, Jla115
Audible: _onetea, Marnu, Ian
Here I Go Again On My Own
What is Recursion?
Recursion is a method of solving a problem by breaking the problem down into smaller instances of the same problem.
A simple “close enough” definition: Functions that call themselves
Simple example: fib(n) { n <= 1 ? n : fib(n - 1) + fib(n - 2) }
Recursion pros:
Elegant solutions that read well for certain types of problems, particularly with unbounded data.
Work great with dynamic data structures, like trees, graphs, linked lists.
Recursion cons:
Tricky to write.
Generally perform worse than iterative solutions.
Runs the risk of stack overflow errors.
Recursion is often used for sorting algorithms.
How Functions Roughly Work in Programming Languages
Programming languages generally have the notion of a “call stack”.
A stack is a data structure designed for LIFO. The call stack is a specialized stack that is common in most languages
Any time you call a function, a “frame” is added to the stack.
The frame is a bucket of memory with (roughly) space allocated for the input arguments, local variables, and a return address.
Note: “value types” will have their values duplicated in the stack and reference types contain a pointer.
When a method “returns”, it’s frame is popped off of the stack, deallocating the memory, and the instructions from the previous function resume where it left off.
When the last frame is popped off of the call stack, the program is complete.
The stack size is limited. In C#, the size is 1MB for 32-bit processes and 4MB for 64-bit processes.
You can change these values but it’s not recommended!
When the stack tries to exceed it’s size limitations, BOOM! … stack overflow exception!
How big is a frame? Roughly, add up your arguments (values + references), your local variables, and add an address.
Ignoring some implementation details and compiler optimizations, a function that adds two 32b numbers together is going to be roughly 96b on the stack: 32 * 2 + return address.
You may be tempted to “optimize” your code by condensing arguments and inlining code rather than breaking out functions… don’t do this!
These are the very definition of micro optimizations. Your compiler/interpreter does a lot of the work already and this is probably not your bottleneck by a longshot. Use a profiler!
Not all languages are stack based though: Stackless Python (kinda), Haskell (graph reduction), Assembly (jmp), Stackless C (essentially inlines your functions, has limitations)
The stack doesn’t care about what the return address is.
When a function calls any other function, a frame is added to the stack.
To keep things simple, suppose for a Fibonacci sequence function, the frame requires 64b, 32b for the argument and 32b for the return address.
Every Fibonacci call, aside from 0 or 1, adds 2 frames to the stack. So for the 100th number we will allocate .6kb (1002 * 32). And remember, we only have 1mb for everything.
You can actually solve Fibonacci iteratively, skipping the backtracking.
Fibonacci is often given as an example of recursion for two reasons:
It’s relatively easy to explain the algorithm, and
It shows the danger of this approach.
What is Tail Recursion?
The recursive Fibonacci algorithm discussed so far relies on backtracking, i.e. getting to the end of our data before starting to wind back.
If we can re-write the program such that the last operation, the one in “tail position” is the ONLY recursive call, then we no longer need the frames, because they are essentially just pass a through.
A smart compiler can see that there are no operations left to perform after the next frame returns and collapse it.
The compiler will first remove the last frame before adding the new one.
This means we no longer have to allocate 1002 extra frames on the stack and instead just 1 frame.
A common approach to rewriting these types of problems involves adding an “accumulator” that essentially holds the state of the operation and then passing that on to the next function.
The important thing here, is that the your ONE AND ONLY recursive call must be the LAST operation … all by itself.
Joe’s (Un)Official Recursion Tips
Start with the end.
Do it by hand.
Practice, practice, practice.
Joe Recursion Joe’s Motivational Script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#!/usr/bin/env python3
importsys
defgetname(arg):
print(f"{arg}")
ifarg=='Joe':
getname('Recursion')
else:
getname('Joe')
return
if__name__=="__main__":
sys.setrecursionlimit(500)
print(f"Who is awesome?")
try:
getname('Joe')
except:
print("You got this!")
Recap
Recursion is a powerful tool in programming.
It can roughly be defined as a function that calls itself.
It’s great for dynamic/unbounded data structures like graphs, trees, or linked lists.
Recursive functions can be memory intensive and since the call stack is limited, it is easy to overflow.
Tail call optimization is a technique and compiler trick that mitigates the call stack problem, but it requires language support and that your recursive call be the last operation in your function.
FAANG-ish interviews love recursive problems, and they love to push you on the memory.
It’s been a minute since we last gathered around the water cooler, as Allen starts an impression contest, Joe wins said contest, and Michael earned a participation award.
We dig into all things Python, which Allen thinks is pretty good, and it’s rise in popularity, while Michael and Joe go toe-to-toe over a gripe, ahem, feature.
We realize that you _can_ use your podcast player to read these notes, but if you didn’t know, this episode’s show notes can be found at https://www.codingblocks.net/episode152. Check it out and join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
DataStax – Sign up today to get $300 in credit with promo code CODINGBLOCKS and make something amazing with Cassandra on any cloud.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
News
The Coding Blocks Game Jam 2021 results are in! (itch.io)
Kinesis Advantage 2 Full Review after Heavy Usage (YouTube)
Ergonomic Keyboard Zergotech Freedom Full Review (YouTube)
Why Python?
A Brief History of Python. Very Brief.
Python is a general-purpose high-level programming language, which can be used to develop desktop GUI applications, websites, and apps that run on sophisticated algorithms.
Python was created in 1991, before JavaScript or Java, but didn’t make major leaps in popularity until 1998 – 2003, according to the Tiobe index.
Coincidentally, this lines up with the early days of Google, where they had a motto of “Python where we can, C++ where we must”.
In 2009, MIT switched from Scheme to Python, and others in academia followed.
Some Python Benefits, But Only Some
It’s an easy language for new developers as well as those who don’t consider themselves developers, such as data scientists or hobbyists, but have a need write some code.
Python has a great standard library when compared to languages like JavaScript that largely rely on third party libraries to provide depth in functionality.
It’s cross platform. As long as we’re talking OS.
Mobile? Not really, as that space is consumed with Swift, Java, and Objective-C. But with things like Pythonista, you can write and execute Python on mobile.
Web? No, at least not on the client side. That space is dominated by JavaScript. But with frameworks like Django and Flask, you can use Python on the server side.
In addition to the standard library, there are also many great/popular third party libraries, like NumPy, that are available on PyPi.
The Downsides to Python
Performance when compared to a natively compiled application because it’s a dynamic, interpreted language.
Which brings up the late binding type system.
The lack of mobile and web presence as previously mentioned.
Legacy issues when dealing with v2, which is still in use.
Language features that haven’t aged well, such as PEP-8.
Quirks like self, or __init__, private functionality, and immutability.
Top 10 Reasons Why Python is So Popular With Developers in 2021 (upgrad.com)
Python – 12. Virtual Environments and Packages (docs.python.org)
Python’s virtual environments have been mentioned as a Tip of the Week twice: first during episode 102, Why Date-ing is Hard and again during episode 140, The DevOps Handbook – Enabling Safe Deployments. (/episode102, /episode140)
We step back to reflect on what we learned from our first game jam, while Joe’s bathroom is too close and Allen taught Michael something (again).
Stop squinting to read this via your device’s podcast player. This episode’s show notes can be found at https://www.codingblocks.net/episode151, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
DataStax – Sign up today to get $300 in credit with promo code CODINGBLOCKS and make something amazing with Cassandra on any cloud.
Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
News
We appreciate the new reviews, thank you!
iTunes: ddausdd
Audible: devops.rob
Kinesis Advantage 2 Full Review after Heavy Usage (YouTube)
Game Jam Tips
Aim for the browser and to be embedded.
Be careful sharing your custom URL when hosting somewhere other than the game jam as it splits your traffic and likely, your feedback.
Time management is super important.
Be realistic about how much time you have.
You’ll be tired by the end!
Start with the Game Loop.
Try to always be playable.
Aim small and prioritize the “must haves”.
Know what you want to learn.
Judge your game against what you can do.
Beware of graphics and animations! Inspiration is fine, but it can become a sinkhole.
Recall from the above tips about time management and focusing on a playable game.
Play into the theme. Or don’t.
Use tools, asset stores, and libraries, such as Tiled, PyGame, Photoshop, and/or Butler, to simplify your effort and make maximum use of your time.
Consider teamwork.
Borrowing ideas is fine.
Keep your “elevator pitch” in mind, and evolve it.
Publish early and save energy for playing.
Save time to write up your game’s description, take video/screenshots, etc. for the submission.
Keep your game testable by having a dev mode and/or the ability to initialize a certain game state.
Think about the player over and over and over. How do you teach them the game’s mechanics, physics, when the game is over, etc.
And again, save time and energy for publishing your game, as well as, playing and rating other’s games.
Resources We Like
The Coding Blocks Game Jam 2021 submissions (itch.io)
We discuss all things open-source, leaving Michael and Joe to hold down the fort while Allen is away, while Joe’s impersonations are spot on and Michael is on a first name basis, assuming he can pronounce it.
This episode of the Coding Blocks podcast is about the people and organizations behind open-source software. We talk about the different incentives behind projects, and their governance to see if we can understand our ecosystem better.
Q: What do most developers think about when they think of “open-source” software?
Q: Is the formal definition more important than the general perception?
Formal Definitions of Open-Source
opensource.org: Open source software is made by many people and distributed under an OSD-compliant license which grants all the rights to use, study, change, and share the software in modified and unmodified form. Software freedom is essential to enabling community development of open source software.
opensource.com: Open source commonly refers to software that uses an open development process and is licensed to include the source code
Pop Quiz, who created…?
C: Dennis Ritchie
Linux: Linus Torvolds
Curl: Daniel Sternberg
Python: Guido von Rossum
JavaScript: Brandon Eich (Netscape)
Node: Ryan Dahl
Java: James Gosling (Sun)
Git: Linus Torvalds
C#: Microsoft (Anders Hejlsberg)
Kubernetes: Google
Postgres: Michael Stonebraker
React: Facebook
Rust: Mozilla
Chromium: Google
Flutter: Google
TypeScript: Microsoft
Vue: Evan You
Q: It seems like most newer projects (with the exception of Vue) are associated with corporations or foundations. When and why did that change?
GitHub Star Distribution
Q: What are the most popular projects? Who were they made for, and why?
Q: Why do individuals create open source? What do they get out of it?
Corporations
A lot of corporate “open source” that are utilities or tools for working with those companies (ie: Azure SDK)
Many open source projects are stewarded by a single company (Confluent, Elastic, MongoDB)
Many open source projects listed below are now run by a foundation
Let’s look at some of the most prominent projects that were started by corporations. Note: many of these projects came in through acquisitions, and many have since been donated to foundations.
Microsoft
Maybe the biggest? Maybe?
.NET, Helm, TypeScript, Postgres, VS Code, NPM, GitHub
Sometimes a company will either outright own, or otherwise build a business centered around a technology. These companies will typically offer services and support around open-source projects.
DataStax
Elasticsearch
Canonical
MongoDB
Q: Why do corporations publish open-source software? What do they get out of releasing projects?
Foundations
Foundations are organizations that own open-source projects
Foundations have many different kinds of governance models, but generally they are responsible for things like…
Foundations are run in a variety of ways, and for different reasons, some even offer many competing projects
https://opensource.guide/leadership-and-governance/ ** BDFL – Python, small projects, one person has final say ** “Meritocracy” (not a great term) – Active contributors are given decision making power, voting ** Liberal Contribution: Projects seek concensus rather than a pure vote, strive to be inclusive (Node, Rust)
We start off the year discussing our favorite developer tools of 2020, as Joe starts his traditions early, Allen is sly about his résumé updates, and Michael lives to stream.
For those that read the show notes via their podcast player and find themselves wondering where they can find these show notes on their computer, the answer is simple: https://www.codingblocks.net/episode149. Check it out and join the discussion.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Watch Joe speak at the virtual San Diego Elastic Meetup, Tuesday, January 19, 2021 at 5:00 PM PST, where he is talking about Easy Local Development with Elastic Cloud on Kubernetes using Skaffold.
Skaffold – Handles the workflow for building, pushing, and deploying your application within Kubernetes, allowing you to focus on writing your code.
Kustomize – A template-free way to customize Kubernetes application configuration, built into kubectl.
Oh My Zsh – An open source, community-driven framework for managing your zsh configuration.
Netlify – Unites everything teams need to build and run dynamic web experiences, from preview to production, using an intuitive git-based workflow and a powerful serverless platform.
Jira StopWatch – A desktop tool for recording time spent on different Jira issues.
Lens – The Kubernetes IDE, Lens provides full situational awareness for everything that runs in Kubernetes, lowering the barrier of entry for those just getting started with Kubernetes, while radically improving productivity for the experienced users.
Zoom – Keeping you connected wherever you are. Hands down, the best video calling software out there for screen sharing; you can actually read the other person’s screen!
Prometheus – Power your metrics and alerting with a leading open-source monitoring solution.
Grafana – The world’s most popular technology used to compose observability dashboards.
Visual Studio Code – Code editing, redefined. Free and built on open source. Runs everywhere.
It’s the end of 2020. We’re all tired. So we phone it in for the last episode of the year as we discuss the State of the Octoverse, while Michael prepared for the wrong show (again), Allen forgot to pay his ISP bill and Joe’s game finished downloading.
In case you’re wondering where you can find these show notes in all there 1:1 pixel digital glory because you’re reading them via your podcast app, you can find them at https://www.codingblocks.net/episode148, where you can also join the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Survey Says
News
Joe will be speaking at the virtual San Diego Elastic Meetup, Tuesday, January 19, 2021 at 5:00 PM PST, talking about Easy Local Development with Elastic Cloud on Kubernetes using Skaffold.
We discuss the things we’re excited about for 2021 as Michael prepared for a different show, Joe can’t stop looking at himself, and Allen gets paid by the tip of the week.
Command Line Heroes – A podcast that tells the epic true tales of developers, programmers, hackers, geeks, and open source rebels who are revolutionizing the technology landscape.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
We learn all the necessary details to get into the world of developer game jams, while Michael triggers all parents, Allen’s moment of silence is oddly loud, and Joe hones his inner Steve Jobs.
If you’re reading these show notes via your podcast player and wondering where you can find them in your browser, well wonder no more. These show notes can be found at https://www.codingblocks.net/episode146 in all their 8-bit glory. Check it out and join the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
We wrap up our deep dive into The DevOps Handbook, while Allen ruined Halloween, Joe isn’t listening, and Michael failed to… forget it, it doesn’t even matter.
If you’re reading this via your podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode145 where you can join the conversation, as well find past episode’s show notes.
Sponsors
Command Line Heroes – A podcast that tells the epic true tales of developers, programmers, hackers, geeks, and open source rebels who are revolutionizing the technology landscape.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Survey Says
News
Thank you to everyone that left us a new review!
iTunes: AbhishekN12, Streichholzschächtelchen Mann
Use Chat Rooms and Bots to Automate and Capture Organizational Knowledge
Chat rooms have been increasingly used for triggering actions.
One of the first to do this was ChatOps at GitHub. By integrating automation tools within the chat, it was easy for people to see exactly how things were done.
Everyone sees what’s happening.
Onboarding is nice because people can look through the history and see how things work.
This helps enable fast organizational learning.
Another benefit is that typically chat rooms are public. so it creates an environment of transparency.
One of the more beneficial outcomes was that ops engineers were able to discover problems quickly and help each other out more easily.
“Even when you’re new to the team, you can look in the chat logs and see how everything is done. It’s as if you were pair-programming with them all the time.”
Jesse Newland
Automate Standardized Processes in Software for Re-Use
Often times developers document things in wikis, SharePoint systems, word documents, excel documents, etc., but other developers aren’t aware these documents exist so they do things a different way, and you end up with a bunch of disparate implementations.
The solution is to put these processes and standards into executable code stored in a repository.
Create a Single, Shared Source Code Repository for Your Entire Organization
This single repository enables quick of sharing amongst an entire organization.
In 2015, Google had a single repository with over 1 billion files over 2 billion lines of code. This single repository is used by every software engineer and every product.
This repository doesn’t just include code, but also:
Configuration standards for libraries, infrastructure and environments like Chef, Ansible, etc.,
Deployment tools,
Testing standards and tools as well as security,
Deployment pipeline tools,
Monitoring and analysis tools, and
Tutorials and standards.
Whenever a commit goes in, everything is built from code in the shared repo: no dynamic linking. This ensures everything works with the latest code in the repository.
By building everything off a single source tree, Google eliminates the problems you encounter when you use external dependency management systems like Artifactory, Nuget, etc.
Spread Knowledge by Using Automated Tests as Documentation and Communities of Practice
Sharing libraries throughout an organization means you need a good way of sharing expertise and improvements.
Automated tests are a great way to ensure things work with new commits and they are self-documenting.
TDD turns tests into up-to-date specifications of a system.
Want to know how to use the library? Take a look at the test suites.
Ideally you want to have one group responsible for owning and supporting a library.
Ideally you only ever have one version of that code out in production. It will contain the current best collaborative knowledge of the organization.
The owner is also responsible for migrating each consumer of the library to the next version.
This requires the consumers to have a good suite of automated testing as well.
Another great use of chat rooms is to have one for each library.
Design for Operations Through Codified Non-Functional Requirements
When developers are responsible for incident response in their deployed applications, their applications become better designed for operations.
As developers are involved in non-functional requirements, we design our systems for faster deployment, better reliability, the ability to detect problems, and allow for graceful degradation.
Some of these non-functionals are:
Production telemetry,
Ability to track dependencies,
Resilient and gracefully degrading services,
Forward and backward compatibility between versions,
Ability to archive data to reduce size requirements,
Ability to search and understand log messages,
Ability to trace requests through multiple services, and
Centralized runtime configurations.
Build Reusable Operations User Stories into Development
When there is ops works that needs to be done but can’t be fully automated, we need to make them as repeatable and deterministic as we can.
Automate as much as possible.
Document the rest for operations.
Automation for handoffs is also helpful.
By having these workflows and handoffs in place, it’s easier to measure and forecast future needs and ETAs.
Ensure Technology Choices Help Achieve Organizational Goals
Any technology introduced, introduces more pressure on operations for support.
If operations cannot support it, then the group that owns the service or library becomes a bottleneck, which could be a major problem.
Always be identifying technologies that appear to be the problem areas. Maybe they:
Slow the flow of work,
Create high levels of unplanned work (i.e. fire fighting),
Unbalanced number of support requests, and/or
Don’t really meet organizational goals, such as stability, throughput, etc.
This doesn’t mean don’t use new technologies or languages, but know that your level of support greatly diminishes as you go into uncharted territories.
Reserve time to Create Organizational Learning and Improvement
Dedicate time over several days to attack and resolve a particular problem or issue.
Use people outside the process to assist those inside the process.
The most intense methodology is a 30 day focus group with coaches and engineers that focus on solving real company problems.
Not uncommon to solve in days what used to take months
Institutionalize Rituals to Pay Down Technical Debt
Schedule time, a few days, a week, whatever, to fix problems you care about. No feature work allowed.
Could be code problems, environment, configuration, etc.
Usually want to include people from different teams working together, i.e. operations, developers, InfoSec, etc.
Present accomplishments at the end of the blitz
Enable Everyone to Teach and Learn
Everyone should be encouraged to teach and learn in their own ways.
It’s becoming more important than ever for folks to have knowledge in more than just one area to be successful.
Encourage cross functional pollination, i.e. have operations show developers how they do something, or vice versa.
Share Your Experiences from DevOps Conferences
Organizations should encourage their employees to attend and/or speak at conferences.
Hold your own company conference, even if it’s just for your small team.
Create Internal Consulting and Coaches to Spread Practices
Encourage your SME’s to have office hours where they’ll answer technical questions.
Create groups with missions to help the organization move forward.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
DevOps: Job Title or Job Responsibility? (episode 118)
Tip of the Week
Diff syntax highlighting in Github Markdown (Stack Overflow)
Code Chefs – Hungry Web Developer Podcast (Apple Podcasts)
Maria, a coding environment for beginners (maria.cloud)
CodeWorld, create drawings, animations, and games using math, shapes, colors, and transformations. (code.world)
Generation numbers and preconditions – Apply preconditions to guarantee atomicity of multi-step transactions with object generation numbers to uniquely identify data resources. (cloud.google.com)
helm search repo – Search repositories for a keyboard in charts. (helm.sh)
Use -cur_console:p5 in your cmder WSL profile to ensure that the arrow keys work as expected on Windows 10 (GitHub)
cmder – A portable console emulator for Windows (cmder.net)
It’s our favorite time of year where we discuss all of the new ways we can spend our money in time for the holidays, as Allen forgets a crucial part, Michael has “neons”, and Joe has a pet bear.
Reading this via your podcast player? If so, you can find this episode’s full show notes at https://www.codingblocks.net/episode144, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Teamistry – A podcast that tells the stories of teams who work together in new and unexpected ways, to achieve remarkable things.
We dive into the benefits of enabling daily learning into our processes, while it's egregiously late for Joe, Michael's impersonation is awful, and Allen's speech is degrading.
This episode’s show notes can be found at https://www.codingblocks.net/episode143, for those reading this via their podcast player, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Teamistry – A podcast that tells the stories of teams who work together in new and unexpected ways, to achieve remarkable things.
Survey Says
News
Thank you to everyone that left us a new review!
iTunes: John Roland, Shefodorf, DevCT, Flemon001, ryanjcaldwell, Aceium
Stitcher: Helia
Allen saves your butt with his latest chair review on YouTube.
Enable and Inject Learning into Daily Work
To work on complex systems effectively and safely we must get good at:
Detecting problems,
Solving problems, and
Multiplying the effects by sharing the solutions within the organization.
The key is treating failures as an opportunity to learn rather than an opportunity to punish.
Establish a Just, Learning Culture
By promoting a culture where errors are “just” it encourages learning ways to remove and prevent those errors.
On the contrary, an “unjust” culture, promotes bureaucracy, evasion, and self-protection.
This is how most companies and management work, i.e. put processes in place to prevent and eliminate the possibility of errors.
Rather than blaming individuals, take moments when things go wrong as an opportunity to learn and improve the systems that will inevitably have problems.
Not only does this improve the organization’s systems, it also strengthens relationships between team members.
When developers do cause an error and are encouraged to share the details of the errors and how to fix them, it ultimately benefits everyone as the fear of consequences are lowered and solutions on ensuring that particular problem isn’t encountered again increase.
Blameless Post Mortem
Create timelines and collect details from many perspectives.
Empower engineers to provide details of how they may have contributed to the failures.
Encourage those who did make the mistakes to share those with the organization and how to avoid those mistakes in the future.
Don’t dwell on hindsight, i.e. the coulda, woulda, and shoulda comments.
Propose countermeasures to ensure similar failures don’t occur in the future and schedule a date to complete those countermeasures.
Stakeholders that should be present at these meetings
People who were a part of making the decisions that caused the problem.
People who found the problem.
People who responded to the problem.
People who diagnosed the problem.
People who were affected by the problem.
Anyone who might want to attend the meeting.
The meeting
Must be rigorous about recording the details during the process of finding, diagnosing, and fixing, etc.
Disallow phrases like “could have” or “should have” because they are counterproductive.
Reserve enough time to brainstorm countermeasures to implement.
These must be prioritized and given a timeline for implementation.
Publish the learnings and timelines, etc. from the meeting so the entire organization can gain from them.
Finding more Failures as Time Moves on
As you get better at resolving egregious errors, the errors become more subtle and you need to modify your tolerances to find weaker signals indicating errors.
Treat applications as experiments where everything is analyzed, rather than stringent compliance and standardization.
Redefine Failure and Encourage Calculated Risk Taking
Create a culture where people are comfortable with surfacing and learning from failures.
It seems counter-intuitive, but by allowing more failures this also means that you’re moving the ball forward.
Inject Production Failures
The purpose is to make sure failures can happen in controlled ways.
We should think about making our systems crash in a way that keeps the key components protected as much as possible i.e. graceful degradation.
Use Game Days to Rehearse Failures
“A service is not really tested until we break it in production.”
Jesse Robbins
Introduce large-scale fault injection across your critical systems.
These gamedays are scheduled with a goal, like maybe losing connectivity to a data center.
This gives everyone time to prepare for what would need to be done to make sure the system still functions, failovers, monitoring, etc.
Take notes of anything that goes wrong, find, fix, and retest.
On gameday, force an outage.
This exposes things you may have missed, not anticipated, etc.
Obviously the goal is to create more resilient systems.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We wrap up the second way from The DevOps Handbook, while Joe has a mystery episode, Michael doesn’t like ketchup, and Allen has a Costco problem.
These show notes, in all of their full sized digital glory, can be found at https://www.codingblocks.net/episode142, where you can join the conversation, for those using their podcast player to read this.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Integrate Hypothesis Driven Development and A/B Testing
“The most inefficient way to test a business model or product idea is to build the complete product to see whether the predicted demand actually exists.”
Jez Humble
Constantly ask should we build it and why? A/B testing will allow us to know if an idea is worthwhile because allows for fast-feedback on what’s working.
Doing these experiments during peak season can allow you to out-experiment the competition.
But this is only possible if you can deploy quickly and reliably.
This allows A/B testing to support rapid, high-velocity experiments.
A/B test is also known as “split testing”.
A/B testing is where one group sees one version of a page or feature and the other group sees another version.
Study from Microsoft found that only about 1/3 of features actually improved the key metric they were trying to move!
The important takeaway? Without measuring the impact of features, you don’t know if you’re adding value or decreasing it while increasing complexity.
Integrate A/B Testing Into Releases
Effective A/B testing is only possible with the ability to do production releases quickly and easily.
Using feature flags allow you to delivery multiple versions of the application without requiring separate hardware to be deployed to.
This requires meaningful telemetry at every level of the stack to understand how the application is being used.
Etsy open-sourced their Feature API, used for online ramp-ups and throttling exposure to features.
Optimizely and Google Analytics offer similar features.
Integrating A/B Testing into Feature Planning
Tie feature changes to actual business goals, i.e. the business has a hypothesis and an expected result and A/B testing allows the business owner to experiment.
The ability to deploy quickly and reliably is what enables these experiments.
Create Processes to Increase Quality
Eliminate the need for “approvals” from those not closely tied to the code being deployed.
Development, Operations and InfoSec should constantly be collaborating.
The Dangers of Change Approval Process
Bad deployments are often attributed to:
Not enough approval processes in place, or
Not good enough testing processes in place
The findings of this is that often, command-and-control environments usually raise the likelihood of bad deployments.
Beware of “Overly Controlling Changes”
Traditional change controls can lead to:
Longer lead times, and/or
Reducing the “strength and immediacy” of the deployment process.
Adding the traditional controls add more “friction” to the deployment process, by:
Multiplying the number of steps in the approval process,
Increasing batch sizes (size of deployments), and/or
Increasing deployment lead times.
People closest to the items know the most about them.
Requiring people further from the problem to do approvals reduces the likelihood of success.
As the distance between the person doing the work and the person approving the work increases, so does the likeliness of failure.
Organizations that rely on change approvals often have worse stability and throughput in their IT systems.
The takeaway is that peer reviews are much more effective than outside approvals.
Enable Coordination and Scheduling of Changes
The more loosely coupled our architecture, the less we have to communicate between teams.
This allows teams to make changes in a much more autonomous way.
This doesn’t mean that communication isn’t necessary, sometimes you HAVE to speak to someone.
Especially true when overarching infrastructure changes are necessary.
Enable Peer Review of Changes
Those who are familiar with the systems are better to review the changes.
Smaller changes are much better.
The size of a change is not linear with the risk of the change. As the size of a change increases, the risk goes up by way more than a factor of one,
Prefer short lived branches.
“Scarier” changes may require more than just one reviewer.
Potential Dangers of Doing More Manual Testing and Change Freezes
The more manual testing you do, the slower you are to release.
The larger the batch sizes, the slower you are to release.
Enable Pair Programing to Improve all our Changes
“I can’t help wondering if pair programming is nothing more than code review on steroids.”
Jeff Atwood
Pair programming forces communication that may never have happened.
Pair programming brings many more design alternatives to life.
It also reduces bottlenecks of code reviews.
Evaluating the Effectiveness of Pull Request Processes
Look at production outages and tie them back to the peer reviews.
The pull request should have good information about what the context of the change is:
Sufficient detail on why the change is being made,
How the change was made, and
Any risks associated with it.
Fearlessly Cut Bureaucratic Processes
The goal should be to reduce the amount of outside approvals, meetings, and signoffs that need to happen to deploy the application.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We gather around the water cooler to discuss some random topics, while Joe sends too many calendar invites, Allen interferes with science, and Michael was totally duped.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode141. As Joe would say, check it out and join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Bind Docker inside a running container to the host’s Docker instance to use Docker within Docker by adding the following to your Docker run command: -v /var/run/docker.sock:/var/run/docker.sock
We learn the secrets of a safe deployment practice while continuing to study The DevOps Handbook as Joe is a cartwheeling acrobat, Michael is not, and Allen is hurting, so much.
For those of you that are reading these show notes via their podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode140.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Developers complain about operations not wanting to deploy their code.
Given a button for anyone to push to deploy, nobody wants to push it.
The solution is to deploy code with quick feedback loops.
If there’s a problem, fix it quickly and add new telemetry to track the fix.
Puts the information in front of everyone so there are no secrets.
This encourages developers to write more tests and better code and they take more pride in releasing successful deployments.
An interesting side effect is developers are willing to check in smaller chunks of code because they know they’re safer to deploy and easier to reason about.
This also allows for frequent production releases with constant, tight feedback loops.
Automating the deployment process isn’t enough. You must have monitoring of your telemetry integrated into that process for visibility.
Use Telemetry to Make Deployments Safer
Always make sure you’re monitoring telemetry when doing a production release,
If anything goes wrong, you should see it pretty immediately.
Nothing is “done” until it is operating as expected in the production environment.
Just because you improve the development process, i.e. more unit tests, telemetry, etc., that doesn’t mean there won’t be issues. Having these monitors in place will enable you to find and fix these issues quicker and add more telemetry to help eliminate that particular issue from happening again going forward.
Production deployments are one of the top causes of production issues.
This is why it’s so important to overlay those deployments on the metric graphs.
Pager Duty – Devs and Ops together
Problems sometimes can go on for extremely long periods of time.
Those problems might be sent off to a team to be worked on, but they get deprioritized in lieu of some features to be added.
The problems can be a major problem for operations, but not even a blip on the radar of dev.
Upstream work centers that are optimizing for themselves reduces performance for the overall value stream.
This means everyone in the value stream should share responsibility for handing operational incidents.
When developers were awakened at 2 AM, New Relic found that issues were fixed faster than ever.
Business goals are not achieved when features have been marked as “done”, but instead only when they are truly operating properly.
Have Developers Follow Work Downstream
Having a developer “watch over the shoulder” of end-users can be very eye-opening.
This almost always leads to the developers wanting to improve the quality of life for those users.
Developers should have to do the same for the operational side of things.
They should endure the pain the Ops team does to get the application running and stable.
When developers do this downstream, they make better and more informed decisions in what they do daily, in regards to things such as deployability, manageability, operability, etc.
Developers Self-Manage Their Production Service
Sometimes deployments break in production because we learn operational problems too late in the cycle.
Have developers monitor and manage the service when it first launches before handing over to operations.
This is practiced by Google.
Ops can act as consultants to assist in the process.
Launch guidance:
Defect counts and severity
Type and frequency of pager alerts
Monitoring coverage
System architecture
Deployment process
Production hygiene
If these items in the checklist aren’t met, they should be addressed before being deployed and managed in production.
Any regulatory compliance necessary? If so, you now have to manage technical AND security / compliance risks.
Create a service hand back mechanism. If a production service becomes difficult to manage, operations can hand it back to the developers.
Think of it as a pressure release valve.
Google still does this and shows a mutual respect between development and operations.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
Improve mobile user experience with Datadog Mobile Real User Monitoring (Datadog)
We discuss using the venv Python module to create seperate virtual environments, allowing each to have their own version dependencies. (docs.python.org)
To use venv,
Create the virtual environment: python -m venv c:\path\to\myenv
Activate the virtual environment: c:\path\to\myenv\Scripts\activate.bat
NOTE that the venv module documentation includes the variations for different OSes and shells.
We’re using telemetry to fill in the gaps and anticipate problems while discussing The DevOps Handbook, while Michael is still weird about LinkedIn, Joe knows who’s your favorite JZ, and Allen might have gone on vacation.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Survey Says
Joe’s Super Secret Survey
News
Thank you to everyone that left us a new review:
iTunes: AbhiZambre, Traz3r
Stitcher: AndyIsTaken
Most important things to do for new developer job seekers?
I Got 99 Problems and DevOps ain’t One
Find and Fill Any Gaps
Once we have telemetry in place, we can identify any gaps in our metrics, especially in the following levels of our application:
Business level – These are metrics on business items, such as sales transactions, signups, etc.
Application level – This includes metrics such as timing metrics, errors, etc.
Infrastructure level – Metrics at this level cover things like databases, OS’s, networking, storage, CPU, etc.
Client software level – These metrics include data like errors, crashes, timings, etc.
Deployment pipeline level – This level includes metrics for data points like test suite status, deployment lead times, frequencies, etc.
Application and Business Metrics
Gather telemetry not just for technical bits, but also organizational goals, i.e. things like new users, login events, session lengths, active users, abandoned carts, etc.
Have every business metric be actionable. And if they’re not actionable, they’re “vanity metrics”.
By radiating these metrics, you enable fast feedback with feature teams to identify what’s working and what isn’t within their business unit.
Infrastructure Metrics
Need enough telemetry to identify what part of the infrastructure is having problems.
Graphing telemetry across infrastructure and application allows you to detect when things are going wrong.
Using business metrics along with infrastructure metrics allows development and operations teams to work quickly to resolve problems.
Need the same telemetry in pre-production environments so you can catch problems before they make it to production.
Overlaying other Relevant Information onto Our Metrics
In addition to our business and infrastructure telemetry graphing, you also want to graph your deployments so you can quickly correlate if a release caused a deviation from normal.
There may even be a “settling period” after a deployment where things spike (good or bad) and then return to normal. This is good information to have to see if deployments are acting as expected.
Same thing goes for maintenance. Graphing when maintenance occurs helps you correlate infrastructure and application issues at the time they’re deployed.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
The ONE Metric More Important Than Sales & Subscribers (YouTube)
2020 Developer Survey – Most Loved, Dreaded, and Wanted Languages (Stack Overflow)
Instrument your Python applications with Datadog and OpenTelemetry (Datadog)
Tsunami (GitHub) is a general purpose network security scanner with an extensible plugin system for detecting high severity vulnerabilities with high confidence.
It’s all about telemetry and feedback as we continue learning from The DevOps Handbook, while Joe knows his versions, Michael might have gone crazy if he didn’t find it, and Allen has more than enough muscles.
For those that use their podcast player to read these show notes, did you know that you can find them at https://www.codingblocks.net/episode138? Well, you can. And now you know, and knowing is half the battle.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Survey Says
News
We give a heartfelt thank you in our best announcer voice to everyone that left us a new review!
Implementing the technical practices of the Second Way
Provides fast and continuous feedback from operations to development.
Allows us to find and fix problems earlier on the software development life cycle.
Create Telemetry to Enable Seeing and Solving Problems
Identifying what causes problems can be difficult to pinpoint: was it the code, was it networking, was it something else?
Use a disciplined approach to identifying the problems, don’t just reboot servers.
The only way to do this effectively is to always be generating telemetry.
Needs to be in our applications and deployment pipelines.
More metrics provide the confidence to change things.
Companies that track telemetry are 168 times faster at resolving incidents than companies that don’t, per the 2015 State of DevOps Report (Puppet).
The two things that contributed to this increased MTTR ability was operations using source control and proactive monitoring (i.e. telemetry).
Create Centralized Telemetry Infrastructure
Must create a comprehensive set of telemetry from application metrics to operational metrics so you can see how the system operates as a whole.
Data collection at the business logic, application, and environmental layers via events, logs and metrics.
Event router that stores events and metrics.
This enables visualization, trending, alerting, and anomaly detection.
Transforms logs into metrics, grouping by known elements.
Need to collect telemetry from our deployment pipelines, for metrics like:
How many unit tests failed?
How long it takes to build and execute tests?
Static code analysis.
Telemetry should be easily accessible via APIs.
The telemetry data should be usable without the application that produced the logs
Create Application Logging Telemetry that Helps Production
Dev and Ops need to be creating telemetry as part of their daily work for new and old services.
Should at least be familiar with the standard log levels
Debug – extremely verbose, logs just about everything that happens in an application, typically disabled in production unless diagnosing a problem.
Info – typically action based logging, either actions initiated by the system or user, such as saving an order.
Warn – something you log when it looks like there might be a problem, such as a slow database call.
Error – the actual error that occurs in a system.
Fatal – logs when something has to exit and why.
Using the appropriate log level is more important than you think
Low toner is not an Error. You wouldn’t want to be paged about low toner while sleeping!
Examples of some things that should be logged:
Authentication events,
System and data access,
System and app changes,
Data operations (CRUD),
Invalid input,
Resource utilization,
Health and availability,
Startups and shutdowns,
Faults and errors,
Circuit breaker trips,
Delays,
Backup success and failure
Use Telemetry to Guide Problem Solving
Lack of telemetry has some negative issues:
People use it to avoid being blamed for problems, which can be due to a political atmosphere and SUPER counter-productive.
Telemetry allows for scientific methods of problem solving to be used.
This approach leads to faster MTTR and a much better relationship between Dev and Ops.
Enable Creation of Production Metrics as Part of Daily Work
This needs to be easy, one-line implementations.
StatsD, often used with Graphite or Graphana, creates timers and counters with a single line of code.
Use data to generate graphs, and then overlay those graphs with production changes to see if anything changed significantly.
This gives you the confidence to make changes.
Create Self-Service Access to Telemetry and Information Radiators
Make the data available to anyone in the value stream without having to jump through hoops to get it, be they part of Development, Operations, Product Management, or Infosec, etc.
Information radiators are displays which are placed in highly visible locations so everyone can see the information quickly.
Nothing to hide from visitors OR from the team itself.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
Disable all of your VS Code extensions and then re-enable just the ones you need using CTRL+SHIFT+P. (code.visualstudio.com)
Color code your environments in Datagrip! Right click on the server and select Color Settings. Use green for local and red for everything else to easily differentiate between the two. Can be applied at the server and/or DB levels. For example, color your default local postgres database orange. This color coding will be applied to both the navigation tree and the open file editors (i.e. tabs).
Our journey into the world of DevOps continues with The DevOps Handbook as Michael doesn’t take enough tangents, Joe regrets automating the build, err, wait never regrets (sorry), and ducks really like Allen.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode137, where you can be a part of the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
That System76 Oryx Pro keyboard though? (System76)
Fast, Reliable. Pick Two
Continuously Build, Test, and Integrate our Code and Environments
Build and test processes run constantly, independent of coding.
This ensures that we understand and codify all dependencies.
This ensures repeatable deployments and configuration management.
Once changes make it into source control, the packages and binaries are created only ONCE. Those same packages are used throughout the rest of the pipeline to ensure all environments are receiving the same bits.
What does this mean for our team culture?
You need to maintain reliable automated tests that truly validate deploy-ability.
You need to stop the “production pipeline” when validation fails, i.e. pull the andon cord.
You need to work in small, short lived batches that are based on trunk. No long-lived feature branches.
Short, fast feedback loops are necessary; builds on every commit.
Integrate Performance Testing into the Test Suite
Should likely build the performance testing environment at the beginning of the project so that it can be used throughout.
Logging results on each run is also important. If a set of changes shows a drastic difference from the previous run, then it should be investigated.
Enable and Practice Continuous Integration
Small batch and andon cord style development practices optimize for team productivity.
Long lived feature branches optimize for individual productivity. But:
They require painful integration periods, such as complex merges, which is “invisible work”.
They can complicate pipelines.
The integration complexity scales exponentially with the number of feature branches in play.
They can make adding new features, teams, and individuals to a team really difficult.
Trunk based development has some major benefits such as:
Merging more often means finding problems sooner.
It moves us closer to “single piece flow”, such as single envelope at a time story, like one big assembly line.
Automate and Enable Low-Risk Releases
Small batch changes are inherently less risky.
The time to fix is strongly correlated with the time to remediate, i.e. the mean time to find (MTF) and the mean time to remediate (MTR).
Automation needs to include operational changes, such as restarting services, that need to happen as well.
Enable “self-service” deployments. Teams and individuals need to be able to dynamically spin up reliable environments.
Decouple Deployments from Releases
Releases are marketing driven and refer to when features are made available to customers.
Feature flags can be used to toggle the release of functionality independent of their deployments.
Feature flags enable roll back, graceful degradation, graceful release, and resilience.
Architect for Low-Risk Releases
Don’t start over! You make a lot of the same mistakes, and new ones, and ultimately end up at the same place. Instead, fix forward!
Use the strangler pattern instead to push the good stuff in and push the bad stuff out, like how strangler vines grow to cover and subsume a fig tree.
Decouple your code and architecture.
Use good, strong versioned APIs, and dependency management to help get there.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We begin our journey into the repeatable world of DevOps by taking cues from The DevOps Handbook, while Allen loves all things propane, Joe debuts his “singing” career with his new music video, and Michael did a very bad, awful thing.
It’s a collection of arguments and high level guidance for understanding the spirit of DevOps.
It’s light on specifics and heavy on culture. The tools aren’t the problem here, the people need to change.
It’s also a book about scaling features, teams, people, and environments.
The First Way: The Principles of Flow
The Deployment Pipeline is the Foundation
Continuous delivery:
Reduces the risk associated with deploying and releasing changes.
Allows for an automated deployment pipeline.
Allows for automated tests.
Environments on Demand
Always use production like environments at every stage of the stream.
Environments must be created in an automated fashion.
Should have all scripts and configurations stored in source control.
Should require no intervention from operations.
The reality though …
Often times the first time an application is tested in a production like environment, is in production.
Many times test and development environments are not configured the same.
Ideally though …
Developers should be running their code in production like environments from the very beginning, on their own workstations.
This provides an early and constant feedback cycle.
Rather than creating wiki pages on how to set things up, the configurations and scripts necessary are committed to source control. This can include any of all of the following:
Copying virtualized environments.
Building automated environments on bare metal.
Using infrastructure as code, i.e. Puppet, Chef, Ansible, Salt, CFEngine, etc.
Using automated OS configuration tools.
Creating environments from virtual images or containers.
Creating new environments in public clouds.
All of this allows entire systems to be spun up quickly making this …
A win for operations as they don’t have to constantly battle configuration problems.
A win for developers because they can find and fix things very early in the development process that benefits all environments.
“When developers put all their application source files and configurations in version control, it becomes the single repository of truth that contains the precise intended state of the system.”
The DevOps Handbook
Check Everything into One Spot, that Everybody has Access to
Here are the types of things that should be stored in source control:
All application code and its dependencies (e.g. libraries, static content, etc.)
Scripts for creating databases, lookup data, etc.
Environment creation tools and artifacts (VMWare, AMI images, Puppet or Chef recipes).
Files used to create containers (Docker files, Rocket definition files, etc.)
All automated tests and manual scripts.
Scripts for code packaging, deployments, database migrations, and environment provisioning.
Additional artifacts such as documentation, deployment procedures, and release notes.
Cloud configuration files, such as AWS CloudFormation templates, Azure ARM templates, Terraform scripts, etc.)
All scripts or configurations for infrastructure supporting services for things like services buses, firewalls, etc.
Make Infrastructure Easier to Rebuild than to Repair
Treat servers like cattle instead of pets, meaning, rather than care for and fix them when they’re broken, instead delete and recreate them.
This has the side effect of keeping your architecture fluid.
Some have adopted immutable infrastructure where manual changes to environments are not allowed. Instead, changes are in source control which removes variance among environments.
The Definition of Done
“Done” means your changeset running in a production-like environment.
This ensures that developers are involved in getting code to production and bring operations closer to the code.
Enable Fast and Reliable Automated Testing
Automated tests let you move faster, with more confidence, and shortens feedback cycles for catching and fixing problems earlier.
Automated testing allowed the Google Web Server team to go from one of the least productive, to most productive group in the company.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We review the Stack Overflow Developer Survey in the same year it was created for the first time ever, while Joe has surprising news about the Hanson Brothers, Allen doesn’t have a thought process, and Michael’s callback is ruined.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes and join the conversation at https://www.codingblocks.net/episode135.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
As we learn from Google about how to navigate a code review, Michael learns to not give out compliments, Joe promises to sing if we get enough new reviews, and Allen introduces a new section to the show.
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Survey Says
News
Thank you, we appreciate the latest reviews:
Stitcher: Jean Guillaume Misteli, gitterskow
LGTM
Navigating a CL in Review
A couple starting questions when reviewing a CL (changelist):
Does the change make sense?
Does the CL have a good description?
Take a broad view of the CL
If the change doesn’t make sense, you need to immediately respond with WHY it shouldn’t be there.
Typically if you do this, you should probably also respond with what they should have done.
Be courteous.
Give a good reason why.
If you notice that you’re getting more than a single CL or two that doesn’t belong, you should consider putting together a quick guide to let people know what should be a part of CL’s in a particular area of code
This will save a lot of work and frustration.
Examine the main parts of the CL
Look at the file with the most changes first as that will typically aid in figuring out the rest of the CL quicker.
The smaller changes are usually part of that bigger change.
Ask the developer to point you in the right direction.
Ask to have the CL split into multiple smaller CL’s
If you see a major problem with the CL, you need to send that feedback immediately, maybe even before you look at the rest of the CL.
Might be that the rest of the CL isn’t even legit any longer if the major problem ends up being a show stopper.
Why’s it so important to review and send out feedback quickly?
Developers might be moving onto their next task that built off the CL in review. You want to reduce the amount of wasted effort.
Developers have deadlines they have to meet so if there’s a major change that needs to happen, they need to find out about it as soon as possible.
Look at the rest of the CL in an appropriate sequence
Looking at files in a meaningful order will help understanding the CL.
Reviewing the unit tests first will help with a general understanding of the CL.
Speed of Code Reviews
Velocity of the team is more important than the individual.
The individual slacking on the review gets other work done, but they slow things down for the team.
Looking at the other files in the CL in a meaningful order may help in speed and understanding of the CL.
If there are long delays in the process, it encourages rubber stamping.
One business day is the maximum to time to respond to a CL.
You don’t have to stop your flow immediately though. Wait for a natural break point, like after lunch or a meeting.
The primary focus on response time to the CL.
When is it okay to LGTM (looks good to me)?
The reviewer trusts the developer to address all of the issues raised.
The changes are minor.
How to write code review comments
Be kind.
Explain your reasoning.
Balance giving directions with pointing out problems.
Encourage simplifications or add comments instead of just complaining about complexity.
Courtesy is important.
Don’t be accusatory.
Don’t say “Why did you…”
Say “This could be simpler by…”
Explain why things are important.
It’s the developer’s responsibility to fix the code, not the reviewer’s. It’s sufficient to state the problem.
Code review comments should either be conveyed in code or code comments. Pull request comments aren’t easily searchable.
Handling pushback in code reviews
When the developer disagrees, consider if they’re right. They are probably closer to the code than you.
If you believe the CL improves things, then don’t give up.
Stay polite.
People tend to get more upset about the tone of comments, rather than the reviewers insistence on quality.
The longer you wait to clean-up, the less likely the clean-up is to happen. Better to block the request up front then move on.
Having a standard to point to clears up a lot of disputes.
Change takes time, people will adjust.
Resources We Like
Google Engineering Practices Documentation (GitHub)
We learn what to look for in a code review while reviewing Google’s engineering practices documentation as Michael relates patterns to choo-choos, Joe has a “weird voice”, and Allen has a new favorite portion of the show.
Are you reading this via your podcast player? You can find this episode’s full show notes at https://www.codingblocks.net/episode133 where you can also join the conversation.
This is the MOST IMPORTANT part of the review: the overall design of the changelist (CL).
Does the code make sense?
Does it belong in the codebase or in a library?
Does it meld well with the rest of the system?
Is it the right time to add it to the code base?
Functionality
Does the CL do what it’s supposed to do?
Even if it does what it’s supposed to do, is it a good change for the users, both developers and actual end-users?
As a reviewer, you should be thinking about all the edge-cases, concurrency issues, and generally just trying to see if any bugs arise just looking at the code.
As a reviewer, you can verify the CL if you’d like, or have the developer walk you through the changes (the actual implemented changes rather than just slogging through code).
Google specifically calls out parallel programming types of issues that are hard to reason about (even when debugging) especially when it comes to deadlocks and similar types of situations.
Complexity
This should be checked at every level of the change:
Single lines of code,
Functions, and
Classes
Too complex is code that is not easy to understand just looking at the code. Code like this will potentially introduce bugs as developers need to change it in the future.
A particular type of complexity is over-engineering, where developers have made the code more generic than it needs to be, or added functionality that isn’t presently needed by the system. Reviewers should be especially vigilant about over-engineering. Encourage developers to solve the problem they know needs to be solved now, not the problem that the developer speculates might need to be solved in the future. The future problem should be solved once it arrives and you can see its actual shape and requirements in the physical universe.
Google’s Engineering Practices documentation
Tests
Usually tests should be added in the same CL as the change, unless the CL is for an emergency.
If something isn’t in the style guide, and as the reviewer you want to comment on the CL to make a point about style, prefix your comment with “Nit”.
DO NOT BLOCK PR’s based on personal style preference!
Style changes should not be mixed in with “real” changes. Those should be a separate CL.
Consistency
Google indicates that if existing code conflicts with the style guide, the style guide wins.
If the style guide is a recommendation rather than a hard requirement, it’s a judgement call on whether to follow the guide or existing code.
If no style guide applies, the CL should remain consistent with existing code.
Use TODO statements for cleaning up existing code if outside the scope of the CL.
Documentation
If the CL changes any significant portion of builds, interactions, tests, etc., then appropriate README’s, reference docs, etc. should be updated.
If the CL deprecates portions of the documentation, that should also likely be removed.
Every Line
Look over every line of non-generated, human written code.
You need to at least understand what the code is doing.
If you’re having a hard time examining the code in a timely fashion, you may want to ask the developer to walk you through it.
If you can’t understand it, it’s very likely future developers won’t either, so getting clarification is good for everyone.
If you don’t feel qualified to be the only reviewer, make sure someone else reviews the CL who is qualified, especially when you’re dealing with sensitive subjects such as security, concurrency, accessibility, internationalization, etc.
Context
Sometimes you need to back up to get a bigger view of what’s changing, rather than just looking at the individual lines that changed.
Seeing the whole file versus the few lines that were changed might reveal that 5 lines were added to a 200 line method which likely needs to be revisited.
Is the CL improving the health of the system?
Is the CL complicating the system?
Is the CL making the system more tested or less tested?
“Don’t accept CLs that degrade the code health of the system.”
Most systems become complex through many small changes.
Good Things
If you see something good in a CL, let the author know.
Many times we focus on mistakes as reviewers, but some positive reinforcement may actually be more valuable.





































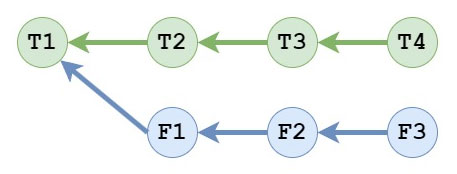
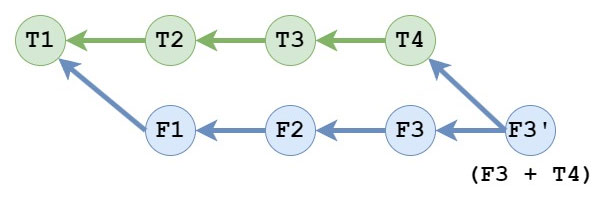



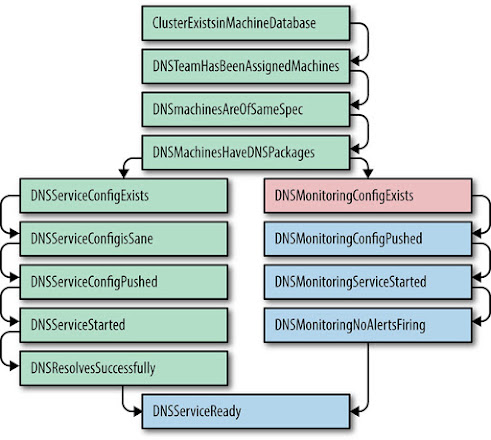














 Check out PowerLevel10k
Check out PowerLevel10k