It’s the end of 2020. We’re all tired. So we phone it in for the last episode of the year as we discuss the State of the Octoverse, while Michael prepared for the wrong show (again), Allen forgot to pay his ISP bill and Joe’s game finished downloading.
In case you’re wondering where you can find these show notes in all there 1:1 pixel digital glory because you’re reading them via your podcast app, you can find them at https://www.codingblocks.net/episode148, where you can also join the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Survey Says
News
Joe will be speaking at the virtual San Diego Elastic Meetup, Tuesday, January 19, 2021 at 5:00 PM PST, talking about Easy Local Development with Elastic Cloud on Kubernetes using Skaffold.
We discuss the things we’re excited about for 2021 as Michael prepared for a different show, Joe can’t stop looking at himself, and Allen gets paid by the tip of the week.
Command Line Heroes – A podcast that tells the epic true tales of developers, programmers, hackers, geeks, and open source rebels who are revolutionizing the technology landscape.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
We learn all the necessary details to get into the world of developer game jams, while Michael triggers all parents, Allen’s moment of silence is oddly loud, and Joe hones his inner Steve Jobs.
If you’re reading these show notes via your podcast player and wondering where you can find them in your browser, well wonder no more. These show notes can be found at https://www.codingblocks.net/episode146 in all their 8-bit glory. Check it out and join the conversation.
Sponsors
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
We wrap up our deep dive into The DevOps Handbook, while Allen ruined Halloween, Joe isn’t listening, and Michael failed to… forget it, it doesn’t even matter.
If you’re reading this via your podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode145 where you can join the conversation, as well find past episode’s show notes.
Sponsors
Command Line Heroes – A podcast that tells the epic true tales of developers, programmers, hackers, geeks, and open source rebels who are revolutionizing the technology landscape.
Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
xMatters – Sign up today to learn how to take control of your incident management workflow and get a free xMatters t-shirt.
Survey Says
News
Thank you to everyone that left us a new review!
iTunes: AbhishekN12, Streichholzschächtelchen Mann
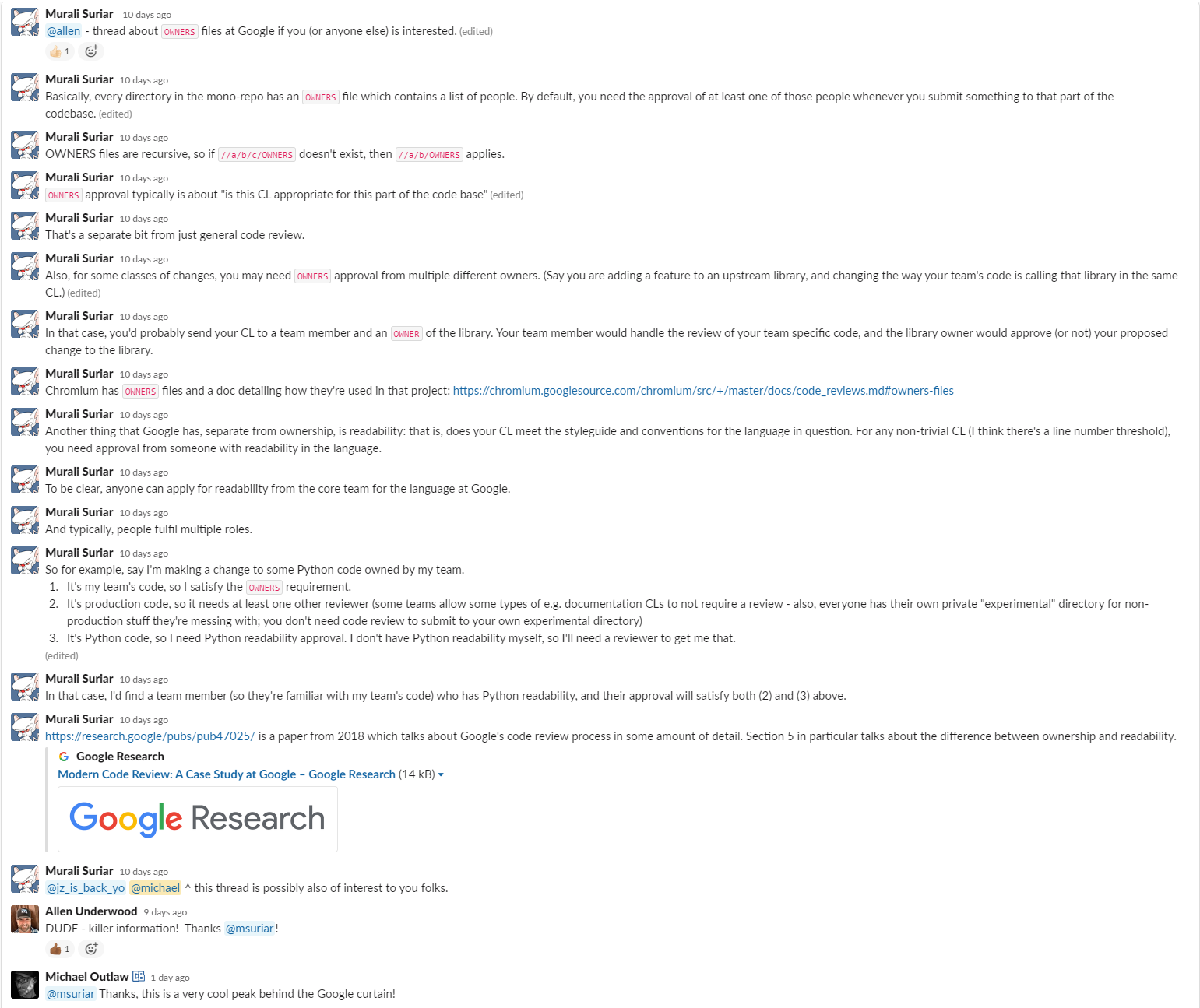
Use Chat Rooms and Bots to Automate and Capture Organizational Knowledge
Chat rooms have been increasingly used for triggering actions.
One of the first to do this was ChatOps at GitHub. By integrating automation tools within the chat, it was easy for people to see exactly how things were done.
Everyone sees what’s happening.
Onboarding is nice because people can look through the history and see how things work.
This helps enable fast organizational learning.
Another benefit is that typically chat rooms are public. so it creates an environment of transparency.
One of the more beneficial outcomes was that ops engineers were able to discover problems quickly and help each other out more easily.
“Even when you’re new to the team, you can look in the chat logs and see how everything is done. It’s as if you were pair-programming with them all the time.”
Jesse Newland
Automate Standardized Processes in Software for Re-Use
Often times developers document things in wikis, SharePoint systems, word documents, excel documents, etc., but other developers aren’t aware these documents exist so they do things a different way, and you end up with a bunch of disparate implementations.
The solution is to put these processes and standards into executable code stored in a repository.
Create a Single, Shared Source Code Repository for Your Entire Organization
This single repository enables quick of sharing amongst an entire organization.
In 2015, Google had a single repository with over 1 billion files over 2 billion lines of code. This single repository is used by every software engineer and every product.
This repository doesn’t just include code, but also:
Configuration standards for libraries, infrastructure and environments like Chef, Ansible, etc.,
Deployment tools,
Testing standards and tools as well as security,
Deployment pipeline tools,
Monitoring and analysis tools, and
Tutorials and standards.
Whenever a commit goes in, everything is built from code in the shared repo: no dynamic linking. This ensures everything works with the latest code in the repository.
By building everything off a single source tree, Google eliminates the problems you encounter when you use external dependency management systems like Artifactory, Nuget, etc.
Spread Knowledge by Using Automated Tests as Documentation and Communities of Practice
Sharing libraries throughout an organization means you need a good way of sharing expertise and improvements.
Automated tests are a great way to ensure things work with new commits and they are self-documenting.
TDD turns tests into up-to-date specifications of a system.
Want to know how to use the library? Take a look at the test suites.
Ideally you want to have one group responsible for owning and supporting a library.
Ideally you only ever have one version of that code out in production. It will contain the current best collaborative knowledge of the organization.
The owner is also responsible for migrating each consumer of the library to the next version.
This requires the consumers to have a good suite of automated testing as well.
Another great use of chat rooms is to have one for each library.
Design for Operations Through Codified Non-Functional Requirements
When developers are responsible for incident response in their deployed applications, their applications become better designed for operations.
As developers are involved in non-functional requirements, we design our systems for faster deployment, better reliability, the ability to detect problems, and allow for graceful degradation.
Some of these non-functionals are:
Production telemetry,
Ability to track dependencies,
Resilient and gracefully degrading services,
Forward and backward compatibility between versions,
Ability to archive data to reduce size requirements,
Ability to search and understand log messages,
Ability to trace requests through multiple services, and
Centralized runtime configurations.
Build Reusable Operations User Stories into Development
When there is ops works that needs to be done but can’t be fully automated, we need to make them as repeatable and deterministic as we can.
Automate as much as possible.
Document the rest for operations.
Automation for handoffs is also helpful.
By having these workflows and handoffs in place, it’s easier to measure and forecast future needs and ETAs.
Ensure Technology Choices Help Achieve Organizational Goals
Any technology introduced, introduces more pressure on operations for support.
If operations cannot support it, then the group that owns the service or library becomes a bottleneck, which could be a major problem.
Always be identifying technologies that appear to be the problem areas. Maybe they:
Slow the flow of work,
Create high levels of unplanned work (i.e. fire fighting),
Unbalanced number of support requests, and/or
Don’t really meet organizational goals, such as stability, throughput, etc.
This doesn’t mean don’t use new technologies or languages, but know that your level of support greatly diminishes as you go into uncharted territories.
Reserve time to Create Organizational Learning and Improvement
Dedicate time over several days to attack and resolve a particular problem or issue.
Use people outside the process to assist those inside the process.
The most intense methodology is a 30 day focus group with coaches and engineers that focus on solving real company problems.
Not uncommon to solve in days what used to take months
Institutionalize Rituals to Pay Down Technical Debt
Schedule time, a few days, a week, whatever, to fix problems you care about. No feature work allowed.
Could be code problems, environment, configuration, etc.
Usually want to include people from different teams working together, i.e. operations, developers, InfoSec, etc.
Present accomplishments at the end of the blitz
Enable Everyone to Teach and Learn
Everyone should be encouraged to teach and learn in their own ways.
It’s becoming more important than ever for folks to have knowledge in more than just one area to be successful.
Encourage cross functional pollination, i.e. have operations show developers how they do something, or vice versa.
Share Your Experiences from DevOps Conferences
Organizations should encourage their employees to attend and/or speak at conferences.
Hold your own company conference, even if it’s just for your small team.
Create Internal Consulting and Coaches to Spread Practices
Encourage your SME’s to have office hours where they’ll answer technical questions.
Create groups with missions to help the organization move forward.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
DevOps: Job Title or Job Responsibility? (episode 118)
Tip of the Week
Diff syntax highlighting in Github Markdown (Stack Overflow)
Code Chefs – Hungry Web Developer Podcast (Apple Podcasts)
Maria, a coding environment for beginners (maria.cloud)
CodeWorld, create drawings, animations, and games using math, shapes, colors, and transformations. (code.world)
Generation numbers and preconditions – Apply preconditions to guarantee atomicity of multi-step transactions with object generation numbers to uniquely identify data resources. (cloud.google.com)
helm search repo – Search repositories for a keyboard in charts. (helm.sh)
Use -cur_console:p5 in your cmder WSL profile to ensure that the arrow keys work as expected on Windows 10 (GitHub)
cmder – A portable console emulator for Windows (cmder.net)
It’s our favorite time of year where we discuss all of the new ways we can spend our money in time for the holidays, as Allen forgets a crucial part, Michael has “neons”, and Joe has a pet bear.
Reading this via your podcast player? If so, you can find this episode’s full show notes at https://www.codingblocks.net/episode144, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Teamistry – A podcast that tells the stories of teams who work together in new and unexpected ways, to achieve remarkable things.
We dive into the benefits of enabling daily learning into our processes, while it's egregiously late for Joe, Michael's impersonation is awful, and Allen's speech is degrading.
This episode’s show notes can be found at https://www.codingblocks.net/episode143, for those reading this via their podcast player, where you can join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Teamistry – A podcast that tells the stories of teams who work together in new and unexpected ways, to achieve remarkable things.
Survey Says
News
Thank you to everyone that left us a new review!
iTunes: John Roland, Shefodorf, DevCT, Flemon001, ryanjcaldwell, Aceium
Stitcher: Helia
Allen saves your butt with his latest chair review on YouTube.
Enable and Inject Learning into Daily Work
To work on complex systems effectively and safely we must get good at:
Detecting problems,
Solving problems, and
Multiplying the effects by sharing the solutions within the organization.
The key is treating failures as an opportunity to learn rather than an opportunity to punish.
Establish a Just, Learning Culture
By promoting a culture where errors are “just” it encourages learning ways to remove and prevent those errors.
On the contrary, an “unjust” culture, promotes bureaucracy, evasion, and self-protection.
This is how most companies and management work, i.e. put processes in place to prevent and eliminate the possibility of errors.
Rather than blaming individuals, take moments when things go wrong as an opportunity to learn and improve the systems that will inevitably have problems.
Not only does this improve the organization’s systems, it also strengthens relationships between team members.
When developers do cause an error and are encouraged to share the details of the errors and how to fix them, it ultimately benefits everyone as the fear of consequences are lowered and solutions on ensuring that particular problem isn’t encountered again increase.
Blameless Post Mortem
Create timelines and collect details from many perspectives.
Empower engineers to provide details of how they may have contributed to the failures.
Encourage those who did make the mistakes to share those with the organization and how to avoid those mistakes in the future.
Don’t dwell on hindsight, i.e. the coulda, woulda, and shoulda comments.
Propose countermeasures to ensure similar failures don’t occur in the future and schedule a date to complete those countermeasures.
Stakeholders that should be present at these meetings
People who were a part of making the decisions that caused the problem.
People who found the problem.
People who responded to the problem.
People who diagnosed the problem.
People who were affected by the problem.
Anyone who might want to attend the meeting.
The meeting
Must be rigorous about recording the details during the process of finding, diagnosing, and fixing, etc.
Disallow phrases like “could have” or “should have” because they are counterproductive.
Reserve enough time to brainstorm countermeasures to implement.
These must be prioritized and given a timeline for implementation.
Publish the learnings and timelines, etc. from the meeting so the entire organization can gain from them.
Finding more Failures as Time Moves on
As you get better at resolving egregious errors, the errors become more subtle and you need to modify your tolerances to find weaker signals indicating errors.
Treat applications as experiments where everything is analyzed, rather than stringent compliance and standardization.
Redefine Failure and Encourage Calculated Risk Taking
Create a culture where people are comfortable with surfacing and learning from failures.
It seems counter-intuitive, but by allowing more failures this also means that you’re moving the ball forward.
Inject Production Failures
The purpose is to make sure failures can happen in controlled ways.
We should think about making our systems crash in a way that keeps the key components protected as much as possible i.e. graceful degradation.
Use Game Days to Rehearse Failures
“A service is not really tested until we break it in production.”
Jesse Robbins
Introduce large-scale fault injection across your critical systems.
These gamedays are scheduled with a goal, like maybe losing connectivity to a data center.
This gives everyone time to prepare for what would need to be done to make sure the system still functions, failovers, monitoring, etc.
Take notes of anything that goes wrong, find, fix, and retest.
On gameday, force an outage.
This exposes things you may have missed, not anticipated, etc.
Obviously the goal is to create more resilient systems.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We wrap up the second way from The DevOps Handbook, while Joe has a mystery episode, Michael doesn’t like ketchup, and Allen has a Costco problem.
These show notes, in all of their full sized digital glory, can be found at https://www.codingblocks.net/episode142, where you can join the conversation, for those using their podcast player to read this.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Integrate Hypothesis Driven Development and A/B Testing
“The most inefficient way to test a business model or product idea is to build the complete product to see whether the predicted demand actually exists.”
Jez Humble
Constantly ask should we build it and why? A/B testing will allow us to know if an idea is worthwhile because allows for fast-feedback on what’s working.
Doing these experiments during peak season can allow you to out-experiment the competition.
But this is only possible if you can deploy quickly and reliably.
This allows A/B testing to support rapid, high-velocity experiments.
A/B test is also known as “split testing”.
A/B testing is where one group sees one version of a page or feature and the other group sees another version.
Study from Microsoft found that only about 1/3 of features actually improved the key metric they were trying to move!
The important takeaway? Without measuring the impact of features, you don’t know if you’re adding value or decreasing it while increasing complexity.
Integrate A/B Testing Into Releases
Effective A/B testing is only possible with the ability to do production releases quickly and easily.
Using feature flags allow you to delivery multiple versions of the application without requiring separate hardware to be deployed to.
This requires meaningful telemetry at every level of the stack to understand how the application is being used.
Etsy open-sourced their Feature API, used for online ramp-ups and throttling exposure to features.
Optimizely and Google Analytics offer similar features.
Integrating A/B Testing into Feature Planning
Tie feature changes to actual business goals, i.e. the business has a hypothesis and an expected result and A/B testing allows the business owner to experiment.
The ability to deploy quickly and reliably is what enables these experiments.
Create Processes to Increase Quality
Eliminate the need for “approvals” from those not closely tied to the code being deployed.
Development, Operations and InfoSec should constantly be collaborating.
The Dangers of Change Approval Process
Bad deployments are often attributed to:
Not enough approval processes in place, or
Not good enough testing processes in place
The findings of this is that often, command-and-control environments usually raise the likelihood of bad deployments.
Beware of “Overly Controlling Changes”
Traditional change controls can lead to:
Longer lead times, and/or
Reducing the “strength and immediacy” of the deployment process.
Adding the traditional controls add more “friction” to the deployment process, by:
Multiplying the number of steps in the approval process,
Increasing batch sizes (size of deployments), and/or
Increasing deployment lead times.
People closest to the items know the most about them.
Requiring people further from the problem to do approvals reduces the likelihood of success.
As the distance between the person doing the work and the person approving the work increases, so does the likeliness of failure.
Organizations that rely on change approvals often have worse stability and throughput in their IT systems.
The takeaway is that peer reviews are much more effective than outside approvals.
Enable Coordination and Scheduling of Changes
The more loosely coupled our architecture, the less we have to communicate between teams.
This allows teams to make changes in a much more autonomous way.
This doesn’t mean that communication isn’t necessary, sometimes you HAVE to speak to someone.
Especially true when overarching infrastructure changes are necessary.
Enable Peer Review of Changes
Those who are familiar with the systems are better to review the changes.
Smaller changes are much better.
The size of a change is not linear with the risk of the change. As the size of a change increases, the risk goes up by way more than a factor of one,
Prefer short lived branches.
“Scarier” changes may require more than just one reviewer.
Potential Dangers of Doing More Manual Testing and Change Freezes
The more manual testing you do, the slower you are to release.
The larger the batch sizes, the slower you are to release.
Enable Pair Programing to Improve all our Changes
“I can’t help wondering if pair programming is nothing more than code review on steroids.”
Jeff Atwood
Pair programming forces communication that may never have happened.
Pair programming brings many more design alternatives to life.
It also reduces bottlenecks of code reviews.
Evaluating the Effectiveness of Pull Request Processes
Look at production outages and tie them back to the peer reviews.
The pull request should have good information about what the context of the change is:
Sufficient detail on why the change is being made,
How the change was made, and
Any risks associated with it.
Fearlessly Cut Bureaucratic Processes
The goal should be to reduce the amount of outside approvals, meetings, and signoffs that need to happen to deploy the application.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We gather around the water cooler to discuss some random topics, while Joe sends too many calendar invites, Allen interferes with science, and Michael was totally duped.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode141. As Joe would say, check it out and join the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Bind Docker inside a running container to the host’s Docker instance to use Docker within Docker by adding the following to your Docker run command: -v /var/run/docker.sock:/var/run/docker.sock
We learn the secrets of a safe deployment practice while continuing to study The DevOps Handbook as Joe is a cartwheeling acrobat, Michael is not, and Allen is hurting, so much.
For those of you that are reading these show notes via their podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode140.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Developers complain about operations not wanting to deploy their code.
Given a button for anyone to push to deploy, nobody wants to push it.
The solution is to deploy code with quick feedback loops.
If there’s a problem, fix it quickly and add new telemetry to track the fix.
Puts the information in front of everyone so there are no secrets.
This encourages developers to write more tests and better code and they take more pride in releasing successful deployments.
An interesting side effect is developers are willing to check in smaller chunks of code because they know they’re safer to deploy and easier to reason about.
This also allows for frequent production releases with constant, tight feedback loops.
Automating the deployment process isn’t enough. You must have monitoring of your telemetry integrated into that process for visibility.
Use Telemetry to Make Deployments Safer
Always make sure you’re monitoring telemetry when doing a production release,
If anything goes wrong, you should see it pretty immediately.
Nothing is “done” until it is operating as expected in the production environment.
Just because you improve the development process, i.e. more unit tests, telemetry, etc., that doesn’t mean there won’t be issues. Having these monitors in place will enable you to find and fix these issues quicker and add more telemetry to help eliminate that particular issue from happening again going forward.
Production deployments are one of the top causes of production issues.
This is why it’s so important to overlay those deployments on the metric graphs.
Pager Duty – Devs and Ops together
Problems sometimes can go on for extremely long periods of time.
Those problems might be sent off to a team to be worked on, but they get deprioritized in lieu of some features to be added.
The problems can be a major problem for operations, but not even a blip on the radar of dev.
Upstream work centers that are optimizing for themselves reduces performance for the overall value stream.
This means everyone in the value stream should share responsibility for handing operational incidents.
When developers were awakened at 2 AM, New Relic found that issues were fixed faster than ever.
Business goals are not achieved when features have been marked as “done”, but instead only when they are truly operating properly.
Have Developers Follow Work Downstream
Having a developer “watch over the shoulder” of end-users can be very eye-opening.
This almost always leads to the developers wanting to improve the quality of life for those users.
Developers should have to do the same for the operational side of things.
They should endure the pain the Ops team does to get the application running and stable.
When developers do this downstream, they make better and more informed decisions in what they do daily, in regards to things such as deployability, manageability, operability, etc.
Developers Self-Manage Their Production Service
Sometimes deployments break in production because we learn operational problems too late in the cycle.
Have developers monitor and manage the service when it first launches before handing over to operations.
This is practiced by Google.
Ops can act as consultants to assist in the process.
Launch guidance:
Defect counts and severity
Type and frequency of pager alerts
Monitoring coverage
System architecture
Deployment process
Production hygiene
If these items in the checklist aren’t met, they should be addressed before being deployed and managed in production.
Any regulatory compliance necessary? If so, you now have to manage technical AND security / compliance risks.
Create a service hand back mechanism. If a production service becomes difficult to manage, operations can hand it back to the developers.
Think of it as a pressure release valve.
Google still does this and shows a mutual respect between development and operations.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
Improve mobile user experience with Datadog Mobile Real User Monitoring (Datadog)
We discuss using the venv Python module to create seperate virtual environments, allowing each to have their own version dependencies. (docs.python.org)
To use venv,
Create the virtual environment: python -m venv c:\path\to\myenv
Activate the virtual environment: c:\path\to\myenv\Scripts\activate.bat
NOTE that the venv module documentation includes the variations for different OSes and shells.
We’re using telemetry to fill in the gaps and anticipate problems while discussing The DevOps Handbook, while Michael is still weird about LinkedIn, Joe knows who’s your favorite JZ, and Allen might have gone on vacation.
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Survey Says
Joe’s Super Secret Survey
News
Thank you to everyone that left us a new review:
iTunes: AbhiZambre, Traz3r
Stitcher: AndyIsTaken
Most important things to do for new developer job seekers?
I Got 99 Problems and DevOps ain’t One
Find and Fill Any Gaps
Once we have telemetry in place, we can identify any gaps in our metrics, especially in the following levels of our application:
Business level – These are metrics on business items, such as sales transactions, signups, etc.
Application level – This includes metrics such as timing metrics, errors, etc.
Infrastructure level – Metrics at this level cover things like databases, OS’s, networking, storage, CPU, etc.
Client software level – These metrics include data like errors, crashes, timings, etc.
Deployment pipeline level – This level includes metrics for data points like test suite status, deployment lead times, frequencies, etc.
Application and Business Metrics
Gather telemetry not just for technical bits, but also organizational goals, i.e. things like new users, login events, session lengths, active users, abandoned carts, etc.
Have every business metric be actionable. And if they’re not actionable, they’re “vanity metrics”.
By radiating these metrics, you enable fast feedback with feature teams to identify what’s working and what isn’t within their business unit.
Infrastructure Metrics
Need enough telemetry to identify what part of the infrastructure is having problems.
Graphing telemetry across infrastructure and application allows you to detect when things are going wrong.
Using business metrics along with infrastructure metrics allows development and operations teams to work quickly to resolve problems.
Need the same telemetry in pre-production environments so you can catch problems before they make it to production.
Overlaying other Relevant Information onto Our Metrics
In addition to our business and infrastructure telemetry graphing, you also want to graph your deployments so you can quickly correlate if a release caused a deviation from normal.
There may even be a “settling period” after a deployment where things spike (good or bad) and then return to normal. This is good information to have to see if deployments are acting as expected.
Same thing goes for maintenance. Graphing when maintenance occurs helps you correlate infrastructure and application issues at the time they’re deployed.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
The ONE Metric More Important Than Sales & Subscribers (YouTube)
2020 Developer Survey – Most Loved, Dreaded, and Wanted Languages (Stack Overflow)
Instrument your Python applications with Datadog and OpenTelemetry (Datadog)
Tsunami (GitHub) is a general purpose network security scanner with an extensible plugin system for detecting high severity vulnerabilities with high confidence.
It’s all about telemetry and feedback as we continue learning from The DevOps Handbook, while Joe knows his versions, Michael might have gone crazy if he didn’t find it, and Allen has more than enough muscles.
For those that use their podcast player to read these show notes, did you know that you can find them at https://www.codingblocks.net/episode138? Well, you can. And now you know, and knowing is half the battle.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
Survey Says
News
We give a heartfelt thank you in our best announcer voice to everyone that left us a new review!
Implementing the technical practices of the Second Way
Provides fast and continuous feedback from operations to development.
Allows us to find and fix problems earlier on the software development life cycle.
Create Telemetry to Enable Seeing and Solving Problems
Identifying what causes problems can be difficult to pinpoint: was it the code, was it networking, was it something else?
Use a disciplined approach to identifying the problems, don’t just reboot servers.
The only way to do this effectively is to always be generating telemetry.
Needs to be in our applications and deployment pipelines.
More metrics provide the confidence to change things.
Companies that track telemetry are 168 times faster at resolving incidents than companies that don’t, per the 2015 State of DevOps Report (Puppet).
The two things that contributed to this increased MTTR ability was operations using source control and proactive monitoring (i.e. telemetry).
Create Centralized Telemetry Infrastructure
Must create a comprehensive set of telemetry from application metrics to operational metrics so you can see how the system operates as a whole.
Data collection at the business logic, application, and environmental layers via events, logs and metrics.
Event router that stores events and metrics.
This enables visualization, trending, alerting, and anomaly detection.
Transforms logs into metrics, grouping by known elements.
Need to collect telemetry from our deployment pipelines, for metrics like:
How many unit tests failed?
How long it takes to build and execute tests?
Static code analysis.
Telemetry should be easily accessible via APIs.
The telemetry data should be usable without the application that produced the logs
Create Application Logging Telemetry that Helps Production
Dev and Ops need to be creating telemetry as part of their daily work for new and old services.
Should at least be familiar with the standard log levels
Debug – extremely verbose, logs just about everything that happens in an application, typically disabled in production unless diagnosing a problem.
Info – typically action based logging, either actions initiated by the system or user, such as saving an order.
Warn – something you log when it looks like there might be a problem, such as a slow database call.
Error – the actual error that occurs in a system.
Fatal – logs when something has to exit and why.
Using the appropriate log level is more important than you think
Low toner is not an Error. You wouldn’t want to be paged about low toner while sleeping!
Examples of some things that should be logged:
Authentication events,
System and data access,
System and app changes,
Data operations (CRUD),
Invalid input,
Resource utilization,
Health and availability,
Startups and shutdowns,
Faults and errors,
Circuit breaker trips,
Delays,
Backup success and failure
Use Telemetry to Guide Problem Solving
Lack of telemetry has some negative issues:
People use it to avoid being blamed for problems, which can be due to a political atmosphere and SUPER counter-productive.
Telemetry allows for scientific methods of problem solving to be used.
This approach leads to faster MTTR and a much better relationship between Dev and Ops.
Enable Creation of Production Metrics as Part of Daily Work
This needs to be easy, one-line implementations.
StatsD, often used with Graphite or Graphana, creates timers and counters with a single line of code.
Use data to generate graphs, and then overlay those graphs with production changes to see if anything changed significantly.
This gives you the confidence to make changes.
Create Self-Service Access to Telemetry and Information Radiators
Make the data available to anyone in the value stream without having to jump through hoops to get it, be they part of Development, Operations, Product Management, or Infosec, etc.
Information radiators are displays which are placed in highly visible locations so everyone can see the information quickly.
Nothing to hide from visitors OR from the team itself.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
Disable all of your VS Code extensions and then re-enable just the ones you need using CTRL+SHIFT+P. (code.visualstudio.com)
Color code your environments in Datagrip! Right click on the server and select Color Settings. Use green for local and red for everything else to easily differentiate between the two. Can be applied at the server and/or DB levels. For example, color your default local postgres database orange. This color coding will be applied to both the navigation tree and the open file editors (i.e. tabs).
Our journey into the world of DevOps continues with The DevOps Handbook as Michael doesn’t take enough tangents, Joe regrets automating the build, err, wait never regrets (sorry), and ducks really like Allen.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode137, where you can be a part of the conversation.
Sponsors
Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Secure Code Warrior – Start gamifying your organization’s security posture today, score 5,000 points, and get a free Secure Code Warrior t-shirt.
That System76 Oryx Pro keyboard though? (System76)
Fast, Reliable. Pick Two
Continuously Build, Test, and Integrate our Code and Environments
Build and test processes run constantly, independent of coding.
This ensures that we understand and codify all dependencies.
This ensures repeatable deployments and configuration management.
Once changes make it into source control, the packages and binaries are created only ONCE. Those same packages are used throughout the rest of the pipeline to ensure all environments are receiving the same bits.
What does this mean for our team culture?
You need to maintain reliable automated tests that truly validate deploy-ability.
You need to stop the “production pipeline” when validation fails, i.e. pull the andon cord.
You need to work in small, short lived batches that are based on trunk. No long-lived feature branches.
Short, fast feedback loops are necessary; builds on every commit.
Integrate Performance Testing into the Test Suite
Should likely build the performance testing environment at the beginning of the project so that it can be used throughout.
Logging results on each run is also important. If a set of changes shows a drastic difference from the previous run, then it should be investigated.
Enable and Practice Continuous Integration
Small batch and andon cord style development practices optimize for team productivity.
Long lived feature branches optimize for individual productivity. But:
They require painful integration periods, such as complex merges, which is “invisible work”.
They can complicate pipelines.
The integration complexity scales exponentially with the number of feature branches in play.
They can make adding new features, teams, and individuals to a team really difficult.
Trunk based development has some major benefits such as:
Merging more often means finding problems sooner.
It moves us closer to “single piece flow”, such as single envelope at a time story, like one big assembly line.
Automate and Enable Low-Risk Releases
Small batch changes are inherently less risky.
The time to fix is strongly correlated with the time to remediate, i.e. the mean time to find (MTF) and the mean time to remediate (MTR).
Automation needs to include operational changes, such as restarting services, that need to happen as well.
Enable “self-service” deployments. Teams and individuals need to be able to dynamically spin up reliable environments.
Decouple Deployments from Releases
Releases are marketing driven and refer to when features are made available to customers.
Feature flags can be used to toggle the release of functionality independent of their deployments.
Feature flags enable roll back, graceful degradation, graceful release, and resilience.
Architect for Low-Risk Releases
Don’t start over! You make a lot of the same mistakes, and new ones, and ultimately end up at the same place. Instead, fix forward!
Use the strangler pattern instead to push the good stuff in and push the bad stuff out, like how strangler vines grow to cover and subsume a fig tree.
Decouple your code and architecture.
Use good, strong versioned APIs, and dependency management to help get there.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We begin our journey into the repeatable world of DevOps by taking cues from The DevOps Handbook, while Allen loves all things propane, Joe debuts his “singing” career with his new music video, and Michael did a very bad, awful thing.
It’s a collection of arguments and high level guidance for understanding the spirit of DevOps.
It’s light on specifics and heavy on culture. The tools aren’t the problem here, the people need to change.
It’s also a book about scaling features, teams, people, and environments.
The First Way: The Principles of Flow
The Deployment Pipeline is the Foundation
Continuous delivery:
Reduces the risk associated with deploying and releasing changes.
Allows for an automated deployment pipeline.
Allows for automated tests.
Environments on Demand
Always use production like environments at every stage of the stream.
Environments must be created in an automated fashion.
Should have all scripts and configurations stored in source control.
Should require no intervention from operations.
The reality though …
Often times the first time an application is tested in a production like environment, is in production.
Many times test and development environments are not configured the same.
Ideally though …
Developers should be running their code in production like environments from the very beginning, on their own workstations.
This provides an early and constant feedback cycle.
Rather than creating wiki pages on how to set things up, the configurations and scripts necessary are committed to source control. This can include any of all of the following:
Copying virtualized environments.
Building automated environments on bare metal.
Using infrastructure as code, i.e. Puppet, Chef, Ansible, Salt, CFEngine, etc.
Using automated OS configuration tools.
Creating environments from virtual images or containers.
Creating new environments in public clouds.
All of this allows entire systems to be spun up quickly making this …
A win for operations as they don’t have to constantly battle configuration problems.
A win for developers because they can find and fix things very early in the development process that benefits all environments.
“When developers put all their application source files and configurations in version control, it becomes the single repository of truth that contains the precise intended state of the system.”
The DevOps Handbook
Check Everything into One Spot, that Everybody has Access to
Here are the types of things that should be stored in source control:
All application code and its dependencies (e.g. libraries, static content, etc.)
Scripts for creating databases, lookup data, etc.
Environment creation tools and artifacts (VMWare, AMI images, Puppet or Chef recipes).
Files used to create containers (Docker files, Rocket definition files, etc.)
All automated tests and manual scripts.
Scripts for code packaging, deployments, database migrations, and environment provisioning.
Additional artifacts such as documentation, deployment procedures, and release notes.
Cloud configuration files, such as AWS CloudFormation templates, Azure ARM templates, Terraform scripts, etc.)
All scripts or configurations for infrastructure supporting services for things like services buses, firewalls, etc.
Make Infrastructure Easier to Rebuild than to Repair
Treat servers like cattle instead of pets, meaning, rather than care for and fix them when they’re broken, instead delete and recreate them.
This has the side effect of keeping your architecture fluid.
Some have adopted immutable infrastructure where manual changes to environments are not allowed. Instead, changes are in source control which removes variance among environments.
The Definition of Done
“Done” means your changeset running in a production-like environment.
This ensures that developers are involved in getting code to production and bring operations closer to the code.
Enable Fast and Reliable Automated Testing
Automated tests let you move faster, with more confidence, and shortens feedback cycles for catching and fixing problems earlier.
Automated testing allowed the Google Web Server team to go from one of the least productive, to most productive group in the company.
Resources We Like
The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations (Amazon)
The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win (Amazon)
The Unicorn Project: A Novel about Developers, Digital Disruption, and Thriving in the Age of Data (Amazon)
We review the Stack Overflow Developer Survey in the same year it was created for the first time ever, while Joe has surprising news about the Hanson Brothers, Allen doesn’t have a thought process, and Michael’s callback is ruined.
If you’re reading these show notes via your podcast player, you can find this episode’s full show notes and join the conversation at https://www.codingblocks.net/episode135.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
As we learn from Google about how to navigate a code review, Michael learns to not give out compliments, Joe promises to sing if we get enough new reviews, and Allen introduces a new section to the show.
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Survey Says
News
Thank you, we appreciate the latest reviews:
Stitcher: Jean Guillaume Misteli, gitterskow
LGTM
Navigating a CL in Review
A couple starting questions when reviewing a CL (changelist):
Does the change make sense?
Does the CL have a good description?
Take a broad view of the CL
If the change doesn’t make sense, you need to immediately respond with WHY it shouldn’t be there.
Typically if you do this, you should probably also respond with what they should have done.
Be courteous.
Give a good reason why.
If you notice that you’re getting more than a single CL or two that doesn’t belong, you should consider putting together a quick guide to let people know what should be a part of CL’s in a particular area of code
This will save a lot of work and frustration.
Examine the main parts of the CL
Look at the file with the most changes first as that will typically aid in figuring out the rest of the CL quicker.
The smaller changes are usually part of that bigger change.
Ask the developer to point you in the right direction.
Ask to have the CL split into multiple smaller CL’s
If you see a major problem with the CL, you need to send that feedback immediately, maybe even before you look at the rest of the CL.
Might be that the rest of the CL isn’t even legit any longer if the major problem ends up being a show stopper.
Why’s it so important to review and send out feedback quickly?
Developers might be moving onto their next task that built off the CL in review. You want to reduce the amount of wasted effort.
Developers have deadlines they have to meet so if there’s a major change that needs to happen, they need to find out about it as soon as possible.
Look at the rest of the CL in an appropriate sequence
Looking at files in a meaningful order will help understanding the CL.
Reviewing the unit tests first will help with a general understanding of the CL.
Speed of Code Reviews
Velocity of the team is more important than the individual.
The individual slacking on the review gets other work done, but they slow things down for the team.
Looking at the other files in the CL in a meaningful order may help in speed and understanding of the CL.
If there are long delays in the process, it encourages rubber stamping.
One business day is the maximum to time to respond to a CL.
You don’t have to stop your flow immediately though. Wait for a natural break point, like after lunch or a meeting.
The primary focus on response time to the CL.
When is it okay to LGTM (looks good to me)?
The reviewer trusts the developer to address all of the issues raised.
The changes are minor.
How to write code review comments
Be kind.
Explain your reasoning.
Balance giving directions with pointing out problems.
Encourage simplifications or add comments instead of just complaining about complexity.
Courtesy is important.
Don’t be accusatory.
Don’t say “Why did you…”
Say “This could be simpler by…”
Explain why things are important.
It’s the developer’s responsibility to fix the code, not the reviewer’s. It’s sufficient to state the problem.
Code review comments should either be conveyed in code or code comments. Pull request comments aren’t easily searchable.
Handling pushback in code reviews
When the developer disagrees, consider if they’re right. They are probably closer to the code than you.
If you believe the CL improves things, then don’t give up.
Stay polite.
People tend to get more upset about the tone of comments, rather than the reviewers insistence on quality.
The longer you wait to clean-up, the less likely the clean-up is to happen. Better to block the request up front then move on.
Having a standard to point to clears up a lot of disputes.
Change takes time, people will adjust.
Resources We Like
Google Engineering Practices Documentation (GitHub)
We learn what to look for in a code review while reviewing Google’s engineering practices documentation as Michael relates patterns to choo-choos, Joe has a “weird voice”, and Allen has a new favorite portion of the show.
Are you reading this via your podcast player? You can find this episode’s full show notes at https://www.codingblocks.net/episode133 where you can also join the conversation.
This is the MOST IMPORTANT part of the review: the overall design of the changelist (CL).
Does the code make sense?
Does it belong in the codebase or in a library?
Does it meld well with the rest of the system?
Is it the right time to add it to the code base?
Functionality
Does the CL do what it’s supposed to do?
Even if it does what it’s supposed to do, is it a good change for the users, both developers and actual end-users?
As a reviewer, you should be thinking about all the edge-cases, concurrency issues, and generally just trying to see if any bugs arise just looking at the code.
As a reviewer, you can verify the CL if you’d like, or have the developer walk you through the changes (the actual implemented changes rather than just slogging through code).
Google specifically calls out parallel programming types of issues that are hard to reason about (even when debugging) especially when it comes to deadlocks and similar types of situations.
Complexity
This should be checked at every level of the change:
Single lines of code,
Functions, and
Classes
Too complex is code that is not easy to understand just looking at the code. Code like this will potentially introduce bugs as developers need to change it in the future.
A particular type of complexity is over-engineering, where developers have made the code more generic than it needs to be, or added functionality that isn’t presently needed by the system. Reviewers should be especially vigilant about over-engineering. Encourage developers to solve the problem they know needs to be solved now, not the problem that the developer speculates might need to be solved in the future. The future problem should be solved once it arrives and you can see its actual shape and requirements in the physical universe.
Google’s Engineering Practices documentation
Tests
Usually tests should be added in the same CL as the change, unless the CL is for an emergency.
If something isn’t in the style guide, and as the reviewer you want to comment on the CL to make a point about style, prefix your comment with “Nit”.
DO NOT BLOCK PR’s based on personal style preference!
Style changes should not be mixed in with “real” changes. Those should be a separate CL.
Consistency
Google indicates that if existing code conflicts with the style guide, the style guide wins.
If the style guide is a recommendation rather than a hard requirement, it’s a judgement call on whether to follow the guide or existing code.
If no style guide applies, the CL should remain consistent with existing code.
Use TODO statements for cleaning up existing code if outside the scope of the CL.
Documentation
If the CL changes any significant portion of builds, interactions, tests, etc., then appropriate README’s, reference docs, etc. should be updated.
If the CL deprecates portions of the documentation, that should also likely be removed.
Every Line
Look over every line of non-generated, human written code.
You need to at least understand what the code is doing.
If you’re having a hard time examining the code in a timely fashion, you may want to ask the developer to walk you through it.
If you can’t understand it, it’s very likely future developers won’t either, so getting clarification is good for everyone.
If you don’t feel qualified to be the only reviewer, make sure someone else reviews the CL who is qualified, especially when you’re dealing with sensitive subjects such as security, concurrency, accessibility, internationalization, etc.
Context
Sometimes you need to back up to get a bigger view of what’s changing, rather than just looking at the individual lines that changed.
Seeing the whole file versus the few lines that were changed might reveal that 5 lines were added to a 200 line method which likely needs to be revisited.
Is the CL improving the health of the system?
Is the CL complicating the system?
Is the CL making the system more tested or less tested?
“Don’t accept CLs that degrade the code health of the system.”
Most systems become complex through many small changes.
Good Things
If you see something good in a CL, let the author know.
Many times we focus on mistakes as reviewers, but some positive reinforcement may actually be more valuable.
We dig into Google’s engineering practices documentation as we learn how to code review while Michael, er, Fives is done with proper nouns, Allen can’t get his pull request approved, and Joe prefers to take the average of his code reviews.
In case you’re reading this via your podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode132. Be sure to check it out and join the conversation.
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Survey Says
News
Thank you to everyone that left us a review:
iTunes: Jbarger, Podcast Devourer, Duracce
Stitcher: Daemyon C
How to Code Review
Code Review Developer Guide
Q: What is a code review?
A: When someone other than the author of the code examines that code.
Q: But why code review?
A: To ensure high quality standards for code as well as helping ensure more maintainable code.
What should code reviewers look for?
Design: Is the code well-designed and appropriate for your system?
Functionality: Does the code behave as the author likely intended? Is the way the code behaves good for its users?
Complexity: Could the code be made simpler? Would another developer be able to easily understand and use this code when they come across it in the future?
Tests: Does the code have correct and well-designed automated tests?
Naming: Did the developer choose clear names for variables, classes, methods, etc.?
Comments: Are the comments clear and useful?
Style: Does the code follow our style guides?
Documentation: Did the developer also update relevant documentation?
Picking the Best Reviewers
Get the best reviewer you can, someone who can review your code within the appropriate time frame.
The best reviewer is the one who can give you the most thorough review.
This might or might not be people in the OWNERS file.
Different people might need to review different portions of your changes for the same pull request.
If the “best” person isn’t available, they should still be CC’d on the change list.
In Person Reviews
If you pair-programmed with someone who was the right person for a code review, then the code is considered reviewed.
You can also do code reviews where the reviewer asks questions and the coder only speaks when responding to the questions.
How to do a Code Review
The Standard of a Code Review
The purpose of the code review is to make sure code quality is improving over time.
There are trade-offs:
Developers need to actually be able to complete some tasks.
If reviewers are a pain to work with, for example they are overly critical, then folks will be less incentivized to make good improvements or ask for good reviews in the future.
It is still the duty of the reviewer to make sure the code is good quality. You don’t want the health of the product or code base to degrade over time.
The reviewer has ownership and responsibility over the code they’re reviewing.
Reviewers should favor approving the changes when the code health is improved even if the changes aren’t perfect. There’s no such thing as perfect code, just better code.
Reviewers can actually reject a set of changes even if it’s quality code if they feel it doesn’t belong in “their” system.
Reviewers should not seek perfection but they should seek constant improvement.
This doesn’t mean that reviewers must stay silent. They can point out things in a comment using a prefix such as “Nit”, indicating something that could be better but doesn’t block the overall change request.
Code that worsens the overall quality or health of a system should not be admitted unless it’s under extreme/emergency circumstances.
What constitutes an emergency?
A small change that:
Allows a major launch to continue,
Fixes a significant production bug impacting users,
Addresses a legal issue, or
Patches a security hole.
What does not constitute an emergency?
You want the change in sooner rather than later.
You’ve worked hard on the feature for a long time.
The reviewers are away or in another timezone.
Because it’s Friday and you want the code merged in before the weekend.
A manager says that it has to be merged in today because of a soft deadline.
Rolling back causes test failures or breaks the build.
Mentoring
Code reviews can absolutely be used as a tool for mentoring, for example teaching design patterns, explaining algorithms, etc., but if it’s not something that needs to be changed for the PR to be completed, note it as a “Nit” or “Note”.
Principles
Technical facts and data overrule opinions and/or preferences.
The style guide is the authority. If it’s not in the style guide, it should be based on previous coding style already in the code, otherwise it’s personal preference.
The reviewer may request the code follow existing patterns in the code base if there isn’t a style guide.
Resolving Conflicts
If there are conflicts between the coder and reviewer, they should first attempt to come to a consensus based on the information discussed here as well as what’s in the CL Author’s Guide or the Reviewer Guide.
If the conflict remains, it’s probably worth having a face to face to discuss the issues and then make sure notes are taken to put on the code review for future reference and readers.
If the conflict still remains, then it’s time to escalate to a team discussion, potentially having a team leader weigh in on the decision.
NEVER let a change sit around just because the reviewer and coder can’t come to an agreement.
Resources We Like
Google Engineering Practices Documentation (GitHub)
We gather around the water cooler at 6 foot distances as Michael and Joe aren’t sure what they streamed, we finally learn who has the best fries, at least in the US, and Allen doesn’t understand evenly distributing your condiments.
For those reading this via their podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode131. Stop by and join in on the conversation.
Uber’s Big Data Platform: 100+ Petabytes with Minute Latency (eng.uber.com)
Tip of the Week
Interested in COBOL, game development, and Dvorak keyboards? Check out Joe’s new favorite streamer Zorchenhimer. (Twitch)
Using helm uninstall doesn’t remove persistent volumes nor their claims.
After doing helm uninstall RELEASE_NAME, delete the persistent volume claim using kubectl delete pvc PVC_NAME to remove the claim, which depending on the storage class and reclaim policy, will also remove the persistent volume. Otherwise, you’d need to manually remove the persistent volume using kubectl delete pv PV-NAME.
kafkacat – A generic non-JVM producer and consumer for Apache Kafka. (GitHub)
We dig into the details of how databases use B-trees as we continue our discussion of Designing Data-Intensive Applications while Michael’s description of median is awful, live streaming isn’t for Allen, and Joe really wants to bring us back from the break.
For those reading this via their podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode130 in all their glory. Check it out, as Joe would say, and join the conversation.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after install the agent.
Survey Says
News
We really appreciate the latest reviews, so thank you!
Be on the lookout for live streams of Joe on YouTube or Twitch!
B-Trees are Awesome
B-trees are the most commonly used indexing structure.
Introduced in 1970, and called ubiquitous 10 years later.
They are the implementation used by most relational database systems, as well as a number of non-relational DB’s.
“Indexing” is the way databases store metadata about your data to make quick look ups.
Like the SSTable, the B-tree stores key/value pairs sorted by key. This makes range query look ups quick.
B-trees use fixed block sizes, referred to as pages, that are usually 4 KB in size which (generally) map well to the underlying hardware because disks are typically arranged in fixed block sizes.
Every page has an address that can be referenced from other pages. These are pointers to positions on a disk.
Knowing (or being able to quickly find) which page the data you are looking for is in, drastically cuts down on the amount of data you have to scan through.
B-trees start with a root page. All key searches start here.
This root will contain references to child pages based off of key ranges.
The child pages might contain more references to other child pages based off of more narrowly focused key ranges.
This continues until you reach the page that has the data for the key you searched for.
These pages are called leaf pages, where the values live along with the key.
The branching factor is the number of references to child pages in one page of a B-tree.
The branching factor is tied to the space needed to store the page references and the range boundaries.
The book states that it’s common to have a branching factor of several hundred, some even say low thousands!
The higher the branching factor means the fewer levels you have to go through, i.e. less pages you have to scan, when looking for your data.
Updating a value in a B-tree can be complicated.
You search for the leaf node containing the key and then update the value and write it to disk.
Assuming everything fits in the page, then none of the upstream references change and everything is still valid.
If you are inserting a new key, you find the leaf node where the key should live based on the ranges and then you add the key and value there.
Again, if everything fits in the page, then similar to the update, none of the upstream references need to change.
However, if the key/value would exceed the size of the page, the page is split into two half-pages, and the parent page’s references are updated to point to the new pages.
This update to the parent page might require it to also be split.
And this update/split pattern might continue up to and including the root page.
By splitting the pages into halves as data is added that exceeds the page size, this keeps the tree balanced.
A balanced tree is the secret to consistent lookup times.
It terms of big-O, a B-tree with n keys has a depth of O(log n).
Most DB’s only go 3 to 4 levels deep.
A tree with four levels, using a 4 KB page size, and a branching factor of 500 can store up to 256 TB!
Making B-Trees Reliable
The main notion is that writes in a B-tree occur in the same location as the original page, that way no references have to change, assuming the page size isn’t exceeded.
Think of this as a hardware operation.
These actually map to spinning drives better than SSD’s. SSD’s must rewrite large blocks of a storage chip at a time.
Because some operations require multiple pages to be written, in the case of splitting full pages and updating the parent, it can be dangerous because if there is a DB crash at any point during the writing of the pages, you can end up with orphaned pages.
To combat this, implementations usually include a write-ahead log (WAL, aka a redo log).
This is an append-only file where all modifications go before the tree is updated.
If the database crashes, this file is read first and used to put the DB back in a good, consistent state.
Another issue is that of concurrency.
Multiple threads reading and writing to the B-tree at the same time could read things that would be in an inconsistent state.
In order to counter this problem, latches, or lightweight locks, are typically used.
B-Tree Optimizations
Some databases use a copy-on-write scheme. This alleviates the need to write to an append only log like previously mentioned and instead you write each updated page to a new location including updated parents that point to it.
In some cases, abbreviated keys can be stored which saves space and would allow for more branching but fewer node levels, which is fewer hops to get to the leaf nodes.
This is technically a B+ tree.
Some implementations attempt to keep leaf pages next to each other in sequential order which would improve the seek speed to the data.
Some implementations keep additional pointers, such as references to the previous and next sibling pages so it’s quicker to scan without having to go back to the parent to find the pointer to those same nodes.
Variants like fractal trees, use tactics from log-structured ideas to reduce disk seeks.
Comparing B-Trees and LSM-Trees
B-trees are much more common and mature. We’ve ironed out the kinks and we understand the ways people use RDBMSes.
LSM-trees are typically faster for writes.
B-trees are typically faster for reads because LSM-trees have to check multiple data-structures, including SSTables that might be at different levels of compaction.
Use cases vary, so benchmarking your use cases are important.
LSM-Tree Advantages
The write amplification problem:
B-trees must write all data at least twice, once to the WAL and another to the page (and again if pages are split). Some storage engines go even further for redundancy.
LSM-trees also rewrite data, due to compaction and tree/SSTable merging.
This is particularly a problem for SSDs, which don’t do so well with repeated writes to the same segment.
LSM-trees typically have better sustained write throughput because they have lower write amplification and because of they generally sequentially write the SSTable files, which is particularly important on HDDs.
LSM-trees can be compressed better, and involve less space on disk.
LSM-trees also have lower fragmentation on writes.
LSM-Tree Downsides
Compaction of the SSTables can affect performance, even though the compaction can happen in another thread, because takes up disk I/O resources, i.e. the disk has a finite amount of I/O bandwidth.
It’s possible that the compaction can not be keep up with incoming events, causing you to run out of disk space, which also slows down reads as more SSTable files need to be read.
This problem is magnified in a LSM-tree because a key can exist multiple times (before compaction) unlike B-trees which have just one location for a given key.
The B-tree method for updating also makes it easier for B-trees to guarantee transactional isolation.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Chocolatey adds a PowerShell command Update-SessionEnvironment or refreshenv for short, that you can use to update the environment variables in your current PowerShell session, much like . $HOME/.profile for MacOS/Linux. (Chocolatey)
Use docker stats to monitor the usage of your running Docker containers. It’s like top for Docker. (Docker)
Click the Equivalent REST or command line link at the bottom of the Google Cloud Console to get the equivalent as a command you can script and iterate on.
Apache Drill is an amazing schema-free SQL query engine for Hadoop, NoSQL, and Cloud Storage. (drill.apache.org)
Get up and running in minutes with Drill + Docker (drill.apache.org)
Presto, aka Presto DB, not to be confused with Presto SQL, is distributed SQL query engine for big data originally developed by Facebook. (prestodb.io)
Since we can’t leave the house, we discuss what it takes to effectively work remote while Allen’s frail body requires an ergonomic keyboard, Joe finally takes a passionate stance, and Michael tells them why they’re wrong.
Reading these show notes via your podcast player? You can find this episode’s full show notes at https://www.codingblocks.net/episode129 and be a part of the conversation.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after install the agent.
Don’t be afraid to spend time on calls just chatting about non work related stuff.
Working from home means there’s little opportunity to connect personally and that is sorely needed when working from home. Taking time to chat will help to keep the team connected.
Keep it light and have fun!
Be available and over communicate.
During business hours make sure you’re available. That doesn’t mean you need to be in front of your computer constantly, but it does mean to make sure you can be reached via phone, email, or chat and can participate when needed.
Working from home also means it is super important to communicate status and make sure people feel like progress is being made.
Also, if you need to be offline for any reason, send up a flare, don’t just disappear.
Make sure your chat application status is really your status. People will rely on you showing “Active” meaning that you are available. Don’t game your status. Take a break if you need to but if you aren’t available, don’t show available. Also, if you don’t show “Active” many will assume that you aren’t available or online.
We’ve also found that sometimes it is good to show “offline” or “unavailable” to give us a chance to get into a flow and get things done, so don’t be afraid to do that. Having this be a “known agreement” will signal to others that they may just want to send you an e-mail or schedule a conference later.
If something is urgent in email, make sure to send the subject with a prefix of “URGENT:”
But beware the an “urgent” email doesn’t mean you’ll get an instant reply. If you need an answer right now, consider a phone call.
An “urgent” email should be treated as “as soon as you read this”, knowing that it might not be read for a while.
Make sure your calendar is up to date. If you are busy or out of the office (OOO) then make sure you schedule that in your calendar so that people will know when they can meet with you.
Along with the above, when scheduling meetings, check the availability of your attendees.
Be flexible.
This goes with things mentioned above. As a manager especially, you need to be flexible and recognize that working from home sometimes means people need to be away for periods of time for personal reasons. Don’t sweat that unless these people aren’t delivering per the next point.
Favor shorter milestones or deliverables and an iterative approach.
This helps keep people focused and results oriented. Science projects are easy to squash if you define short milestones that provide quick wins on the way to a longer term goal.
We use the term “fail fast” a lot where we break projects into smaller bits and try to attack what’s scariest first in an effort to “fail fast” and change course.
We use JIRA and work in 2 week sprints.
Define work in small enough increments. If something exceeds two weeks, it means it needs to be reviewed and refined into smaller work streams. Spend the time to think through it.
Require estimates on work items to help keep thing on track.
Allow and encourage people to work in groups or teams if appropriate, for things like:
Brainstorming sessions.
Mini-scrums that are feature or project based.
Pair programming. Use of the proper video application for screen sharing is important here.
Conference etiquette:
Mute. If you’re not talking, mute.
Lots of participants? Mute.
Smaller/Team meeting? Up to you. But probably best to mute.
Use a microphone and verify people hear you okay. Don’t forgo a real headset or microphone and instead try to use your internal laptop microphone and speakers. You will either be super loud with background noise, for example people just hear you typing the whole time or hear your fan running, or people won’t hear you at all.
When you start presenting, it is a good practice to ask “can you see my screen?”
Give others opportunities to talk and if someone hasn’t said anything, mention it and ask for their feedback especially if you think their opinion is important on the subject at hand.
Use a tool to help you focus.
It is easy to get distracted by any number of things.
A technique that works well for some is the Pomodoro Technique. There’s also nifty applications and timers that you can use to reinforce it.
Music may not be the answer.
For some people just putting on noise-cancelling headphones helps with external noise (kids, TV, etc.)
Choose the right desktop sharing tool when needed.
We’ve found that Hangouts is a great tool to meet quickly and while it does provide for screen sharing, the video quality isn’t great. It does not allow people who are viewing your screen to zoom in and if you have a very high resolution monitor, people may find it hard to read/see it.
While Webex is a little more challenging to use, it does provide the ability for others to zoom in when you share, and the shared screens are more clear than Hangouts.
Additionally, Webex allows you to view all participants in one gallery view, thus reinforcing team cohesion.
That said though, we’ve found Zoom to be far superior to it’s competitors.
Develop a routine.
Get up and start working at roughly the same time if you can.
Shower and dress as if you’re going out for errands at least.
If possible, have a dedicated workspace.
Most importantly, make sure you stop work at some point and just be home. If at all possible, coupled with the dedicated workspace tip, if you can have a physical barrier, such as a door, use it, i.e close the door and “be home” and not “at work”.
It’s hard not to overeat at first, but try to avoid the pantry that is probably really close to your workspace.
Try to get out of the house for exercise or errands in the middle of day to break things up.
Working from home is much more sedentary than working in an office. Make it a point to get up from your desk and walk around, check the mail, do whatever you can to stretch your legs.
It’s time to learn about SSTables and LSM-Trees as Joe feels pretty zacked, Michael clarifies what he was looking forward to, and Allen has opinions about Dr Who.
These show notes can be found at https://www.codingblocks.net/episode128 where you be a part of the conversation, in case you’re reading this via your podcast player.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after install the agent.
ABOUT YOU processes > 200,000 API calls per minute. You like things that scale? Give their corporate page a visit! They are looking for new team members! Apply now at aboutyou.com/job.
Sadly, due to COVID-19 (aka Coronavirus), the 15th Annual Orlando Code Camp & Tech Conference has been cancelled. We’ll keep you informed of your next opportunity to kick us in the shins. (orlandocodecamp.com)
During this unprecedented time, TechSmith is offering Snagit and Video Review for free through June 2020. (TechSmith)
SSTables and LSM-Trees
SSTables
SSTable is short for “Sorted String Table”.
SSTable requires that the writes be sorted by key.
This means we cannot append the new key/value pairs to the segment immediately because we need to make sure the data is sorted by key first.
What are the benefits of the SSTable over the hash indexed log segments?
Merging the segments is much faster, and simpler. It’s basically a mergesort against the segment files being merged. Look at the first key in each file, and take the lowest key (according to the sort order), add it to the new segment file … rinse-n-repeat.
When the same key shows in multiple segment files, keep the newer segment’s key/value pair, sticking with the notion that the last written key/value for any given key is the most up to date value.
To find keys, you no longer need to keep the entire hash of indexes in memory. Instead, you can use a sparse index where you store a key in memory for every few kilobytes from a segment file
This saves on memory.
This also allows for quick scans as well.
For example, when you search for a key, Michael and the key isn’t in the index, you can find two keys in the sparse index that Michael falls between, such as Micah and Mick, then start at the Micah offset and scan that portion of the segment until you find the Michael key.
Another improvement for speeding up read scans is to write chunks of data to disk in compressed blocks. Then, the keys in the sparse index point to the beginning of that compressed block.
So how do you write this to disk in the proper order?
If you just write them to disk as you get them, they’ll be out of order in an append only manner because you’re likely going to receive them out of order.
One method is to actually write them to disk in a sorted structure. B-Tree is one option. However, maintaining a sorted structure in memory is actually easier than trying to maintain it on disk though, due to well known tree data structures like red-black trees and AVL trees.
The keys are sorted as they’re inserted due to the way nodes are shuffled during inserts.
This allows you to write the data to memory in any order and retrieve it sorted.
When data arrives, write it to the memory balanced tree data structure, such as a red-black tree. This is also referred to as a memtable.
Once you’ve reached a predefined size threshold, you dump the data from memory to disk in a new SSTable file.
While the new segment is being written to disk, any incoming key/value pairs get written to a new memtable.
When serving up read requests, you search in your memtable first, then back to the most recent segment, and so on moving backwards until you find the key you’re looking for.
Occasionally run a merge on the segments to get rid of overwritten or deleted items.
Downside of this method?
If the database crashes for some reason, the data in the memtable is lost.
To avoid this, you can use an append-only, unsorted log for each new record that comes in. If the database crashes, that log file can be used to recreate the memtable.
Databases intended to be embedded in other applications,
RocksDB is embedded in Kafka Streams and is used for GlobalKTables.
Similar storage engines are used by Cassandra and HBase.
Both took some design queues from Google’s BigTable whitepaper, which introduced the terms SSTable and memtable.
All of this was initially described under the name Log-Structured Merge Tree, LSM-Tree.
Storage engines that are based on the notion of storing compacted and sorted files are often called LSM storage engines.
Lucene, the indexing engine used in Solr and ElasticSearch, uses a very similar process.
Optimizing
One of the problems with the LSM-Tree model is that searching for keys that don’t exist can be expensive.
Must search the memtable first, then latest segment, then the next oldest segment, etc., all the way back through all the segments.
One solution for this particular problem is a Bloom filter.
A Bloom filter is a data structure used for approximating what is in a set of data. It can tell you if the key does not exist, saving a lot of I/O looking for the key.
There are competing strategies for determining when and how to perform the merge and compaction operations. The most common approaches include:
Leveled compaction – Key ranges are split into smaller SSTables and old data is moved to different “levels” allowing the compacting process to use less disk and done incrementally. This is the strategy used by LevelDB and RocksDB.
Size-tiered compaction – Smaller and newer SSTables are merged into larger and older SSTables. This is the strategy used by HBase.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Red-black trees in 5 minutes – Insertions (examples) (YouTube)
A Busy Developer’s Guide to Database Storage Engines – The Basics (yugabyteDB)
Tip of the Week
Save time typing paths by drag-n-dropping a folder from Finder/File Explorer to your command shell. Works on Windows and macOS in Command Prompt, Powershell, Cmder, and Terminal.
Popular and seminal white papers curated by Papers We Love (GitHub)
See if there is an upcoming PWL meetup in your area (paperswelove.org)
And there’s a corresponding Papers We Love Conference (pwlconf.org)
Every find yourself in the situation where you’re asked to pivot from your current work to another task that would require you to stash your current changes and change branches? Maybe you do that. Or maybe you clone the repo into another path and work from there? But there’s a pro-tip way. Instead, you can use git worktree to work with your repo in another path without needing to re-clone the repo.
For example, git worktree add -b myhotfix /temp master copies the files from master to /temp and creates a new branch named myhotfix.
Get your Silicon Valley fix with Mythic Quest. (Apple)
Level up your programming skills with exercises and mentors with Exercism. (exercism.io)
Exercism has been worth mentioning a few times:
Algorithms, Puzzles, and the Technical Interview (episode 26)
In this episode, Allen is back, Joe knows his maff, and Michael brings the jokes, all that and more as we discuss the internals of how databases store and retrieve the data we save as we continue our deep dive into Designing Data-Intensive Applications.
If you’re reading these show notes via your podcast player, did you know that you can find them at https://www.codingblocks.net/episode127? Well you do now! Check it out and join in the conversation.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Educative.io – Level up your coding skills, quickly and efficiently. Visit educative.io/codingblocks to get 10% off any course or annual subscription.
Clubhouse – The fast and enjoyable project management platform that breaks down silos and brings teams together to ship value, not features. Sign up to get two additional free months of Clubhouse on any paid plan by visiting clubhouse.io/codingblocks.
Survey Says
News
We thank all of the awesome people that left us reviews:
iTunes: TheLunceforce, BrianMorrisonMe, Collectorofmuchstuff, Momentum Mori, brianbrifri, Isyldar, James Speaker
Stitcher: adigolee
Come see Allen, Joe, and Michael in person at the 15th Annual Orlando Code Camp & Tech Conference, March 28th. Sign up for your chance to kick them all in the shins and grab some swag. (orlandocodecamp.com)
Database Storage and Retrieval
A database is a collection of data.
A database management system includes the database, APIs for managing the data and access to it.
RDBMS Storage Data Structures
Generally speaking, data is written to a log in an append only fashion, which is very efficient.
Log: an append-only sequence of records; this doesn’t have to be human readable.
These write operations are typically pretty fast because writing to the end of a file is generally a very fast operation.
Reading for a key from a file is much more expensive though as the entire file has to be scanned for instances of the key.
To solve this problem, there are indexes.
Generally speaking, an index is just different ways to store another structure derived from the primary set of data.
Having indices incurs additional overhead on writes. You’re no longer just writing to the primary data file, but you’re also keeping the indices up to date at the same time.
This is a trade-off you incur in databases: indexes speed up reads but slow down writes.
Hash Indexes
One possible solution is to keep every key’s offset (which points to the location of the value of the key) in memory.
This is what is done for Bitcask, the default storage engine for Riak.
The system must have enough RAM for the index though.
In the example given, all the keys stay in memory, but the file is still always appended to, meaning that the key’s offset is likely to change frequently, but it’s still very efficient as you’re only ever storing a pointer to the location of the value.
If you’re always writing to a file, aren’t you going to run out of disk space?
File segmenting / compaction solves this.
Duplicate keys in a given file are compacted to store just the last value written for the key, and those values are written to a new file.
This typically happens on a background thread.
Once the new segment file has been created, after merging in changes from the previous file, then it becomes the new “live” log file.
This means while the background thread is running to create the new segment, the locations for keys are being read from the old segment files in the meantime so that processes aren’t blocked.
After the new segment file creation is completed, the old segment files can be deleted.
This is how Kafka topic retention policies work, and what happens when you run “force merge” on an Elasticsearch index (same goes for similar systems).
Some key factors in making this work well:
File format
CSV is not a great format for logs. Typically you want to use a binary format that encodes the length of the string in bytes with the actual string appended afterwards.
Deleting records requires some special attention
You have to add a tombstone record to the file. During the merge process, the key and values will be deleted.
Crash recovery
If things go south on the server, recovering might take some time if there are large segments or key/value pairs.
Bitcask makes this faster by snapshotting the in-memory hashes on occasion so that starting back up can be faster.
Incomplete record writes
Bitcask files include checksums so any corruption in the logs can be ignored.
Concurrency control
It’s common for there to only be one writer thread, but multiple reader threads, since written data is immutable.
Why not update the file, instead of only appending to it?
Appending and merging are sequential operations, which are particularly efficient on HDD and somewhat on SSD.
Concurrency and crash recovery are much simpler.
Merging old segments is a convenient and unintrusive way to avoid fragmentation.
Downsides to Hash Indexes
The hash table must fit in memory or else you have to spill over to disk which is inefficient for hash table.
Range queries are not efficient, you have to lookup each key.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Grokking the System Design Interview (Educative.io)
Tip of the Week
Add authentication to your applications with minimum fuss using KeyCloak. (keycloak.org)
Master any major city’s transit system like a boss with CityMapper. (citymapper.com)
Spin up a new VM with a single command using Multipass. (GitHub)
Jamie from https://dotnetcore.show/ and Allen, ya know, from Coding Blocks, sat down together at NDC London to talk about the hot topics from the conference as well as how to get the most out of any conference you attend.
If you're reading this episodes show notes via your podcast player, you can find this episode's full show notes at https://www.codingblocks.net/episode126 where you can join in on the conversation.
Sponsors
Datadog - Sign up today at codingblocks.net/datadog for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard. Read Datadog's new State of Serverless research report that breaks down the state of Serverless, with a detailed look at AWS Lambda usage.
Educative.io - Level up your coding skills, quickly and efficiently. Visit educative.io/codingblocks to get 10% off any course or annual subscription.
Clubhouse - The fast and enjoyable project management platform that breaks down silos and brings teams together to ship value, not features. Sign up to get two additional free months of Clubhouse on any paid plan by visiting clubhouse.io/codingblocks.
How to get the most out of a Conference
If the conference has an app - I highly recommend downloading it - typically latest breaking changes to venue, rooms, talks, etc. will be in the app
Attend talks that are outside your immediate realm of knowledge - get exposed to new things, new ideas, new ways of thinking
Walk away with fewer "unknown unknowns" and gain some more "known unknowns"
Provides you with things to search when you get back from the conference
Picking the talks you want to attend
Sometimes you have to sacrifice bigger names just to attend talks that may pique your interest
Know that what you're seeing on stage for an hour was probably weeks worth of effort to make it go off without a hitch - so when you try to replicate these things at home, don't lose hope when your try isn't as smooth as what you saw on stage
This next bit goes for Meetups, Conferences, etc - Get involved in conversations - don't just sit on the sideline - many developers are introverts, but to truly get the most out of a conference you want to have some meaningful discussions
Pacman effect - leave a gap when you're standing in a group having a conversation
Take advantage of eating times - find a table with an open spot and don't pick up your phone!!! Say good morning or good afternoon! "What's been your favorite talk today?"
When it's "drinking time", talk to people. If you're not a drinker, grab a water or a soda and join in on the conversation
Try and reach out BEFORE the conference online - Twitter, Facebook, Slack, etc - try and find out who all is going to be attending and try to make a point to meet up at the event! Makes things much less awkward when you've planned a meeting rather than just shouldering your way in.
Be a wingman/wingwoman or bring one along - help introduce people to your ring of contacts'
Maybe sign up to be a speaker at one of these things! If you watch the other folks giving presentations, you'll see they're regular people just sharing the things they're passionate about
The big names in the industry became big names because they took that first step - you don't become a big name overnight
Machine Learning - we as developers need to take much more care in what we release to the world
A number of talks / discussion panels revolved around this topic
Even with good intentions, you can make something that has consequences that aren't easy to see
Knowing your data intimately is the key to everything - but, you need to have different perspectives on the data - it'd be really easy to get laser focused on what you think makes for a good set of data for a model, and miss the pieces that actually provide the best model
We dive into declarative vs imperative query languages as we continue to dive into Designing Data-Intensive Applications while Allen is gallivanting around London, Michael had a bullish opinion, and Joe might not know about The Witcher.
If you’re reading this episodes show notes via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode125 where you can join in on the conversation.
Sponsors
Datadog – Sign up today at codingblocks.net/datadog for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard. Read Datadog’s new State of Serverless research report that breaks down the state of Serverless, with a detailed look at AWS Lambda usage.
Educative.io – Level up your coding skills, quickly and efficiently. Visit educative.io/codingblocks to get 10% off any course or annual subscription.
Clubhouse – The fast and enjoyable project management platform that breaks down silos and brings teams together to ship value, not features. Sign up to get two additional free months of Clubhouse on any paid plan by visiting clubhouse.io/codingblocks.
Survey Says
News
We thank everyone that left us some great reviews:
Get your shin kicking shoes on and sign up for the South Florida Software Developers Conference 2020, February 29th, where Joe will be giving his talk, Streaming Architectures by Example. (fladotnet.com)
Come meet us at the 15th annual Orlando Code Camp & Tech Conference, March 28th. Grab some swag and kick us in the shins. (orlandocodecamp.com)
Query Languages
Declarative vs Imperative
The relational model introduced a declarative query language: SQL.
Prior models used imperative code.
An imperative language performs certain operations in a certain order, i.e. do this, then do that.
With a declarative query language, you specify the pattern of data you want, the conditions that must be met, any sorting, grouping, etc.
Note that you don’t specify how to retrieve the data. That is left to the optimizer to figure out.
Declarative languages are attractive because they are shorter and easier to work with.
Consider UI frameworks where you declaratively describe the UI without needing to write code that actually draws a button of a specific size in a specific place with a specific label, etc.
Additionally, declarative languages hide the implementation details.
This means it’s easier to continue using the code as the underlying engine is updated, be it a database, UI framework, etc.
This also means that the declarative code can take advantage of performance enhancements with little to no change (often) to the declarative code.
Because declarative languages only specify the result, instead of how to get the result, they are often more likely to be able to take advantage of parallel execution.
Conversely, because imperative code needs to happen in a specific order, it’s more difficult to parallelize.
MapReduce
Made popular by Google, MapReduce is a programming model meant for processing large amounts of data in bulk in a horizontally distributed fashion.
Some NoSQL databases, such as MongoDB and CouchDB, support MapReduce in a limited form as a way to perform read-only queries across many documents.
MapReduce isn’t a declarative query language but it’s also not completely an imperative query API either.
This is because to use it, you’re implementing the Template Pattern (episode 16).
With MapReduce, you implement two methods: map() and reduce().
The map() and reduce() functions are pure functions.
They can only use the data passed into them, they can’t perform additional queries, and they must not have side effects.
Pure functions are a concept used in functional programming.
From a usability perspective though, it does require writing two functions that are somewhat tied to each other, which may be more effort than just writing a single SQL query.
Plus a purely declarative SQL query is better able to take advantage of the optimizer.
For this reason, MongoDB added a declarative query language called the aggregation pipeline to wrap the MapReduce functionality.
It’s expessiveness is similar to a subset of SQL but in a JSON syntax.
Graph-Like Data Models
Relationships, particularly many-to-many, are an important feature for distinguishing between when to use which data model.
As relationships get even more complicated, graph models start to feel more natural.
Where as document databases have documents, and relational databases have tables, rows, and columns, graph databases have:
Vertices: Nodes in the graph
Edges: Define the relationships between nodes, and can contain data about those relationships.
Examples of graph-like data:
Social graphs: Vertices are the entities (people, media, articles), and edges are the relationships (friends with, likes, etc.)
Web graph: Vertices are the pages, and edges are the links.
Maps: Addresses are the vertices, and roads, rails, sidewalks are the edges.
There are some things that are trivial to express in a graph query that are really hard any other way.
For example, fetch the top 10 people that are friends with my friends, but not friends with me, and liked pages that I like sorted by the count of our common interests.
These queries work just like graph algorithms, you define how the graph is traversed.
Graph databases tend to be highly flexible since you can keep adding new vertices and nodes without changing any other relationships.
This makes graphs great for evolvability.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Grokking the System Design Interview (Educative.io)
Use the Microsoft Application Inspector to identify and surface well-known features and other interesting characteristics of a component’s source code to determine what it is and/or what it does. (GitHub)
Automatically silence those pesky, or worse: embarrassing, notifications while screensharing on your Mac. (Muzzle)
While we continue to dig into Designing Data-Intensive Applications, we take a step back to discuss data models and relationships as Michael covers all of his bases, Allen has a survey answer just for him, and Joe really didn’t get his tip from Reddit.
This episode’s full show notes can be found at https://www.codingblocks.net/episode124, in case you’re reading this via your podcast player, where you can be a part of the conversation.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Educative.io – Level up your coding skills, quickly and efficiently. Visit educative.io/codingblocks to get 10% off any course or annual subscription.
Clubhouse – The fast and enjoyable project management platform that breaks down silos and brings teams together to ship value, not features. Sign up to get two additional free months of Clubhouse on any paid plan by visiting clubhouse.io/codingblocks.
Survey Says
News
Thank you for the awesome reviews:
iTunes: Kampfirez, Ameise776, JozacAlanOutlaw, skmetzger, Napalm684, Dingus the First
Get your tickets now for NDC { London }, January 27th – 31st, where you can kick Allen in the shins where he will be giving his talk, Big Data Analytics in Near-Real-Time with Apache Kafka Streams. (ndc-london.com)
Hurry and sign up for the South Florida Software Developers Conference 2020, February 29th, where Joe will be giving his talk, Streaming Architectures by Example. This is a great opportunity for you to try to kick him in the shins. (fladotnet.com)
The CB guys will be at the 15th Annual Orlando Code Camp & Tech Conference, March 28th. Sign up for your chance to kick them all in the shins and grab some swag. (orlandocodecamp.com)
Relationships … It’s complicated
Normalization
Relational databases are typically normalized.
A quick description of normalization would be associating meaningful data with a key and then relating data by keys rather than storing all of the data together.
Normalization reduces redundancy and improve data integrity.
Relational normalization has several benefits:
Consistent styling and spelling for meaningful values.
No ambiguity, even when text values are coincidentally the same, for example, Georgia the state vs Georgia the country.
Updating meaningful values is easy since there is only one spot to change.
Language localization support can be easier because you can associate different meaningful values with the same key for each supported language.
Search for hierarchical relationships can be easier, for example, getting a list of cities for a particular state.
This can vary based on how the data is stored. See episode 28 and episode 29 for more detailed discussions related to some strategies.
There are legitimate reasons for having denormalized data in a relational database, like faster searches, although there might be better tools for the specific use case.
Relationships …
In Document Databases
Document databases struggle as relationships get more complicated.
Document database designers have to make careful decisions about where data will be stored.
A big benefit of document databases is locality, meaning all of the relevant data for an entity is stored in one spot.
Fetching an order object is one simple get in a document database, while the relational database might end up being more than one query and will surely join multiple tables.
In Relational Databases
There are several benefits of relational database relationships, particularly Many-to-One and Many-to-Many relationships
To illustrate a Many-to-One example, there are many parts associated to one particular computer.
To illustrate a Many-to-Many example, a person can be associated to many computers and a computer can be associated to many people.
As your product matures, your database (typically) gets more complicated. The relational model holds up really well to these changes over time. The queries get more complicated as you add more relationships, but your flexibility remains.
Query Optimization
A query optimizer, a common part of popular RDBMSes, is responsible for deciding which parts of your written query to execute in which order and which indexes to use.
The query optimizer has a huge impact on performance and is a big part of the reason why proprietary RDBMSes like Oracle and SQL Server are so popular.
Imagine if you, the developer, had to be smarter about the order that you joined your tables and the order of items in your WHERE clause …
and then ratios of data in the tables were different in production vs development,
and then a new index was added, …
The query optimizer uses advanced statistics about your data to make smart choices about how to execute your query.
A key insight into the relational model is that the query optimizer only has to be built once and everybody benefits from it.
In document databases, the developers and data model designers have to consider their designs and querying constantly.
How to choose Document vs Relational
Document Databases …
Better performance in some use cases because of locality.
Often scale very well because of the locality.
Are flexible in what they can store, often called “schemaless” or “schema on read”, but put another way, this is a lack of enforced integrity.
Have poor support for joining because you have to fetch the whole document for a simple lookup.
Require extra care when designing because it’s difficult to change the document formats after the fact and because there is no generic query optimizer available.
Relational Databases …
Can provide powerful relationships, particularly with highly connected data.
However, they don’t scale horizontally very well.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Grokking the System Design Interview (Educative.io)
Generate metrics from your logs to view historical trends and track SLOs (Datadog)
Hierarchical Data – Adjacency Lists and Nested Set Models (episode 28)
Hierarchical Data cont’d – Path Enumeration and Closure Tables (episode 29)
Tip of the Week
Presto – The Distributed SQL Query Engine for Big Data. (prestodb.io)
Use the Files app in iOS to proxy files from Box or Google Drive (support.apple.com)
Pin tabs in Chrome for all of your must have open tabs. (support.google.com)
Use the Microsoft Authenticator to keep all of your one-time passwords in sync across all of your devices. And it requires you authenticate with it to even see the OTPs! (App Store, Google Play)
Combine Poker with learning with Varianto:25’s Git playing cards. (varianto25.com)
Search your Gmail for unread old emails with queries like before:2019/01/01 is:unread.
The new JetBrains Mono font is almost as awesome as the page that describes it. (JetBrains)
We’re comparing data models as we continue our deep dive into Designing Data-Intensive Applications as Coach Joe is ready to teach some basketball, Michael can’t pronounce 6NF, and Allen measured some geodesic distances just this morning.
For those reading these show notes via a podcast player, this episode’s full show notes can be found at https://www.codingblocks.net/episode123 where you can also join in on the conversation.
Sponsors
Datadog.com/codingblocks – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Educative.io – Level up your coding skills, quickly and efficiently. Visit educative.io/codingblocks to get 20% off any course or, for a limited time, get 50% off an annual subscription.
ABOUT YOU – One of the fastest growing e-commerce companies headquartered in Hamburg, Germany that is growing fast and looking for motivated team members like you. Apply now at aboutyou.com/job.
Survey Says
News
We thank everyone that took a moment to leave us a review:
iTunes: BoulderDude333, the pang1, fizch26
Hurry up and get your tickets now for NDC { London }, January 27th – 31st, where Allen will be giving his talk, Big Data Analytics in Near-Real-Time with Apache Kafka Streams. This is your chance to kick him in the shins on the other side of the pond. (ndc-london.com)
Sign up for your chance to kick Joe in the shins at the South Florida Software Developers Conference 2020, February 29th, where he will be giving his talk, Streaming Architectures by Example. (fladotnet.com)
Want a chance to kick all three Coding Blocks hosts in the shins? Sign up for the 15th Annual Orlando Code Camp & Tech Conference, March 28th, for your chance to kick them all in the shins and grab some swag. (orlandocodecamp.com)
Data Models
Data models are one of the most important pieces of developing software.
It dictates how the software is written.
And it dictates how we think about the problems we’re solving.
Software is typically written by stacking layers of modeling on top of each other.
We write objects and data structures to reflect the real world.
These then get translated into some format that will be persisted in JSON, XML, relational tables, graph db’s, etc.
The people that built the storage engine had to determine how to model the data on disk and in memory to support things like search, fast access, etc.
Even further down, those bits have to be converted to electrical current, pulses of light, magnetic fields and so on.
Complex applications commonly have many layers: APIs built on top of APIs.
What’s the purpose of these layers? To hide the complexity of the layer below it.
The abstractions allow different groups of people (potentially with completely different skillsets) to work together.
There are MANY types of data models, all with different usages and needs in mind.
It can take a LOT of time and effort to master just a single model.
Data models have a HUGE impact on how you write your applications, so its important to choose one that makes sense for what you’re trying to accomplish.
Relational Model vs Document Model
Best-known model today is probably the ones based on SQL.
The relational model was proposed by Edgar Codd back in 1970.
The relational model organizes data into relations (i.e. tables in SQL) where each relation contains an unordered collection of tuples (i.e. rows in SQL).
People originally doubted it would work but it’s dominance has lasted since the mid-80’s, which the author points out is basically an eternity in software.
Origins were based in business data processing, particularly transaction processing.
There have been a number of competing data storage and querying approaches over the years.
Network and Hierarchical models in 70’s and 80’s,
Object databases were competitors in the late 80’s and early 90’s,
XML databases,
Basically a number a competitors over the years but nobody has dethroned the relational database.
Almost everything you see and use today has some sort of relational database working behind it.
NoSQL
NoSQL is the latest competitor to Relational Databases.
It was originally intended as a catchy Twitter hashtag for a meetup about open source, distributed, non-relational databases.
It has since been re-termed to “Not only SQL”.
What needs does NoSQL aim to address?
The need for greater scalability than traditional RDBMS’s can typically achieve, including very large datasets and fast writes.
The desire for FOSS (free and open source software), as opposed to very expensive, commercial RDBMS’s.
Specialized query operations that are not supported well in the relational model.
Shortcomings of relational models – need for more dynamic and/or expressive data models.
Different applications (or even different pieces of the same application) have different needs and may require different data models. For that reason, it’s very likely that NoSQL won’t replace SQL, but rather it’ll augment it.
This is referred to as polyglot persistence.
Object-Relational Mismatch
Most applications today are written in an object oriented programming language.
There’s typically a translation layer required to map the relational data models to an object model.
The disconnect between models can be referred to as impedance mismatch.
Frameworks like ActiveRecord, Hibernate, Entity Framework, etc., can reduce the boilerplate code needed for the translation but typically don’t fully hide the impedance mismatch issues.
Resources We Like
Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Grokking the System Design Interview (Educative.io)
Monitor Azure DevOps workflows and pipelines with Datadog (Datadog)
Monitor Amazon EKS on AWS Fargate with Datadog (Datadog)
Best practices for tagging your infrastructure and applications (Datadog)