Sun, 19 December 2021
We’re taking our time as we discuss PagerDuty’s Security Training presentations and what it means to “roll the pepper” while Michael is embarrassed in front of the whole Internet, Franklin Allen Underwood is on a full name basis, and don’t talk to Joe about corn. The full show notes for this episode are available at https://www.codingblocks.net/episode174. Sponsors - Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Thanks for the reviews!
- iTunes: Goofiw, totalwhine, Kpbmx, Viv-or-vyv
- Game Ja-Ja-Ja-Jamuary is coming up, sign up is open now! (itch.io)
- Question about unit tests, is extra code that’s only used by unit tests acceptable?
- Huge congrats to Jamie Taylor for making Microsoft MVP! Check out some of his podcasts:
Why this topic? - It’s good to learn about the common security vulnerabilities when developing software! What they are, how they are exploited, and how they are prevented.
- WebGoat is a website you can run w/ known vulnerabilities. It is designed for you to poke at and find problems with to help you learn how attackers can take advantage of problems. (OWASP.org)
- “But the framework takes care of that for me”
- Don’t be that person!
- Recent vulnerability with Grafana, CVE-2021-43798. (SOCPrime.com)
- The Log4j fiasco begins. (CNN)
- You can’t always wait for a vulnerability patch to be released. You may need to patch one yourself.
- Basically, even if you’re using a framework, it doesn’t mean you can be naïve to everything about it.
- You shouldn’t use the excuse “It’s just for a hackathon” or “It’s a proof of concept.”
- This can include things like disabling firewalls, etc.
- Don’t put things on a public repo, as you might accidentally share company secrets, intellectual property, etc.
- Open sourcing may be an option later, but it should be looked through first.
- NEVER use customer data when doing hackathons or proofs of concepts. Too many things can go wrong if it leaks out.
- Maybe a better rule of thumb would be to never use customer data for any type of development. Instead, always use fake data.
- The slides had an interesting story that was redacted: there was a software vulnerability that was discovered that existed due to a missing check-in of code, i.e. everything was functioning perfectly fine, and there was an effort already to plug a hole in the code, but it just never made it into the repo. Nearly impossible to detect by automated tools.
Vulnerability #1 – SQL Injection - OWASP has more a generic “Injection” as the #3 position, down from #1 in 2017.
- An example is manipulating a query at runtime with user provided input.
- This typically implies that strings are patched into a query directly, i.e.
WHERE password = '$providedPassword'. - Can be attacked by doing something like
providedPassword = ' OR 1=1 --. - Which effectively turns into
WHERE password = '' OR 1=1 --. - This is the basis for the tale of little Bobby Tables (xkcd).
- Users should NEVER be able to directly impact the runnable query.
- They can provide values, and those should be parameterized, or validated first.
- The real problem is that people with SQL knowledge can string multiple lines of SQL together to manipulate the original query in some scary ways.
Blind Injection Boolean - Boolean based attacks take time but the scripting throws errors if script results are true.
- Example they provided is “If the first database starts with an A, throw”, “If the first database starts with a B, throw”, etc.
Time Based - Uses the Boolean based attack, but puts them on a delay so they won’t be as easily detected.
- So you can just regular expressions for keywords and escape quotes right?! Ummm … no!
- There’s just too many combinations of things you’d need to know as well as weird characters and tricks you couldn’t even be aware of, double or triple encoding, exceptions, etc.
- It’s surprisingly tricky. For example, how would you allow single quotes? Replace them all with
\'? Unless there’s already a \ in front of it, but what if it’s \? - You can theoretically overcome all of these problems … but … why? Why not just do it the right way?
- The answer is to use prepared statements and/or parameterized queries.
- The difference between a prepared statement and what was mentioned above is the user’s input doesn’t directly modify a query, rather the input is substituted in the appropriate place.
- Side benefit is prepared statements often execute quicker than manually constructed SQL queries.
Vulnerability #2 – Storing Passwords - OWASP has the more generic “Cryptographic Failures” at #2, up from #3 in 2017.
- Never store passwords in plain text!
- I’ve heard hashing is good, right?
- Kind of, until you hear that there’s this thing called rainbow tables.
- Rainbow tables are basically dictionaries of passwords that have been hashed using various algorithms. This allows you to quickly look up a previously known password with a common hashing algorithm.
- Using a salt:
- This is essentially appending a random string of data to the end of a password before hashing it.
- This salt must NEVER be reused, and it should be changed every time a password is created or changes.
- The sole purpose of a salt is to ensure rainbow tables will be ineffective. The salts can be stored as plain text right next to the password, they are not a secret, they just ensure the hash will be different even if the same passwords are used multiple times.
- Using “a” pepper:
- They referred to it as a site-wide salt, which is pretty accurate.
- The pepper does the same thing as the salt, it’s appended to every password before hashing.
- The biggest difference is that the pepper is not stored alongside the data, rather it’s stored in a file on a server separate from the data.
- Essentially you’re double-salting your password before hashing.
- Password + Salt (stored next to the password with the data) + Pepper (stored on separate server), then hash.
- Pepper can make it more difficult for hackers as if they steal the database, they still don’t have the pepper.
- Pepper can also make it more difficult for the owners of the system as “rolling a pepper” can be difficult, and you have to potentially keep track of all historical peppers.
- Even with the salts and peppers, this still doesn’t fully solve the problem. Why?
- Can’t use a rainbow table, but … if a hacker has the salt and pepper, they can try to brute force the password hashes.
- They can do this because depending on the hashing algorithm chosen, the hashing is just too fast: MD5, SHA-1, etc.
- Those algorithms weren’t designed for security, they were designed for speed.
- Solution: Key-stretching
- This is running the password through a hash algorithm a large number of times.
- The output of the first hash will be the input for the second hash, and so on.
- The whole point is to make it take longer to hash. If you were to hash a password 100k times, it might take a second.
- This means for a legit user, it’s going to take a second to hash and compare a login, but for a hacker trying to crack passwords, at MOST they’ll be able to do one attempt per second.
- Following the math here, previously with a single MD5 or similar hash, the hacker could attempt 100k password cracks per second vs one per second.
- It’s still not perfect. Hardware is constantly getting better. So what’s a good and slow today, may not be in a year.
- Adaptive Hashing:
- Same concepts as above, except you can increase the number of hashing rounds as time goes on.
- Really what you want is the cost to hack a password for a given algorithm. PagerDuty had a nice slide on this that estimated the cost of hardware to crack a password in one year.
- Good algorithms for increasing the cost to hackers are bcrypt, scrypt and PBKDF2.
- These were designed for hashing passwords specifically.
- Salting and key stretching are also built into the algorithms so you don’t have to go do it on your own.
Resources we Like Tip of the Week - Did you know you can mail merge in Gmail? It works well! (developers.google.com)
- Tip from Jamie Taylor: DockerSlim is a tool for slimming down your Docker images to reduce your image sizes and security foot print. You can minify it by up to 30x. Free and open-source. (GitHub)
- Game Jam is coming up, checking out the free assets provided by Unity in the asset store. The quality is incredible and inspiring and the items range from art work to controllers (think FPS, 3P) to full “microgames” that you can take and build with till your heart’s content. Most are free and the one’s that aren’t are cheap and interesting. (assetstore.unity.com)
- while True: learn() is a puzzle video game that can help teach you machine learning techniques. Thanks to Alex from GamingFyx for sharing this!
- Now that Zsh is the default shell in macOS, it’s time to get comfy and set up tab completion (ScriptingOSX.com)
- GiTerm is a command line tool for visualizing Git information. (GitHub)
Direct download: coding-blocks-episode-174.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 5 December 2021
With Game Ja-Ja-Ja-Jamuary coming up, we discuss what makes a game engine, while Michael’s impersonation is spot-on, Allen may really just be Michael, and Joe already has the title of his next podcast show at the ready. The full show notes for this episode are available at https://www.codingblocks.net/episode173. Sponsors - Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says Game Jam ’22 is coming up in Ja-Ja-Ja-Jamuary News - Thanks for the reviews!
- Podchaser: Jamie Introcaso
- Game Ja-Ja-Ja-Jamuary is coming up, sign up is open now! (itch.io)
What is a Game Engine? - What’s a…
- Library,
- Framework,
- Toolkit,
- … Engine?
- Want to see terrible explanations of a thing? Google “framework vs engine”.
- Other types of engines: storage engine, rendering engine, for example.
Q: Why do people use game engines? Well, they reduce costs, complexities, and time-to-market. Consistency!
Q: Why do so many AAA games create their own custom engines? Common Features of Game Engines - 2D/3D rendering engine
- Basic shapes (planes, spheres, lines),
- Particles, Shaders,
- Masking/Culling,
- Progressive enhancement (either by distance or by some other means)
- Physics engine
- Mass,
- Gravity,
- Torque,
- Force,
- Friction,
- Springiness,
- Fluid Dynamics,
- Wind
- Sound
- Multiple sounds at once, looping, spatial settings, etc.
- Scripting
- AI
- Networking
- Ever thought about how this works? Peer to peer, dedicated servers?
- Streaming
- Streaming assets, as in, the player hasn’t installed your game.
- Scene Management
- Cinematics
- UI
- Often engines also include development tools to making working with these various systems easier … like an IDE.
Some Really Cool Things About Unity - Asset Store and Package Management,
- ProBuilder (Unity),
- Terrain,
- Animation Manager,
- Ad Systems and Analytics,
- Target multiple platforms: Xbox, Windows, Linux, Android, MacOS, iOS, PSX, Switch, etc.
About the Industry - How big is the industry?
- $150B in 2019, estimated $250B for 2025 (TechJury.net)
- How does it compare to other industries?
- Movies are $41B,
- Books are $25B,
- Netflix is $7B … that’s about half of Nintendo,
- HBO is $2B
- How many companies and employees?
- 2,457 companies and 220k jobs … in 2015! (Quora)
- What’s the breakdown on sales?
- How many games released in a year?
- How long does it take? 1 – 10 years?
- The 10 Best Games Made By Just One Person (TheGamer.com)
Commentary on Popular Game Engines Unity - Publish for 20+ platforms
- 50% of games are made with Unity (GameDeveloper.com)
- List of Unity games (Wikpedia)
- Pricing range: Free to $2,400. You can use the free plan if revenue or funding is less than $100k!
- Program in C#
- Great learning resources (learn.unity.com)
Unreal - Many AAA games built with Unreal. Basically think of the top 10 biggest, most beautiful, AAA games; those are probably all Unreal or custom (RAGE, Frostbyte, Last of Us)
- Pricing: from free to “call for pricing”, 5% royalty after $1mm
- List of Unreal Engine games (Wikipedia)
- Originally came out of the Unreal series of games, and a new one is coming out soon! (Epic Games)
- Program in C++
Godot - Open Source
- Growing in popularity
- You can program in a variety of languages, officially C/C++ and GDScript but there are other bindings (Wikipedia)
Custom Game Engines: - GameMaker
- RPG Maker
- Specialized: Frostbyte, Cryo, etc.
- Korge
- libGDX
Final Question Game Jam sign-up is live … what are you thinking for technology and mechanics? - Allen: VR / Escape Room
- Michael: Something web based
- Joe: Going 3D, wanting to focus on level design and physics this time
Resources We Like Tip of the Week - ProBuilder is a free tool available in Unity that is great for making polygons and great for mocking out levels or building ramps. The coolest part is the way it works, giving you a bunch of tools that you do things like create vertices, edges, surfaces, extrude, intrude, mirror, etc. You have to add it via the package manager but it’s worth it for simple games and prototypes. (Unity)
- Great blog on processing billions of events in real time at Twitter, thanks Mikerg! (blog.twitter.com)
forEachIndexed is a nice Kotlin method for iterating through items in a collection, with an index for positional based computations (ozenero.com)- How can you log out of Netflix on Samsung Smart TVs? Ever heard of the Konami code? Press Up Up Down Down Left Right Left Right Up Up Up Up (help.netflix.com)
Direct download: coding-blocks-episode-173.mp3
Category: Software Development
-- posted at: 9:32pm EDT
|
|
Sun, 21 November 2021
We wrap up the discussion on partitioning from our collective favorite book, Designing Data-Intensive Applications, while Allen is properly substituted, Michael can’t stop thinking about Kafka, and Joe doesn’t live in the real sunshine state. The full show notes for this episode are available at https://www.codingblocks.net/episode172. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Game Ja Ja Ja Jam is coming up, sign up is open now! (itch.io)
- Joe finished the Create With Code Unity Course (learn.unity.com)
- New MacBook Pro Review, notch be darned!
Last Episode …  Best book evar! Best book evar! In our previous episode, we talked about data partitioning, which refers to how you can split up data sets, which is great when you have data that’s too big to fit on a single machine, or you have special performance requirements. We talked about two different partitioning strategies: key ranges which works best with homogenous, well-balanced keys, and also hashing which provides a much more even distribution that helps avoid hot-spotting. This episode we’re continuing the discussion, talking about secondary indexes, rebalancing, and routing. Partitioning, Part Deux Partitioning and Secondary Indexes - Last episode we talked about key range partitioning and key hashing to deterministically figure out where data should land based on a key that we chose to represent our data.
- But what happens if you need to look up data by something other than the key?
- For example, imagine you are partitioning credit card transactions by a hash of the date. If I tell you I need the data for last week, then it’s easy, we hash the date for each day in the week.
- But what happens if I ask you to count all the transactions for a particular credit card?
- You have to look at every single record. in every single partition!
- Secondary Indexes refer to metadata about our data that help keep track of where our data is.
- In our example about counting a user’s transactions in a data set that is partitioned by date, we could keep a separate data structure that keeps track of which partitions each user has data in.
- We could even easily keep a count of those transactions so that you could return the count of a user’s transaction solely from the information in the secondary index.
- Secondary indexes are complicated. HBase and Voldemort avoid them, while search engines like Elasticsearch specialize in them.
- There are two main strategies for secondary indexes:
- Document based partitioning, and
- Term based partitioning.
Document Based Partitioning - Remember our example dataset of transactions partitioned by date? Imagine now that each partition keeps a list of each user it holds, as well as the key for the transaction.
- When you query for users, you simply ask each partition for the keys for that user.
- Counting is easy and if you need the full record, then you know where the key is in the partition. Assuming you store the data in the partition ordered by key, it’s a quick lookup.
- Remember Big O? Finding an item in an ordered list is
O(log n). Which is much, much, much faster than looking at every row in every partition, which is O(n). - We have to take a small performance hit when we insert (i.e. write) new items to the index, but if it’s something you query often it’s worth it.
- Note that each partition only cares about the data they store, they don’t know anything about what the other partitions have. Because of that, we call it a local index.
- Another name for this type of approach is “scatter/gather”: the data is scattered as you write it and gathered up again when you need it.
- This is especially nice when you have data retention rules. If you partition by date and only keep 90 days worth of data, you can simply drop old partitions and the secondary index data goes with them.
Term Based Partitioning - If we are willing to make our writes a little more complicated in exchange for more efficient reads, we can step up to term based partitioning.
- One problem with having each partition keeping track of their local data is you have to query all the partitions. What if the data’s only on one partition? Our client still needs to wait to hear back from all partitions before returning the result.
- What if we pulled the index data away from the partitions to a separate system?
- Now we check this secondary index to figure out the keys, which we can then go look up on the appropriate indices.
- We can go one step further and partition this secondary index so it scales better. For example,
userId 1-100 might be on one, 101-200 on another, etc. - The benefit of term based partitioning is you get more efficient reads, the downside is that you are now writing to multiple spots: the node the data lives on and any partitions in our indexing system that we need to account for any secondary indexes. And this is multiplied by replication.
- This is usually handled by asynchronous writes that are eventually consistent. Amazon’s DynamoDB states it’s global secondary indexes are updated within a fraction of a second normally.
Rebalancing Partitions - What do you do if you need to repartition your data, maybe because you’re adding more nodes for CPU, RAM, or losing nodes?
- Then it’s time to rebalance your partitions, with the goals being to …
- Distribute the load equally-ish (notice we didn’t say data, could have some data that is more important or mismatched nodes),
- Keep the database operational during the rebalance procedure, and
- Minimize data transfer to keep things fast and reduce strain on the system.
- Here’s how not to do it:
hash % (number of nodes) - Imagine you have 100 nodes, a key of 1000 hashes to 0. Going to 99 nodes, that same key now hashes to 1, 102 nodes and it now hashes to 4 … it’s a lot of change for a lot of keys.
Partitions > Nodes - You can mitigate this problem by fixing the number of partitions to a value higher than the number of nodes.
- This means you move where the partitions go, not the individual keys.
- Same recommendation applies to Kafka: keep the numbers of partitions high and you can change nodes.
- In our example of partitioning data by date, with a 7 years retention period, rebalancing from 10 nodes to 11 is easy.
- What if you have more nodes than partitions, like if you had so much data that a single day was too big for a node given the previous example?
- It’s possible, but most vendors don’t support it. You’ll probably want to choose a different partitioning strategy.
- Can you have too many partitions? Yes!
- If partitions are large, rebalancing and recovering from node failures is expensive.
- On the other hand, there is overhead for each partition, so having many, small partitions is also expensive.
Other methods of partitioning - Dynamic partitioning:
- It’s hard to get the number of partitions right especially with data that changes it’s behavior over time.
- There is no magic algorithm here. The database just handles repartitioning for you by splitting large partitions.
- Databases like HBase and RethinkDB create partitions dynamically, while Mongo has an option for it.
- Partitioning proportionally to nodes:
- Cassandra and Ketama can handle partitioning for you, based on the number of nodes. When you add a new node it randomly chooses some partitions to take ownership of.
- This is really nice if you expect a lot of fluctuation in the number of nodes.
Automated vs Manual Rebalancing - We talked about systems that automatically rebalance, which is nice for systems that need to scale fast or have workloads that are homogenized.
- You might be able to do better if you are aware of the patterns of your data or want to control when these expensive operations happen.
- Some systems like Couchbase, Riak, and Voldemort will suggest partition assignment, but require an administrator to kick it off.
- But why? Imagine launching a large online video game and taking on tons of data into an empty system … there could be a lot of rebalancing going on at a terrible time. It would have been much better if you could have pre-provisioned ahead of time … but that doesn’t work with dynamic scaling!
Request Routing - One last thing … if we’re dynamically adding nodes and partitions, how does a client know who to talk to?
- This is an instance of a more general problem called “service discovery”.
- There are a couple ways to solve this:
- The nodes keep track of each other. A client can talk to any node and that node will route them anywhere else they need to go.
- Or a centralized routing service that the clients know about, and it knows about the partitions and nodes, and routes as necessary.
- Or require that clients be aware of the partitioning and node data.
- No matter which way you go, partitioning and node changes need to be applied. This is notoriously difficult to get right and REALLY bad to get wrong. (Imagine querying the wrong partitions …)
- Apache ZooKeeper is a common coordination service used for keeping track of partition/node mapping. Systems check in or out with ZooKeeper and ZooKeeper notifies the routing tier.
- Kafka (although not for much longer), Solr, HBase, and Druid all use ZooKeeper. MongoDb uses a custom ConfigServer that is similar.
- Cassandra and Riak use a “gossip protocol” that spreads the work out across the nodes.
- Elasticsearch has different roles that nodes can have, including data, ingestion and … you guessed it, routing.
Parallel Query Execution - So far we’ve mostly talked about simple queries, i.e. searching by key or by secondary index … the kinds of queries you would be running in NoSQL type situations.
- What about? Massively Parallel Processing (MPP) relational databases that are known for having complex join, filtering, aggregations?
- The query optimizer is responsible for breaking down these queries into stages which target primary/secondary indexes when possible and run these stages in parallel, effectively breaking down the query into subqueries which are then joined together.
- That’s a whole other topic, but based on the way we talked about primary/secondary indexes today you can hopefully have a better understanding of how the query optimizer does that work. It splits up the query you give it into distinct tasks, each of which could run across multiple partitions/nodes, runs them in parallel, and then aggregates the results.
- Designing Data-Intensive Applications goes into it in more depth in future chapters while discussing batch processing.
Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Tip of the Week - PowerLevel10k is a Zsh “theme” that adds some really nice features and visual candy. It’s highly customizable and works great with Kubernetes and Git. (GitHub)
- If for some reason VS Code isn’t in your path, you can add it easily within VS Code. Open up the command palette (
CTRL+SHIFT+P / COMMAND+SHIFT+P) and search for “path”. Easy peasy! - Gently Down the Stream is a guidebook to Apache Kafka written and illustrated in the style of a children’s book. Really neat way to learn! (GentlyDownThe.Stream)
- PostgreSQL is one of the most powerful and versatile databases. Here is a list of really cool things you can do with it that you may not expect. (HakiBenita.com)
 Check out PowerLevel10k
Direct download: coding-blocks-episode-172.mp3
Category: Software Development
-- posted at: 9:10pm EDT
|
|
Sun, 7 November 2021
We crack open our favorite book again, Designing Data-Intensive Applications by Martin Kleppmann, while Joe sounds different, Michael comes to a sad realization, and Allen also engages “no take backs”. The full show notes for this episode are available at https://www.codingblocks.net/episode171. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Thank you for the review!
Best book evar! The Whys and Hows of Partitioning Data - Partitioning is known by different names in different databases:
- Shard in MongoDB, ElasticSearch, SolrCloud,
- Region in HBase,
- Tablet in BigTable,
- vNode in Cassandra and Riak,
- vBucket in CouchBase.
- What are they?
- In contrast to the replication we discussed, partitioning is spreading the data out over multiple storage sections either because all the data won’t fit on a single storage mechanism or because you need faster read capabilities.
- Typically data records are stored on exactly one partition (record, row, document).
- Each partition is a mini database of its own.
Why partition? Scalability - Different partitions can be put on completely separate nodes.
- This means that large data sets can be spread across many disks, and queries can be distributed across many processors.
- Each node executes queries for its own partition.
- For more processing power, spread the data across more nodes.
- Examples of these are NoSQL databases and Hadoop data warehouses.
- These can be set up for either analytic or transactional workloads.
- While partitioning means that records belong to a single partition, those partitions can still be replicated to other nodes for fault tolerance.
- A single node may store more than one partition.
- Nodes can also be a leader for some partitions and a follower for others.
- They noted that the partitioning scheme is mostly independent of the replication used.
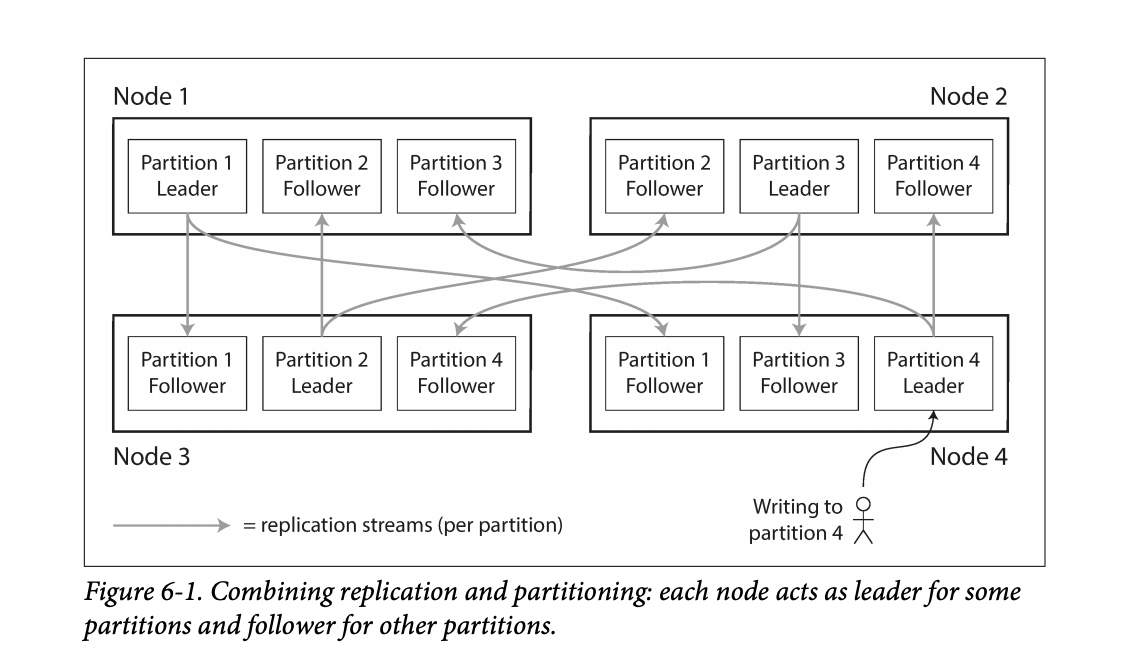 Figure 6-1 in the book shows this leader / follower scheme for partitioning among multiple nodes. Figure 6-1 in the book shows this leader / follower scheme for partitioning among multiple nodes. - The goal in partitioning is to try and spread the data around as evenly as possible.
- If data is unevenly spread, it is called skewed.
- Skewed partitioning is less effective as some nodes work harder while others are sitting more idle.
- Partitions with higher than normal loads are called hot spots.
- One way to avoid hot-spotting is putting data on random nodes.
- Problem with this is you won’t know where the data lives when running queries, so you have to query every node, which is not good.
Partitioning by Key Range - Assign a continuous range of keys on a particular partition.
- Just like old encyclopedias or even the rows of shelves in a library.
- By doing this type of partitioning, your database can know which node to query for a specific key.
- Partition boundaries can be determined manually or they can be determined by the database system.
- Automatic partition is done by BigTable, HBase, RethinkDB, and MongoDB.
- The partitions can keep the keys sorted which allow for fast lookups. Think back to the SSTables and LSM Trees.
- They used the example of using timestamps as the key for sensor data – ie
YY-MM-DD-HH-MM. - The problem with this is this can lead to hot-spotting on writes. All other nodes are sitting around doing nothing while the node with today’s partition is busy.
- One way they mentioned you could avoid this hot-spotting is maybe you prefix the timestamp with the name of the sensor, which could balance writing to different nodes.
- The downside to this is now if you wanted the data for all the sensors you’d have to issue separate range queries for each sensor to get that time range of data.
- Some databases attempt to mitigate the downsides of hot-spotting. For example, Elastic has the ability specify an index lifecycle that can move data around based on the key. Take the sensor example for instance, new data comes in but the data is rarely old. Depending on the query patterns it may make sense to move older data to slower machines to save money as time marches on. Elastic uses a temperature analogy allowing you to specify policies for data that is hot, warm, cold, or frozen.
Partitioning by Hash of the Key - To avoid the skew and hot-spot issues, many data stores use the key hashing for distributing the data.
- A good hashing function will take data and make it evenly distributed.
- Hashing algorithms for the sake of distribution do not need to be cryptographically strong.
- Mongo uses MD5.
- Cassandra uses Murmur3.
- Voldemort uses Fowler-Noll-Vo.
- Another interesting thing is not all programming languages have suitable hashing algorithms. Why? Because the hash will change for the same key. Java’s
object.hashCode() and Ruby’s Object#hash were called out. - Partition boundaries can be set evenly or done pseudo-randomly, aka consistent hashing.
- Consistent hashing doesn’t work well for databases.
- While the hashing of keys buys you good distribution, you lose the ability to do range queries on known nodes, so now those range queries are run against all nodes.
- Some databases don’t even allow range queries on the primary keys, such as Riak, Couchbase, and Voldemort.
- Cassandra actually does a combination of keying strategies.
- They use the first column of a compound key for hashing.
- The other columns in the compound key are used for sorting the data.
- This means you can’t do a range query over the first portion of a key, but if you specify a fixed key for the first column you can do a range query over the other columns in the compound key.
- An example usage would be storing all posts on social media by the user id as the hashing column and the updated date as the additional column in the compound key, then you can quickly retrieve all posts by the user using a single partition.
- Hashing is used to help prevent hot-spots but there are situations where they can still occur.
- Popular social media personality with millions of followers may cause unusual activity on a partition.
- Most systems cannot automatically handle that type of skew.
- In the case that something like this happens, it’s up to the application to try and “fix” the skew. One example provided in the book included appending a random 2 digit number to the key would spread that record out over 100 partitions.
- Again, this is great for spreading out the writes, but now your reads will have to issue queries to 100 different partitions.
- Couple examples:
- Sensor data: as new readings come in, users can view real-time data and pull reports of historical data,
- Multi-tenant / SAAS platforms,
- Giant e-commerce product catalog,
- Social media platform users, such as Twitter and Facebook.
 The first Google computer at Stanford was housed in custom-made enclosures constructed from Mega Blocks. (Wikipedia) The first Google computer at Stanford was housed in custom-made enclosures constructed from Mega Blocks. (Wikipedia) Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- History of Google (Wikipedia)
Tip of the Week - VS Code lets you open the search results in an editor instead of the side bar, making it easier to share your results or further refine them with something like regular expressions.
- Apple Magic Keyboard (for iPad Pro 12.9-inch – 5th Generation) is on sale on Amazon. Normally $349, now $242.99 on Amazon and Best Buy usually matches Amazon.(Amazon)
- Compatible Devices:
- iPad Pro 12.9-inch (5th generation),
- iPad Pro 12.9-inch (4th generation),
- iPad Pro 12.9-inch (3rd generation)
- Room EQ Wizard is free software for room acoustic, loudspeaker, and audio device measurements. (RoomEQWizard.com)
Direct download: coding-blocks-episode-171.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 24 October 2021
The Mathemachicken strikes again for this year’s shopping spree, while Allen just realized he was under a rock, Joe engages “no take backs”, and Michael ups his decor game. The full show notes for this episode are available at https://www.codingblocks.net/episode170. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Thank you to everyone that left a review!
- iTunes: BoldAsLove88
- Audible: Tammy
Joe’s List
Allen’s List
Michael’s List
Resources We Like - Security Now 834, Life: Hanging By A Pin (Twit.tv)
- Buyer Beware: Crucial Swaps P2 SSD’s TLC NAND for Slower Chips (ExtremeTech.com)
- Samsung Is the Latest SSD Manufacturer Caught Cheating Its Customers (ExtremeTech.com)
Tip of the Week - VS Code … in the browser … just … there? Not all extensions work, but a lot do! (VSCode.dev)
- Skaffold is a tool you can use to build and maintain Kubernetes environments that we’ve mentioned on the show several times and guess what!? You can make your life even easier with Skaffold with environment variables. It’s another great way to maintain flexibility for your environments … both local and CI/CD. (Skaffold.dev)
- K9s is a Kubernetes terminal UI that makes it easy to quickly search, browse, filter, and edit your clusters and it also has skins! The Solarized Light theme is particularly awesome for customizing your experience, especially for presenting. (GitHub)
Direct download: coding-blocks-episode-170.mp3
Category: Software Development
-- posted at: 10:00pm EDT
|
|
Sun, 10 October 2021
We discuss the pros and cons of speaking at conferences and similar events, while Joe makes a verbal typo, Michael has turned over a new leaf, and Allen didn’t actually click the link. The full show notes for this episode are available at https://www.codingblocks.net/episode169. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News  The Kinesis Gaming Freestyle Edge RGB Split Mechanical Keyboard might be the current favorite. - Thank you to everyone that left a review!
- How long does it take to get the Moonlander? (ZSA.io)
- Is the Kinesis Gaming Freestyle the current favorite? (Amazon)
- Atlanta Code Camp was fantastic, see you again next year! (atlantacodecamp.com)
What kind of speaking are we talking about? - Conferences
- Meetups
- Does YouTube/Twitch count as tech presentations?
- There are some similarities! Streaming has the engagement, but generally isn’t as rehearsed. Published videos are closer to the format but you have to make some assumptions about your audience and can get creative with the editing.
Why do people speak? - Can help you build an audience
- Establish credibility
- Promotional opportunities
- Networking
- Free travel/conferences
- Great way to learn something
- Become a better communicator
- Is it fun?
Who speaks at conferences? - People speak at conferences for different reasons
- Couple different archetypes of speakers:
- Sponsored: the speakers are on the job, promoting their company and products
- Practitioners: Talks from people in the trenches, usually more technical and focused on specific results or challenges
- Idea people: People who have a strong belief in something that is controversial, may have an axe to grind or an idea that’s percolating into a product
- Professionals: Some companies encourage speakers to bolster the company reputation, promotions and job descriptions might require this
How do you put together a talk? - How do you pick a talk?
- Know who is selecting talks, go niche for larger conferences if you don’t have large credentials/backing
- Sometimes conferences will encourage “tracks” certain themes for topics
- What are some talks you like? What do they do differently?
- Do you aim for something you know, or want to know?
- How do you write your talks?
- How do you practice for a talk?
- Differences between digital and physical presentations?
- How long does it take you?
Where can you find places to speak? - Is this the right question? What does this tell you about your motivation?
- Meet new people who share your interests through online and in-person events. (Meetup)
- Find your next tech conference (Confs.Tech)
- Google for events in your area!
Final Questions - Is it worth the time and anxiety?
- What do you want out of talks?
- What are some alternatives?
- Blogging
- Videos
- Open Source
- Participating in communities
Resources - Is Speaking At A Conference Really Worth Your Time? (Cleverism.com)
- We’re 93% certain that Burke Holland gave a great talk about a dishwasher and Vue.js. (Twitter)
- Monitor you Netlify sites with Datadog (Datadog)
Netlify (docs.datadoghq.com)- Risk Astley – Never Gonna Give You Up (Official Music Video) (YouTube)
- Simple Minds – Don’t You (Forget About Me) (YouTube)
- Foo Fighters With Rick Astley – Never Gonna Give You Up – London O2 Arena 19 September 2017 (YouTube)
Tip of the Week - Next Meeting is a free app for macOS that keeps a status message up in the top right of your toolbar so you know when your next meeting is. It does other stuff too, like making it easier to join meetings and see your day’s events but … the status is enough to warrant the install. Thanks MadVikingGod! (Mac App Store)
- How do I disable “link preview” in iOS safari? (Stack Exchange)
- Here is your new favorite YouTube channel, Rick Beato is a music professional who makes great videos about the music you love, focusing on what makes the songs and artists special. (YouTube)
- Hot is a free app for macOS that shows you the temperate of your MacBook Pro … and the percentage of CPU you’re limited to because of the heat! Laptop feels slow? Maybe it’s too hot! (GitHub, XS-Labs)
- What is the meaning of $? in a shell script? (Stack Exchange)
- Did you know…You can install brew on Linux? That’s right, the popular macOS packaging software is available on your favorite distro. (docs.brew.sh, brew.sh)
Direct download: coding-blocks-episode-169.mp3
Category: Software Development
-- posted at: 10:00pm EDT
|
|
Sun, 26 September 2021
Joe goes full shock jock, but only for a moment. Allen loses the "Most Tips In A Single Episode: 2021" award, and Michael didn't get the the invite notification in this week's episode. The full show notes for this episode are available at https://www.codingblocks.net/episode168. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Shortcut - Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says Well...no survey this week, but this is where it would be! News This book has a whole chapter on transactions in distributed systems - Thank you to everyone that left a review!
- "Podchaser: alexi*********, Nicholas G Larsen, Kubernutties,
- iTunes: Kidboyadde, Metalgeeksteve, cametumbling, jstef16, Fr1ek
- Audible: Anonymous (we are like your mother - go clean your room and learn Docker)
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Maintaining data consistency - Each service should have its own data store
- What about transactions? microservices.io suggests the saga pattern (website)
- A sequence of local transactions must occur
- Order service saves to its data store, then sends a message that it is done
- Customer service attempts to save to its data store…if it succeeds, the transaction is done. If it fails, it sends a message stating so, and then the Order service would need to run another update to undo the previous action
- Sound complicated? It is…a bit, you can't rely on a standard 2 Phase Commit at the database level to ensure an atomic transaction
- Ways to achieve this - choreography or orchestration
Choreography Saga - The Order Service receives the POST /orders request and creates an Order in a PENDING state
- It then emits an Order Created event
- The Customer Service’s event handler attempts to reserve credit
- It then emits an event indicating the outcome
- The OrderService’s event handler either approves or rejects the Order - Each service's local transaction sends a domain event that triggers another service's local transaction
- To sum things up, each service knows where to listen for work it should do, and it knows where to publishes the results of it's work. It's up to the designers of the system to set things up such that the right things happened
- What's good about this approach?
"The code I wrote sux. The code I'm writing is cool. The code I'm going to write rocks!" Thanks for the paraphrase Mike! Orchestration Saga - The Order Service receives the POST /orders request and creates the Create Order saga orchestrator
- The saga orchestrator creates an Order in the PENDING state
- It then sends a Reserve Credit command to the Customer Service
- The Customer Service attempts to reserve credit
- It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the Order - There is an orchestrator object that tells each service what transaction to run
- The difference between Orchestration and Choreography is that the orchestration approach has a "brain" - an object that centralizes the logic and can make more advanced changes
- These patterns allow you to maintain data consistency across multiple services
- The programming is quite a bit more complicated - you have to write rollback / undo transactions - can't rely on ACID types of transactions we've come to rely on in databases
- Other issues to understand
- The service must update the local transaction AND publish the message / event
- The client that initiates the saga (asynchronously) needs to be able to determine the outcome
- The service sends back a response when the saga completes
- The service sends back a response when the order id is created and then polls for the status of the overall saga
- The service sends back a response when the order id is created and then submits an event via a webhook or similar when the saga completes
- When would you use Orchestration vs Choreography for transactions across Microservices?
- Friend of the show @swyx works for Temporal, a company that does microservice orchestration as a service, https://temporal.io/
Tips for writing Great Microservices Fantastic article on how to keep microservices loosely coupled
https://www.capitalone.com/tech/software-engineering/how-to-avoid-loose-coupled-microservices/ - Mentions using separate data storage / dbs per service
- Can't hide implementation from other services if they can see what's happening behind the scenes - leads to tight coupling
- Share as little code as possible
- Tempting to share things like customer objects, but doing so tightly couples the various microservices
- Better to nearly duplicate those objects in a NON-shared way - that way the services can change independently
- Avoid synchronous communication where possible
- This means relying on message brokers, polling, callbacks, etc
- Don't use shared test environments / appliances
- May not sound right, but sharing a service may lead to problems - like multiple services using the same test service could introduce performance problems
- Share as little domain data as possible - ie. important pieces of information shouldn't be passed around various services in domain objects. Only the bits of information necessary should be shared with each service - ie an order number or a customer number. Just enough to let the next microservice be able to do its job
Resources Tip of the Week - Podman is an open-source containerization tool from Red Hat that provides a drop in replacement for Docker (they even recommend aliasing it!). The major difference is in how it works underneath, spawning process directly rather than relying on resident daemons. Additionally, podman was designed in a post Kubernetes world, and it has some additional tooling that makes it easier to transition to Kubernetes- like being able to spawn pods and generate Kubernetes yaml files. Website
- Check out this episode from Google's Kubernetes podcast all about it: Podcast
- Unity is the most popular game engine and they have a ton of resources in their Learning Center. Including one that is focused on writing code. It walks you through writing 5 microgames with hands on exercises where you fix projects and ultimately design and write your own simple game. Also it's free! https://learn.unity.com/course/create-with-code
- Bonus: Make sure you subscribe to Jason Weimann's YouTube channel if you are interested in making games. Brilliant coder and communicator has a wide variety of videos: YouTube
- Educative.io has been a sponsor of the show before and we really like their approach to hands on teaching so Joe took a look to see if they had any resources on C++ since he was interested in possibly pursuing competitive programming. Not only do they have C++ courses, but they actually have a course specifically for Competitive Programming in C++. Great for devs who already know a programming language and are wanting to transition without having to start at step 1. Educative Course
- The most recent Coding Blocks Mailing List contest asked for "Summer Song" recommendations, we compiled them into a Spotify Summer Playlist. These are songs that remind you of summer, and don't worry we deduped the list so there is only one song from Rick Astley on there. Spotify
- Finally, one special recommendation for Coding Music. It's niche, for sure, but if you like coding to instrumental rock/hard-rock then you have to check out a 2018 album from a band called Night Verses. It's like Russian Circles had a baby with the Mercury Program. If you are familiar with either of those bands, or just want something different then make sure to check it out. Spotify
Direct download: coding-blocks-episode-168.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 12 September 2021
Some things just require discussion, such as Docker’s new licensing, while Joe is full of it, Allen *WILL* fault them, and Michael goes on the record. The full show notes for this episode are available at https://www.codingblocks.net/episode167. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Shortcut – Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says News - Thank you to everyone that left a review!
- iTunes: Badri Ravi
- Audible: Dysrhythmic, Brent
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Docker Announcement Docker recently announced big changes to the licensing terms and pricing for their product subscriptions. These changes would mean some companies having to pay a lot more to continue using Docker like they do today. So…what will will happen? Will Docker start raking in the dough or will companies abandon Docker? Resources - Docker is Updating and Extending Our Product Subscriptions (Docker)
- Minkube documentation (Thanks MadVikingGod! From the Tips n’ Tools channel in Slack.)
- Open Container Initiative, an open governance structure for the purpose of creating open industry standards around container formats and runtimes. (opencontainers.org)
- Podman, a daemonless container engine for developing, managing, and running OCI containers. (podman.io)
- Getting Started with K9s (YouTube)
How valuable is education? How do you decide when it’s time to go back to school or get a certification? What are the determining factors for making those decisions? Full-Stack Road Map What’s on your roadmap? We found a full-stack roadmap on dev.to and it’s got some interesting differences from other roadmaps we’ve seen or the roadmaps we’ve made. What are those differences? Resources - Full Stack Developer’s Roadmap (dev.to)
Bonus Tip: You can find the top dev.to articles for certain time periods like: https://dev.to/top/year. Works for week, month, and day, too. Where does your business logic go? Business logic should be in a service, not in a model … or should it? What’s the right way to do this? Is there a right way? Resources Are the M1/M1X chips a good idea for devs? Last year’s MacBook Pros introduced new M1 processors based on a RISC architecture. Now Apple is rolling out the rest of the line. What does this mean for devs? Is there a chance you will regret purchasing one of these laptops? Resources Tip of the Week - Hit
. (i.e. the period key) in GitHub to bring up an online VS Code editor while you are logged in. Thanks Morten Olsrud! (blog.yogeshchavan.dev) - Shoutout to Coder, cloud-powered development environments that feel local. (coder.com)
- The podcast that puts together the the “perfect album” for the topic du jour: The Perfect Album Side Podcast (iTunes, Spotify, Google Podcasts)
- Bon Jovi – Livin’ On A Prayer / Wanted Dead Or Alive (Los Angeles 1989) (YouTube)
- Docker’s
system prune command now includes a filter option to easily get rid of older docker resources. (docs.docker.com) - Example:
docker system prune --filter="until=72h" - The GitHub CLI makes it easy to create PR by autofilling information, as well as pushing your branch to origin:
- Apache jclouds is an open-source multi-cloud toolkit that abstracts the details of your cloud provider away so you can focus on your code and still support multiple providers. (jclouds.apache.org)
Direct download: coding-blocks-episode-167.mp3
Category: Software Development
-- posted at: 9:44pm EDT
|
|
Sun, 29 August 2021
We step away from our microservices deployments to meet around the water cooler and discuss the things on our minds, while Joe is playing Frogger IRL, Allen “Eeyores” his way to victory, and Michael has some words about his keyvoard, er, kryboard, leybaord, ugh, k-e-y-b-o-a-r-d! The full show notes for this episode are available at https://www.codingblocks.net/episode166. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Clubhouse – Project management has never been easier. Check out how Clubhouse (soon to be Shortcut) is project management without all the management.
Survey Says News - The threats worked and we got new reviews! Thank you to everyone that left a review:
- iTunes: ArcadeyGamey, Mc’Philly C. Steak, joby_h
- Audible: Jake Tucker
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Water Cooler Gossip > Office Memos - Are you interested in competitive programming?
- Michael gives a short term use review of his Moonlander.
- Spring makes Java better.
Resources We Like - CoRecursive episode 65: From Competitive Programming to APL With Conor Hoekstra (corecursive.com)
- Competitive Programming – A Complete Guide (GeeksForGeeks.org)
- Get started solving problems on Code Chef (CodeChef.com)
- Introduction to Dynamic Programming 1 (HackerEarth.com)
- Enhance your skills, expand your knowledge, and prepare for technical interviews with LeetCode. (LeetCode.com)
- Getting started with Competitive Programming – Build your algorithm skills (dev.to)
- ZSA Moonlander (zsa.io)
- Spring Framework Documentation (docs.spring.io)
- Spring Expression Language (SpEL) (docs.spring.io)
- RethinkDB, the open-source database for the realtime web. (RethinkDB.com)
Tip of the Week - Learn C the Hard Way: Practical Exercises on the Computational Subjects You Keep Avoiding (Like C) by Zed Shaw (Amazon)
- With Windows Terminal installed:
- In File Explorer, right click on or in a folder and select Open in Windows Terminal.
- Right click on the Windows Terminal icon to start a non-default shell.
- SonarLint is a free and open source IDE extension that identifies and helps you fix quality and security issues as you code. (SonarLint.org)
- Use
docker buildx to create custom builders. Just be sure to call docker buildx stop when you’re done with it. (Docker docs: docker buildx, docker buildx stop)
Direct download: coding-blocks-episode-166.mp3
Category: Software Development
-- posted at: 9:39pm EDT
|
|
Sun, 15 August 2021
We decide to dig into the details of what makes a microservice and do we really understand them as Joe tells us why we really want microservices, Allen incorrectly answers the survey, and Michael breaks down in real time. The full show notes for this episode are available at https://www.codingblocks.net/episode165. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Want to know why we’re so hot on Skaffold? Check out this video from Joe: Getting Started with Skaffold (YouTube)
- Atlanta Code Camp is coming up October 9th, come hang out at the CB booth!
Want to know what’s up with Skaffold? We Thought We Knew About Microservices What are Microservices? - A collection of services that are…
- Highly maintainable and testable
- Loosely coupled (otherwise you just have a distributed monolith!)
- Independently deployable
- Organized around business capabilities (super important, Microservices are just as much about people organization as they are about code)
- Owned by a small team
- A couple from Jim Humelsine (Design Patterns Evangelist)
- Stateless
- Independently scalable (both in terms of tech, but also personnel)
- Note: we didn’t say anything about size but Sam Newman’s definition is: “Microservices are small, autonomous services that work together.”
- Semantic Diffusion (vague term getting vaguer)
- Enables frequent and reliable delivery of complex applications
- Allows you to evolve your tech stack (reminiscent of the strangler pattern)
- They are NOT a silver bullet – Many downsides
A Pattern Language - A collection of patterns for apply microservice patterns
- Example Microservice Implementation: https://microservices.io/patterns/microservices.html
- 3 micro-services in the example:
- Inventory service
- Account service
- Shipping service
- Each services talks to a separate backend database – i.e., inventory service talks to inventory DB, etc.
- Fronting those micro-services are a couple of API’s – a mobile gateway API and an API that serves a website
When an order is placed, a request is made to the mobile API to place the order, the mobile API has to make individual calls to each one of the individual micro-services to get / update information regarding the order - This setup is in contrast to a monolithic setup where you’d just have a single API that talks to all the backends and coordinates everything itself
Pros of the Microservice Architecture - Each service is small so it’s easier to understand and change
- Easier / faster to test as they’re smaller and less complex
- Better deployability – able to deploy each service independently of the others
- Easier to organize development effort around smaller, autonomous teams
- Because the code bases are smaller, the IDEs are actually better to work in
- Improved fault isolation – example they gave is a memory leak won’t impact ALL parts of the system like in a monolithic design
- Applications start and run faster when they are smaller
- Allows you to be more flexible with tech stacks – you can change out small pieces rather than entire systems if necessary
Cons of the Microservice Approach - Additional complexity of a distributed system
- Distributed debugging is hard! Requires additional tooling
- Additional cost (overhead of services, network traffic)
- Multi-system transactions are really hard
- Implementing inter-service communication and handling of failures
- Implementing multi-service requests is more complex
- Not only more complex, but you may be interfacing with multiple developer teams as well
- Testing interactions between services is more complex
- IDEs don’t really make distributed application development easier – more geared towards monolithic apps
- Deployments are more complex – managing multiple services, dependencies, etc.
- Increased infrastructure requirements – CPU, memory, etc.
- Distributed debugging is hard! Requires additional tooling
How to Know When to Choose the Microservice Architecture This is actually a hard problem. - Choosing this path can slow down development
- However, if you need to scale in the future, splitting apart / decomposing a monolith may be very difficult
Decomposing an Application into Microservices - Do so by business capability
- Example for e-commerce: Product catalog management, Inventory management, Order management, Delivery management
- How do you know the right way to break down the business capabilities?
- Organizational structure – customer service department, billing, shipping, etc
- Domain model – these usually map well from domain objects to business functions
- Which leads to decomposing by domain driven design
- Decompose by “verb” – ship order, place order, etc
- Decompose by “noun” – Account service, Order service, Billing service, etc
- Follow the Single Responsibility Principal – similar to software design
Questions About Microservices - Are Microservices a conspiracy?
- Isn’t this just SOA over again?
- How can you tell if you should have Microservices?
- Who uses Microservices?
- Netlifx
- Uber
- Amazon
- Lots of other big companies
- Who has abandoned Microservices?
- Lots of small companies…seeing a pattern here?
Resources We Like Tip of the Week - NeoVim is a fork of Vim 7 that aims to address some technical debt in vim in hopes of speeding up maintenance, plugin creation, and new features. It supports RPC now too, so you can write vim plugins in any language you want. It also has better support for background jobs and async tasks. Apparently the success of nvim has also led to some of the more popular features being brought into vim as well. Thanks Claus/@komoten! (neovim.io)
- Portable Apple Watch charger lets you charge your watch wirelessly from an outlet, or a usb. Super convenient! (Amazon)
- Free book from Linode explaining how to secure your Docker containers. Thanks Jamie! (Linode)
- There is a daily.dev plugin for Chrome that gives you the dev home page you deserve, delivering you dev news by default. Thanks @angryzoot! (Chrome Web Store)
- SonarQube is an open-source tool that you can run on your code to pull metrics on it’s quality. And it’s available for you to run in docker Thanks Derek Chasse! (hub.docker.com)
Direct download: coding-blocks-episode-165.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 1 August 2021
We dive into JetBrains’ findings after they recently released their State of the Developer Ecosystem for 2021 while Michael has the open down pat, Joe wants the old open back, and Allen stopped using the command line. The full show notes for this episode are available at https://www.codingblocks.net/episode164. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - We really appreciate the latest reviews, so thank you!
- Allen has been making videos of some of our tips:
- Atlanta Code Camp is coming up October 9th, come hang out at the CB booth!
Check out Allen’s Quick Tips! Why JetBrains? JetBrains has given us free licenses to give out for years now. Sometimes people ask us what it is that we like about their products, especially when VS Code is such a great (and 100% free) experience…so we’ll tell ya! - JetBrains produces (among other things) a host of products that are all based on the same IDEA platform, but are custom tailored for certain kinds of development. CLion for C, Rider for C#, IntelliJ for JVM, WebStorm for front-end, etc. These IDEs support plugins but they come stocked with out-of-the-box functionality that you would have to add via plugins in a generalized Editor or IDE
- This also helps keep consistency amongst developers…everybody using the same tools for git, databases, formatting, etc
- Integrated experience vs General Purpose Tool w/ Plugins, Individual plugins allow for a lot of innovation and evolution, but they aren’t designed to work together in the same way that you get from an integrated experience.
- JetBrains has assembled a great community
- Supporting user groups, podcasts, and conferences for years with things like personal licenses
- Great learning materials for multiple languages (see the JetBrains Academy)
- Community (free) versions of popular products (Android Studio, IntelliJ, WebStorm, PyCharm)
- Advanced features that have taken many years of investment and iteration (Resharper/Refactoring tools)
- TL;DR JetBrains has been making great products for 20 years, and they are still excelling because those products are really good!
- Survey was comprised of 31,743 developers from 183 countries. JetBrains attempted to get a wide swath of diverse responses and they weighted the results in an attempt to get a realistic view of the world. Read more about the methodology
- What would you normally expect from JetBrain’s audience? (Compare to surveys from StackOverflow or Github or State of JS)
- JetBrains are mainly known for non-cheap, heavy duty tools so you might expect to see more senior or full time employees than StackOverlow, but that’s not the case…it skews younger
- Professional / Enterprise (63% full-time, 70.9% on latest Stack Overflow)
- JetBrains 3-5 vs StackOverflow 5-9 years of experience
- Education level is similar
- 71% of respondents develop for web backend!
- JavaScript is the most popular language
- Python is more popular than Java overall, but Java is more popular as a main language
- Top 5 languages devs are planning to adopt:
- Go
- Kotlin
- TypeScript
- Python
- Rust
- Top 5 Languages devs learning in 2021:
- Languages that fell:
- Top 5 Fastest Growing:
- Python
- TypeScript
- SQL
- Go
- Kotlin
- 71% of respondents develop for web backend
- Primary programming languages, so much JS!
- Developer OS:
- 61% Windows
- 47% linux
- 44% macOS
- What sources of information… Podcasts 31%! Glad to see this up there, of course
- 74% of the respondents use online ad-blocking tools
- Accounts: Github 84% Reddit…47%?
- Workplace and Events – pre covid comparisons
- Video Games are #1 hobby, last year was programming
- Used in last 12 Months, Primary…so much MySQL
- Really cool to see relative popularity by programming language
- How familiar are you with Docker?
- DevOps engineers are 2x more likely to be architects, 30% more likely to be leads
- Kubernetes: went from 16% to 29% to 40% to…40%. Is Kubernetes growth stalling?
- 90% of devs who use k8s have SSD, have above average RAM
- 53% of hosting is in the cloud? Still moving up, but there’s also a lot of growth with Hybrad
- AWS has a big lead in cloud services…GCP 2nd!? Let’s speculate how that happened, that’s not what we see in financial reports
- During development, where do you run and debug your code? (Come to Joe’s skaffold talk!)
- 35% of respondents develop microservices!!!!! Can this be right?
- Mostly senior devs are doing microservices
- GraphQL at 14%, coming up a little bit from last year
- How much RAM? (Want more RAM? Be DevOps, Architect, Data Analyst, leads)
- 79% of devs have SSD? Excellent!
- How old is your computer? Survey says….2 years? That’s really great.
- 75% say tests play an integral role, 44% involved. Not bad…but 44% not involved, huh?
- 67% Unit tests, yay!
Resources We Like Tip of the Week - The CoRecursive podcast has fantastic interviews with some really interesting people (corecursive.com) Thanks @msuriar. Some highlights:
- Free audiobook/album from the Software Daily host: Move Fast: How Facebook Builds Software (softwareengineeringdaily.com)
- Apple has great features and documentation on the different ways to take screenshots in macOS (support.apple.com)
- Data, Data, Data: Let the data guide your decisions. Not feelings.
- HTTPie is a utility built in Python that makes it really issue to issue web requests. CURL is great…but it’s not very user friendly. Give HTTPie a shot! (httpie.io)
Direct download: coding-blocks-episode-164.mp3
Category: Software Development
-- posted at: 9:33pm EDT
|
|
Sun, 18 July 2021
It’s time to take a break, stretch our legs, grab a drink, and maybe even join in some interesting conversations around the water cooler as Michael goes off script, Joe is very confused, and Allen insists that we stay on script. The full show notes for this episode are available at https://www.codingblocks.net/episode163. Stop by, check it out, and join the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - We really appreciate the latest reviews, so thank you!
- iTunes: EveryNickIsTaken2858, Memnoch97
- Allen finished his latest ergonomic keyboard review: Moonlander Ergonomic Keyboard Long Term Review (YouTube)
- Sadly, the
.http files tip from episode 161 for JetBrains IDEs is only application for JetBrains’ Ultimate version. Meantime, at the watercooler…. GitHub Copilot (GitHub) - In short, it’s a VS Code Extension that leverages the OpenAI Codex, a product that translates natural language to code, in order to … wait for it … write code. It’s currently in limited preview.
What’s the value? - Is the code correct? Github says ~40-50% in some large scale test cases
- It works best with small, documented functions
- Does having the code written for you steer you towards solutions?
- Could this encourage similar bugs/security holes across multiple languages by people importing the same code?
- Is this any different from developers using the same common solutions from StackOverflow?
- Could it become a crutch for new developers?
- Better for certain kinds of code? (Boiler plate, common accessors, date math)
- Boiler Plate (like angular / controller vars)
- Common APIs (Twitter, Goodreads)
- Common Algorithms, Design Patterns
- Less Familiar Languages
- But is it useful? We’ll see!
Is this the future? - We see more low, no, and now co-code solutions all the time, is this where things are going?
- This probably won’t be “it”, but maybe we will see things like this more commonly – in any case it’s different, why not give it a shot?
Is it Ethical? - The “AI” or whatever has been trained on “billions of lines” of open-source code…but not strictly permissive licenses. This means a dev using this tool runs the risk of accidently including proprietary code
- Quake Engine Source Code Example (GPLv2) (Twitter)
- From an article in VentureBeat:
- 54 million public software repositories hosted on GitHub as of May 2020 (for Python) 179GB of unique Python files under 1MB in size. Some basic limitations on line and file length, sanitization: The final training dataset totaled 159GB.
- There is problem with bias, especially in more niche categories
- Is it ethical to use somebody else’s data to train an AI without their permission?
- Can it get you sued?
- Would your thoughts change if the data is public? License restricted?
- Would your thoughts change if the product/model were open-sourced?
Abstractions… how far is too far? - Services should communicate with datastores and services via APIs that hide the details, these provide for a nice indirection that allows for easier maintenance in the future
- Do you abstract at the service level or the feature level?
- Are ORMs a foregone conclusion?
- What about services that have a unique communication pattern, or assist with cross cutting concerns for things like microservices (We are looking at you hear Kafka!)
The 10 Best Practices for Remote Software Engineering - From article: The 10 Best Practices for Remote Software Engineering (ACM)
- Work on Things You Care About
- Define Goals for Yourself
- Define Productivity for Yourself
- Establish Routine and Environment
- Take Responsibility for Your Work
- Take Responsibility for Human Connection
- Practice Empathetic Review
- Have Self-Compassion
- Learn to Say Yes, No, and Not Anymore
- Choose Correct Communication Channels
Some of Michael’s (Linux/macOS) favorites from the article: - Abbreviate your directories with tab completion when changing directories, such as
cd /v/l/a, and assuming that that abbreviated path can uniquely identify something like, /var/logs/apache, tab completion will take care of the rest. - Use
nl to get a numbered list of some previous command’s output, such as ls -l | nl. ERRATUM: During the episode, Michael mentioned that the output would first list the total lines, but that just happened to be due to output from ll and was unrelated to the output from nl. - On macOS, you can use the
powermetrics command to gain access to all sorts of metrics related to the internals of your computer, such as the temperature at various sensors. - Use
!! to repeat the last command. This can be especially helpful when you want to do something like prepend/append the previous command, such as sudo !!. ERRATUM: Wow, Michael really got this one wrong during the episode. It doesn’t repeat the “last sudo command” nor does it leave the command in edit mode. Listen to Allen’s description. /8) - Awesome keyboard shortcuts:
CTRL+A takes you to the start of the line and CTRL+E takes you to the end.- No need to type
clear any longer as CTRL+L will clear your screen. CTRL+U deletes the content to the left of the cursor and CTRL+K deletes the content to the right of the cursor.- Made a mistake in while typing your command? Use
CTRL+SHIFT+- to undo what you last typed. - Using the
history command, you can see your previous commands and even limit it with a negative number, such as history -5 to see only the last five commands. Tip of the Week - Partial Diff is a VS Code extension that makes it easy to compare text. You can right click to compare files or even blocks of text in the same file, as well as in different files. (Visual Studio Marketplace)
- StackBlitz is an online development environment for full stack applications. (StackBlitz.com)
- Microcks, an open source Kubernetes native tool for API mocking and testing. (Microcks.io)
- Bridging the HTTP protocol to Apache Kafka (Strimzi.io)
- Difference Between grep, sed, and awk (Baeldung.com)
- As an alternative to the ruler hack mentioned in episode 161, there are several compact, travel ready laptop stands. (Amazon)
Direct download: coding-blocks-episode-163.mp3
Category: Software Development
-- posted at: 10:16pm EDT
|
|
Mon, 5 July 2021
We wrap up our replication discussion of Designing Data-Intensive Applications, this time discussing leaderless replication strategies and issues, while Allen missed his calling, Joe doesn’t read the gray boxes, and Michael lives in a future where we use apps. If you’re reading this via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode162. As Joe would say, check it out and join in on the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you for the latest review!
Check out the book! Single Leader to Multi-Leader to Leaderless - When you have leaders and followers, the leader is responsible for making sure the followers get operations in the correct order
- Dynamo brought the trend to the modern era (all are Dynamo inspired) but also…
- We talked about NoSQL Databases before:
- What exactly is NewSQL? https://en.wikipedia.org/wiki/NewSQL
- What if we just let every replica take writes? Couple ways to do this…
- You can write to several replicas
- You can use a coordinator node to pass on the writes
- But how do you keep these operations in order? You don’t!
- Thought exercise, how can you make sure operation order not matter?
- Couple ideas: No partial updates, increments, version numbers
Multiple Writes, Multiple Reads - What do you do if your client (or coordinator) try to write to multiple nodes…and some are down?
- Well, it’s an implementation detail, you can choose to enforce a “quorom”. Some number of nodes have to acknowledge the write.
- This ratio can be configurable, making it so some % is required for a write to be accepted
- What about nodes that are out of date?
- The trick to mitigating stale data…the replicas keep a version number, and you only use the latest data – potentially by querying multiple nodes at the same time for the requested data
- We’ve talked about logical clocks before, it’s a way of tracking time via observed changes…like the total number of changes to a collection/table…no timezone or nanosecond differences
How do you keep data in sync? - About those unavailable nodes…2 ways to fix them up
- Read Repair: When the client realizes it got stale data from one of the replicas, it can send the updated data (with the version number) back to that replica. Pretty cool! – works well for data that is read frequently
- Anti-Entropy: The nodes can also do similar background tasks, querying other replicas to see which are out of data – ordering not guaranteed!
- Voldemort: ONLY uses read repair – this could lead to loss of data if multiple replicas went down and the “new” data was never read from after being written
Quorums for reading and writing - Quick Reminder: We are still talking about 100% of the data on each replica
- 3 major numbers at play:
- Number of nodes
- Number of confirmed writes
- Number of reads required
- If you want to be safe, the nodes you write to and the ones you write too should include some overlap
- A common way to ensure that, keep the number of writes + the number of reads should be greater than the number of nodes
- Example: You have 10 nodes – if you use 5 for writing and 5 for reading…you may not have an overlap resulting in potentially stale data!
- Common approach – taken number of nodes (odd number) + 1, then divide that number by 2 and that’s the number of reader and writers you should have
- 9 Nodes – 5 writes and 5 reads – ensures non-stale data
- When using this approach, you can handle Nodes / 2 (rounded down) number of failed nodes
- How would you tweak the numbers for a write heavy workload?
- Typically, you write and read to ALL replicas, but you only need a successful response from these numbers
- What if you have a LOT of nodes?!?
- Note: there’s still room for problems here – author explicitly lists 5 types of edge cases, and one category of miscellaneous timing edge cases. All variations of readers and writers getting out of sync or things happen at the same timing
- If you really want to be safe, you need consensus (r = w = n) or transactions (that’s a whole other chapter)
- Note that if the number of required readers or writers doesn’t return an OK, then an error is returned from the operation
- Also worth considering is you don’t have to have overlap – having readers + writers < nodes means you could have stale data, but at possibly lower latencies and lower probabilities of error responses
Monitoring staleness - Single/Multi Leader lag is generally easy to monitor – you just query the leader and the replicas to see which operation they are on
- Leaderless databases don’t have guaranteed ordering so you can’t do it this way
- If the system only uses read repair (where the data is fixed up by clients only as it is read) then you can have data that is ancient
- It’s hard to give a good algorithm description here because so much relies on the implementation details
And when things don’t work? - Multi-writes and multi-reads are great when a small % of nodes or down, or slow
- What if that % is higher?
- Return an error when we can’t get quorum?
- Accept writes and catch the unavailable nodes back up later?
- If you choose to continue operating, we call it “sloppy quorum” – when you allow reads or writes from replicas that aren’t the “home” nodes – the likened it to you got locked out of your house and you ask your neighbor if you can stay at their place for the night
- This increases (write) availability, at the cost of consistency
- Technically it’s not a quorum at all, but it’s the best we can do in that situation if you really care about availability – the data is stored somewhere just not where it’d normally be stored
Detecting Concurrent Writes - What do you get when you write the same key at the same time with different values?
- Remember, we’re talking about logical clocks here so imagine that 2 clients both write version #17 to two different nodes
- This may sound unlikely, but when you realize we’re talking logical clocks, and systems that can operate at reduced capacity…it happens
- What can we do about it?
- Last write wins: But which one is considered last? Remember, how we catch up? (Readers fix or leaders communicate) …either way, the data will eventually become consistent but we can’t say which one will win…just that one will eventually take over
- Note: We can take something else into account here, like clock time…but no perfect answer
- LWW is good when your data is immutable, like logs – Cassandra recommends using a UUID as a key for each write operation
- Happens-Before Relationship – (Riak has CfRDT that bundle a version vector to help with this)
This “happens-before” relationship and concurrency - How do we know whether the operations are concurrent or not?
Basically if neither operation knows about the other, then they are concurrent… - Three possible states if you have writes A and B
- A happened before B
- B happened before A
- A and B happened concurrently
- When there is a happens before, then you take the later value
- When they are concurrent, then you have to figure out how to resolve the conflicts
- Merging concurrently written values
- Last write wins?
- Union the data?
- No good answer
Version vectors - The collection of version numbers from all replicas is called a version vector
- Riak uses dotted version vectors – the version vectors are sent back to the clients when values are read, and need to be sent back to the db when the value is written back
- Doing this allows the db to understand if the write was an overwrite or concurrent
- This also allows applications to merge siblings by reading from one replica and write to another without losing data if the siblings are merged correctly
Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
- Designing Data-Intensive Applications – Data Models: Relational vs Document (episode 123)
- NewSQL (Wikipedia)
- Do not allow Jeff Bezos to return to Earth (Change.org)
- Man Invests $20 in Obscure Cryptocurrency, Becomes Trillionaire Overnight, at Least Temporarily (Newsweek)
- Quantifying Eventual Consistency with PBS (Bailis.org)
- Riak Distributed Data Types (Riak.com)
Tip of the Week - A GitHub repo for a list of “falsehoods”: common things that people believe but aren’t true, but targeted at the kinds of assumptions that programmers might make when they are working on domains they are less familiar with. (GitHub)
- The Linux
at command lets you easily schedule commands to run in the future. It’s really user friendly so you can be lazy with how you specify the command, for example echo "command_to_be_run" | at 09:00 or at 09:00 -f /path/to/some/executable (linuxize.com) - You can try Kotlin online at play.kotlinlang.org, it’s an online editor with links to lots of examples. (play.kotlinlan.org)
- The Docker
COPY cmd will need to be run if there are changes to files that are being copied. You can use a .dockerignore to skip files that you don’t care about to trim down on unnecessary work and build times. (doc.docker.com).
Direct download: coding-blocks-episode-162.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 20 June 2021
We continue our discussion of Designing Data-Intensive Applications, this time focusing on multi-leader replication, while Joe is seriously tired, and Allen is on to Michael’s shenanigans. For anyone reading this via their podcast player, this episode’s show notes can be at https://www.codingblocks.net/episode161, where you can join the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you very much for the new reviews:
- iTunes: GubleReid, tbednarick, JJHinAsia, katie_crossing
- Audible: Anonymous User, Anonymous User … hmm
When One Leader Just Won’t Do Talking about Multi-Leader Replication Replication Recap and Latency - When you’re talking about single or multi-leader replication, remember all writes go through leaders
- If your application is read heavy, then you can add followers to increase your scalability
- That doesn’t work well with sync writes..the more followers, the higher the latency
- The more nodes the more likely there will be a problem with one or more
- The upside is that your data is consistent
- The problem is if you allow async writes, then your data can be stale. Potentially very stale (it does dial up the availability and perhaps performance)
- You have to design your app knowing that followers will eventually catch up – “eventual consistency“
- “Eventual” is purposely vague – could be a few seconds, could be an hour. There is no guarantee.
- Some common use cases make this particularly bad, like a user updating some information…they often expect to see that change afterwards
- There are a couple techniques that can help with this problem
Techniques for mitigation replication lag - Read You Writes Consistency refers to an attempt to read significant data from leader or in sync replicas by the user that submitted the data
- In general this ensures that the user who wrote the data will get the same data back – other users may get stale version of the data
- But how can you do that?
- Read important data from a leader if a change has been made OR if the data is known to only be changeable by that particular user (user profile)
- Read from a leader/In Sync Replica for some period of time after a change
- Client can keep a timestamp of it’s most recent write, then only allow reads from a replica that has that timestamp (logical clocks keep problems with clock synchronization at bay here)
- But…what if the user is using multiple devices?
- Centralize MetaData (1 leader to read from for everything)
- You make sure to route all devices for a user the same way
- Monotonic Reads: a guarantee of sorts that ensures you won’t see data moving backwards in time. One way to do this – keep a timestamp of the most recent read data, discard any reads older than that…you may get errors, but you won’t see data older than you’ve already seen.
- Another possibility – ensure that the reads are always coming from the same replica
- Consistent Prefix Reads: Think about causal data…an order is placed, and then the order is shipped…but what if we had writes going to more than one spot and you query the order is shipped..but nothing was placed? (We didn’t have this problem with a Single Replica)
- We’ll talk more about this problem in a future episode, but the short answer is to make sure that causal data gets sent to the same “partition”
Replication isn’t as easy as it sounds, is it? Multi-Leader Rep…lication Single leader replication had some problems. There was a single point of failure for writes, and it could take time to figure out the new leader. Should the old leader come back then…we have a problem. Multi-Leader replication… - Allows more than one node to receive writes
- Most things behave just like single-leader replication
- Each leader acts as followers to other leaders
When to use Multi-Leader Replication - Many database systems that support single-leader replication can be taken a step further to make them mulit-leader. Usually. you don’t want to have multiple leaders within the same datacenter because the complexity outweighs the benefits.
- When you have multiple leaders you would typically have a leader in each datacenter
- An interesting approach is for each datacenter to have a leader and followers…similar to the single leader. However, each leader would be followers to the other datacenter leaders
- Sort of a chained single-leader replication setup
Comparing Single-Leader vs Multi-Leader Replication Performance – because writes can occur in each datacenter without having to go through a single datacenter, latency can be greatly reduced in multi-leader - The synchronization of that data across datacenters can happen asynchronously making the system feel faster overall
- Fault tolerance – in single-leader, everything is on pause while a new leader is elected
- In multi-leader, the other datacenters can continue taking writes and will catch back up when a new leader is selected in the datacenter where the failure occurred
Network problems - Usually a multi-leader replication is more capable of handling network issues as there are multiple data centers handling the writes – therefore a major issue in one datacenter doesn’t cause everything to take a dive
So it’s clear right? Multi-leader all the things? Hint: No! Problems with Multi-Leader Replication - Changes to the same data concurrently in multiple datacenters has to be resolved – conflict resolution – to be discussed later
- External tools for popular databases:
- Additional problems – multi-leader is typically bolted on after the fact
- Auto-incrementing keys, triggers, constraints can all be problematic
- Those reasons alone are reasons why it’s usually recommended to avoid multi-leader replication
Clients with offline operation - Multi-leader makes sense when there are applications that need to continue to work even when they’re not connected to the network
- Calendars were an example given – you can make changes locally and when your app is online again it syncs back up with the remote databases
- Each application’s local database acts as a leader
- CouchDB was designed to handle this type of setup
Collaborative editing Google Docs, Etherpad, Changes are saved to the “local” version that’s open per user, then changes are synced to a central server and pushed out to other users of the document Conflict resolution - One of the problems with multi-leader writes is there will come times when there will be conflicting writes when two leaders write to the same column in a row with different values
- How do you solve this?
- If you can automate, you should because you don’t want to be putting this together by hand
- Make one leader more important than the others
- Make certain writes always go through the same data centers
- It’s not easy – Amazon was brought up as having problems with this as well
Multi-Leader Replication Toplogogies - A replication topology describes how replicas communicate
- Two leaders is easy
- Some popular topologies:
- Ring: Each leader reads from “right”, writes to the “left”
- All to All: Very Chatty, especially as you add more and more nodes
- Star: 1 special leader that all other leaders read from
- Depending on the topology, a write may need to pass through several nodes before it reaches all replicas
- How do you prevent infinite loops? Tagging is a popular strategy
- If you have a star or circular topology, then a single node failure can break the flow
- All to all is safest, but some networks are faster than others that can cause problems with “overrun” – a dependent change can get recorded before the previous
- You can mitigate this by keeping “version vectors”, kind of logical clock you can use to keep from getting too far ahead
 Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
- Amazon Yesterday Shipping (YouTube)
- Uber engineering blog (eng.uber.com)
Tip of the Week - .http files are a convenient way of running web requests. The magic is in the IDE support. IntelliJ has it built in and VSCode has an extension. (IntelliJ Products, VSCode Extension)
 - iTerm2 is a macOS Terminal Replacement that adds some really nice features. Some of our Outlaw’s favorite short-cuts: (iTerm2, Features and Screenshots)
- CMD+D to create a new panel (split vertically)
- CMD+SHIFT+D to create a new panel (split horizontally)
- CMD+Option+arrow keys to navigate between panes
- CMD+Number to navigate between tabs
- Ruler Hack – An architect scale ruler is a great way to prevent heat build up on your laptop by giving the hottest parts of the laptop some air to breathe. (Amazon)
- Fizz Buzz Enterprise Edition is a funny, and sadly reminiscent, way of doing FizzBuzz that incorporates all the buzzwords and most abused design patterns that you see in enterprise Code. (GitHub)
- From our friend Jamie Taylor (of DotNet Core Podcast, Tabs ‘n Spaces, and Waffling Taylors), mkcert is a “zero-config” way to easily generate self-signed certificates that your computer will trust. Great for dev! (GitHub)
- Find out more about Jamie on these great shows…
Direct download: coding-blocks-episode-161.mp3
Category: Software Development
-- posted at: 8:55pm EDT
|
|
Sun, 6 June 2021
We dive back into Designing Data-Intensive Applications to learn more about replication while Michael thinks cluster is a three syllable word, Allen doesn’t understand how we roll, and Joe isn’t even paying attention. For those that like to read these show notes via their podcast player, we like to include a handy link to get to the full version of these notes so that you can participate in the conversation at https://www.codingblocks.net/episode160. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
- Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you to everyone that left us a new review:
- Audible: Ashfisch, Anonymous User (aka András)
The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair Douglas Adams Douglas Adams In this episode, we are discussing Data Replication, from chapter 5 of “Designing Data-Intensive Applications”. Replication in Distributed Systems - When we talk about replication, we are talking about keeping copies of the same data on multiple machines connected by a network
- For this episode, we’re talking about data small enough that it can fit on a single machine
- Why would you want to replicate data?
- Keeping data close to where it’s used
- Increase availability
- Increase throughput by allowing more access to the data
- Data that doesn’t change is easy, you just copy it
- 3 popular algorithms
- Single Leader
- Multi-Leader
- Leaderless
- Well established (1970’s!) algorithms for dealing with syncing data, but a lot data applications haven’t needed replication so the practical applications are still evolving
- Cluster group of computers that make up our data system
- Node each computer in the cluster (whether it has data or not)
- Replica each node that has a copy of the database
- Every write to the database needs to be copied to every replica
- The most common approach is “leader based replication”, two of the algorithms we mentioned apply
- One of the nodes is designated as the “leader”, all writes must go to the leader
- The leader writes the data locally, then sends to data to it’s followers via a “replication log” or “change stream”
- The followers tail this log and apply the changes in the same order as the leader
- Reads can be made from any of the replicas
- This is a common feature of many databases, Postgres, Mongo, it’s common for queues and some file systems as well
Synchronous vs Asynchronous Writes - How does a distributed system determine that a write is complete?
- The system could hang on till all replicas are updated, favoring consistency…this is slow, potentially a big problem if one of the replicas is unavailable
- The system could confirm receipt to the writer immediately, trusting that replicas will eventually keep up… this favors availability, but your chances for incorrectness increase
- You could do a hybrid, wait for x replicas to confirm and call it a quorum
- All of this is related to the CAP theorem…you get at most two: Consistency, Availability and Partition Tolerance
- The book mentions “chain replication” and other variants, but those are still rare
Steps for Adding New Followers - Take a consistent snapshot of the leader at some point in time (most db can do this without any sort of lock)
- Copy the snapshot to the new follower
- The follower connects to the leader and requests all changes since the back-up
- When the follower is fully caught up, the process is complete
Handling Outages - Nodes can go down at any given time
- What happens if a non-leader goes down?
- What does your db care about? (Available or Consistency)
- Often Configurable
- When the replica becomes available again, it can use the same “catch-up” mechanism we described before when we add a new follower
- What happens if you lose the leader?
- Failover: One of the replicas needs to be promoted, clients need to reconfigure for this new leader
- Failover can be manual or automatic
Rough Steps for Failover - Determining that the leader has failed (trickier than it sounds! how can a replica know if the leader is down, or if it’s a network partition?)
- Choosing a new leader (election algorithms determine the best candidate, which is tricky with multiple nodes, separate systems like Apache Zookeeper)
- Reconfigure: clients need to be updated (you’ll sometimes see things like “bootstrap” services or zookeeper that are responsible for pointing to the “real” leader…think about what this means for client libraries…fire and forget? try/catch?
Failover is Hard! - How long do you wait to declare a leader dead?
- What if the leader comes back? What if it still thinks it’s leader? Has data the others didn’t know about? Discard those writes?
- Split brain – two replicas think they are leaders…imagine this with auto-incrementing keys… Which one do you shut down? What if both shut down?
- There are solutions to these problems…but they are complex and are a large source of problems
- Node failures, unreliable networks, tradeoffs around consistency, durability, availability, latency are fundamental problems with distributed systems
Implementation of Replication Logs - 3 main strategies for replication, all based around followers replaying the same changes
Statement-Based Replication - Leader logs every Insert, Update, Delete command, and followers execute them
- Problems
- Statements like NOW() or RAND() can be different
- Auto-increments, triggers depend on existing things happen in the exact order..but db are multi-threaded, what about multi-step transactions?
- What about LSM databases that do things with delete/compaction phases?
- You can work around these, but it’s messy – this approach is no longer popular
- Example, MySQL used to do it
Write Ahead Log Shipping - LSM and B-Tree databases keep an append only WAL containing all writes
- Similar to statement-based, but more low level…contains details on which bytes change to which disk blocks
- Tightly coupled to the storage engine, this can mean upgrades require downtime
- Examples: Postgres, Oracle
Row Based Log Replication - Decouples replication from the storage engine
- Similar to WAL, but a litle higher level – updates contain what changed, deletes similar to a “tombstone”
- Also known as Change Data Capture
- Often seen as an optional configuration (Sql Server, for example)
- Examples: (New MySQL/binlog)
Trigger-Based Replication - Application based replication, for example an app can ask for a backup on demand
- Doesn’t keep replicas in sync, but can be useful
Resources We Like Tip of the Week - A collection of CSS generators for grid, gradients, shadows, color palettes etc. from Smashing Magazine.
- Learn This One Weird ? Trick To Debug CSS (freecodecamp.org)
- Use
tree to see a visualization of a directory structure from the command line. Install it in Ubuntu via apt install tree. (manpages.ubuntu.com) - Initialize a variable in Kotlin with a try-catch expression, like
val myvar: String = try { ... } catch { ... }. (Stack Overflow) - Manage secrets and protect sensitive data (and more with Hashicorp Vault. (Hashicorp)
Direct download: coding-blocks-episode-160.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 23 May 2021
We couldn’t decide if we wanted to gather around the water cooler or talk about some cool APIs, so we opted to do both, while Joe promises there’s a W in his name, Allen doesn’t want to say graph, and Michael isn’t calling out applets. For all our listeners that read this via their podcast player, this episode’s show notes can be found at https://www.codingblocks.net/episode159, where you can join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
- ConfigCat – The feature flag and config management service that lets you turn features ON after deployment or target specific groups of users with different features.
Survey Says News - Thank you all for the latest reviews:
- iTunes: Lp1876
- Audible: Jon, Lee
Overheard around the Water Cooler - Where do you draw the line before you use a hammer to solve every problem?
- When is it worth bringing in another technology?
- Can you have too many tools?
APIs of Interest Joe’s Picks - Video game related APIs
- RAWG – The Biggest Video Game Database on RAWG – Video Game Discovery Service (rawg.io)
- PS: Your favorite video games might have an API:
- Satellite imagery related APIs
- Get into the affiliate game
Allen’s Picks Michael’s Picks - Alpha Vantage – Free Stock APIs (alphavantage.co)
- Why so serious?
- icanhazdadjoke – The largest selection of dad jokes on the Internet (icanhazdadjoke.com)
- Channel your inner Stuart Smalley with affirmations. (affirmations.dev)
- HTTP Cats – The ultimate source for HTTP status code images. (http.cat)
- Relevant call backs from episode 127:
- Random User Generator – A free, open-source API for generating random user data. (randomuser.me)
- Remember the API – Programmer gifts and merchandise (remembertheapi.com)
Resources We Like - ReDoc – OpenAPI/Swagger-generated API Reference Documentation (GitHub)
- Google Earth – The world’s most detailed globe. (google.com/earth)
- Google Sky – Traveling to the stars has never been easier. (google.com/sky)
- apitracker.io – Discover the best APIs and SaaS products to integrate with. (apitracker.io)
- ProgrammableWeb – The leading source of news and information about Internet-based APIs.(ProgrammableWeb.com)
- NASA APIs – NASA data, including imagery, accessible to developers. (api.nasa.gov)
- RapidAPI – The Next-Generation API Platform (rapidapi.com)
- Stuart Smalley (Wikipedia)
- Al Franken (Wikipedia)
- Muzzle – A simple Mac app to silence embarrassing notifications while screensharing. (MuzzleApp.com)
Tip of the Week - Not sure what project to do? Google for an API or check out RapidAPI for a consistent way to farm ideas:
- Press F12 in Firefox, Chrome, or Edge, then go to the Elements tab (or Inspector in Firefox) to start hacking away at the DOM for immediate prototyping.
- All things K9s
- Getting Started with K9s – A Love Letter to K9s
- Use K9s to easily monitor your Kubernetes cluster
- Not only does K9s support skins and themes, but supports *cluster specific* skins (k9scli.io)
- If you like xkcd, Monkey User is for you!
- xkcd – A webcomic of romance, sarcasm, math, and language. (xkcd.com)
- Monkey User – Created out of a desire to bring joy to people working in IT. (MonkeyUser.com)
- Remap Windows Terminal to use CTRL+D, another keyboard customizations. (docs.microsoft.com)
- PostgreSQL and Foreign Data (postgresql.org)
- Cheerio – Fast, flexible & lean implementation of core jQuery designed specifically for the server. (npmjs.com)
- JetBrains MPS (Meta Programming System) – Create your own domain-specific language (JetBrains)
- Case study – Domain-specific languages to implement Dutch tax legislation and process changes of that legislation. (JetBrains)
Direct download: coding-blocks-episode-159.mp3
Category: Software Development
-- posted at: 10:14pm EDT
|
|
Sun, 9 May 2021
We talk about the various ways we can get paid with code while Michael failed the Costco test, Allen doesn’t understand multiple choice questions, and Joe has a familiar pen name. This episode’s show notes can be found at https://www.codingblocks.net/episode158, where you can join the conversation, for those reading this via their podcast player. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Thank you all for the latest reviews:
- iTunes: PriestRabbitWalkIntoBloodBank, Sock-puppet Sophist sez, Rogspug, DhokeDev, Dan110024
- Audible: Aiden
Show Me the Money Active Income - Active income is income earned by exchanging time for money. This typically includes salary and hourly employment, as well as contracting.
- Some types of active income blur the lines.
- Way to find active income can include job sites like Stack Overflow Jobs, Indeed, Upwork, etc.
- Government grants and jobs are out there as well.
- Active income is typically has some ceiling, such as your time.
Passive Income - Passive income is income earned on an investment, any kind of investment, such as stock markets, affiliate networks, content sales for things like books, music, courses, etc.
- The work you do for the passive income can blur lines, especially when that work is promotion.
- Passive income is generally not tied to your time.
Passive Income Options - Create a SaaS platform to keep people coming back. Don’t let the term SaaS scare you off. This can be something smaller like a regex validator.
- Affiliate links are a great example of passive income because you need to invest the time once to create the link.
- Ads and sponsors: typically, the more targeted the audience is for the ad, the more the ad is worth.
- Donations via services like Ko-fi, Patreon, and PayPal.
- Apps, plugins, website templates/themes
- Create content, such as books, courses, videos, etc. Self-publishing can have a bigger reward and offer more freedom, but doesn’t come with the built-in audience and marketing team that a publisher can offer.
- Arbitrage between markets.
- Grow an audience, be it on YouTube, Twitch, podcasting, blogging, etc.
Things to Consider - What’s the up-front effort and/or investment?
- How much maintenance can you afford?
- How much will it cost you?
- Who gets hurt if you choose to quit?
- What can you realistically keep up with?
- What are the legal and tax liabilities?
Resources We Like Tip of the Week - Google developer documentation style guide: Word list (developers.google.com)
- In Windows Terminal, use
CTRL+SHIFT+W to close a tab or the window. - The GitHub CLI manual (cli.github.com)
- Use
gh pr create --fill to create a pull request using your last commit message as the title and body of the PR. - We’ve discussed the GitHub CLI in episode 142 and episode 155.
- How to get a dependency tree for an artifact? (Stack Overflow)
- xltrail – Version control for Excel workbooks (xltrail.com)
- Spring Initializr (start.spring.io)
- You can leverage the same thing in IntelliJ with Spring.
Direct download: coding-blocks-episode-158.mp3
Category: Software Development
-- posted at: 11:16pm EDT
|
|
Sun, 25 April 2021
We discuss all things APIs: what makes them great, what makes them bad, and what we might like to see in them while Michael plays a lawyer on channel 46, Allen doesn’t know his favorite part of the show, and Joe definitely pays attention to the tips of the week. For those reading this episode’s show notes via their podcast player, you can find this episode’s show notes at https://www.codingblocks.net/episode157 where you can be a part of the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Big thanks to everyone that left us a new review:
- iTunes: hhskakeidmd
- Audible: Colum Ferry
All About APIs What are APIs? - API stands for application programming interface and is a formal way for applications to speak to each other.
- An API defines requests that you can make, what you need to provide, and what you get back.
- If you do any googling, you’ll see that articles are overwhelmingly focused on Web APIs, particularly REST, but that is far from the only type. Others include:
- All libraries,
- All frameworks,
- System Calls, i.e.: Windows API,
- Remote API (aka RPC – remote procedure call),
- Web related standards such as SOAP, REST, HATEOAS, or GraphQL, and
- Domain Specific Languages (SQL for example)
- The formal definition of APIs, who own them, and what can be done with them is complicated à la Google LLC v. Oracle America, Inc.
- Different types of API have their own set of common problems and best practices
- Common REST issues:
- Authentication,
- Rate limiting,
- Asynchronous operations,
- Filtering,
- Sorting,
- Pagination,
- Caching, and
- Error handling.
- Game libraries:
- Heavy emphasis on inheritance and “hidden” systems to cut down on complexity.
- Libraries for service providers
- Support multiple languages and paradigms (documentation, versioning, rolling out new features, supporting different languages and frameworks)
- OData provides a set of standards for building and consuming REST API’s.
General tips for writing great APIs - Make them easy to work with.
- Make them difficult to misuse (good documentation goes a long way).
- Be consistent in the use of terms, input/output types, error messages, etc.
- Simplicity: there’s one way to do things. Introduce abstractions for common actions.
- Service evolution, i.e. including the version number as part of your API call enforces good versioning habits.
- Documentation, documentation, documentation, with enough detail that’s good to ramp up from getting started to in depth detail.
- Platform Independence: try to stay away from specifics of the platforms you expect to deal with.
Why is REST taking over the term API? - REST is crazy popular in web development and it’s really tough to do anything without it.
- It’s simple. Well, not really if you consider the 43 things you need to think about.
- Some things about REST are great by design, such as:
- By using it, you only have one protocol to support,
- It’s verb oriented (commonly used verbs include
GET, POST, PUT, PATCH, and DELETE), and - It’s based on open standards.
- Some things about REST are great by convention, such as:
- Noun orientation like resources and identifiers,
- Human readable I/O,
- Stateless requests, and
- HATEOAS provides a methodology to decouple the client and the server.
Maybe we can steal some ideas from REST - Organize the API around resources, like
/orders + verbs instead of /create-order. - Note that nouns can be complex, an order can be complex … products, addresses, history, etc.
- Collections are their own resources (i.e.
/orders could return more than 1). - Consistent naming conventions makes for easy discovery.
- Microsoft recommends plural nouns in most cases, but their skewing heavily towards REST, because REST already has a mechanism for behaviors with their verbs. For example
/orders and /orders/123. - You can drill in further and further when you orient towards nouns like
/orders/123/status. - The general guidance is to return resource identifiers rather than whole objects for complex nouns. In the order example, it’s better to return a customer ID associated with the whole order.
- Avoid introducing dependencies between the API and the underlying data sources or storage, the interface is meant to abstract those details!
- Verb orientation is okay in some, very action based instances, such as a calculator API.
Resources We Like Tip of the Week - Docker Desktop: WSL 2 Best practices (Docker)
- Experiencing déjà vu? That’s because we talked about this during episode 156.
- With Minikube, you can easily configure the amount of CPU and RAM each time you start it.
- Listen to American Scandal. A great podcast with amazing production quality. (Wondery)
- If you have a license for DataGrip and use other JetBrains IDEs, once you add a data source, the IDE will recognize strings that are SQL in your code, be they Java, JS, Python, etc., and give syntax highlighting and autocomplete.
- Also, you can set the connection to a DB in DataGrip as read only under the options. This will give you a warning message if you try a write operation even if your credentials have write permissions.
- API Blueprint. A powerful high-level API description language for web APIs. (apiblueprint.org)
- Apache Superset – A modern data exploration and visualization platform. (Apache)
- Use console.log() like a pro. (markodenic.com)
- Turns out we did discuss something similar to this back in episode 44.
- Telerik Fiddler – A must have web debugging tool for your web APIs. (Telerik)
- New Docker Build secret information (docs.docker.com)
Direct download: coding-blocks-episode-157.mp3
Category: Software Development
-- posted at: 8:51pm EDT
|
|
Sun, 11 April 2021
We discuss the parts of the scrum process that we’re supposed to pay attention to while Allen pronounces the m, Michael doesn’t, and Joe skips the word altogether. If you’re reading this episode’s show notes via your podcast player, just know that you can find this episode’s show notes at https://www.codingblocks.net/episode156. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Hey, we finally updated the Resources page. It only took a couple years.
- Apparently we don’t understand the purpose of the scrum during rugby. (Wikipedia)
Standup Time User Stories - A user story is a detailed, valuable chunk of work that can be completed in a sprint.\
- Use the INVEST mnemonic created by Bill Wake:
- I = Independent – the story should be able to be completed without any dependencies on another story
- N = Negotiable – the story isn’t set in stone – it should have the ability to be modified if needed
- V = Valuable – the story must deliver value to the stakeholder
- E = Estimable – you must be able to estimate the story
- S = Small – you should be able to estimate within a reasonable amount of accuracy and completed within a single sprint
- T = Testable – the story must have criteria that allow it to be testable
Stories Should be Written in a Format Very Much Like… “As a _____, I want _____ so that _____.”, like
“As a user, I want MFA in the user profile so I can securely log into my account” for a functional story, or
“As a developer, I want to update our version of Kubernetes so we have better system metrics” for a nonfunctional story. Stories Must have Acceptance Criteria - Each story has it’s own UNIQUE acceptance criteria.
- For the MFA story, the acceptance criteria might be:\
- Token is captured and saved.
- Verification of code completed successfully.
- Login works with new MFA.
- The acceptance criteria defines what “done” actually means for the story.
Set up Team Boundaries - Define “done”.
- Same requirement for ALL stories:
- Must be tested in QA environment,
- Must have test coverage for new methods.
- Backlog prioritization or “grooming”.
- Must constantly be ordered by value, typically by the project owner.
- Define sprint cadence
- Usually 1-4 weeks in length, 2-3 is probably best.
- Two weeks seems to be what most choose simply because it sort of forces a bit of urgency on you.
Estimates - Actual estimation, “how many hours will a task take?”
- Relative estimation, “I think this task will take 2x as long as this other ticket.”
- SCRUM uses both, user stories are compared to each other in relative fashion.
- By doing it this way, it lets external stakeholders know that it’s an estimate and not a commitment.
- Story points are used to convey relative sizes.
- Estimation is supposed to be lightweight and fast.
Roadmap and Release Plan - The roadmap shows when themes will be worked on during the timeframe.\
- You should be able to have a calendar and map your themes across that calendar and in an order that makes sense for getting a functional system.
- Just because you should have completed, functional components at the end of each sprint, based on the user stories, that doesn’t mean you’re releasing that feature to your customer. It may take several sprints before you’ve completed a releasable feature.
- It will take several sprints to find out what a team’s stabilized velocity is, meaning that the team will be able to decently predict how many story points they can complete in a given sprint.
Filling up the Sprint - Decide how many points you’ll have for a sprint.
- Determine how many sprints before you can release the MVP.
- Fill up the sprints as full as possible in priority order UNLESS the next priority story would overflow the sprint.
- Simple example, let’s say your sprint will have 10 points and you have the following stories:
Story A – 3 points
Story B – 5 points
Story C – 8 points
Story D – 2 points - Your sprints might look like:
Sprint 1 – A (3) B(5), D(2) = 10 points
Sprint 2 – C (8) - Story C got bumped to Sprint 2 because the goal is to maximize the amount of work that can be completed in a given sprint in priority order, as much as possible.
- The roadmap is an estimate of when the team will complete the stories and should be updated at the end of each sprint. In other words, the roadmap is a living document.
Sprint Planning - This is done at the beginning of each sprint.
- Attendees – all developers, scrum master, project owner.
- Project owner should have already prioritized the stories in the backlog.
- The goal of the planning meeting is to ensure all involved understand the stories and acceptance criteria.
- Also make sure the overarching definition of “done” is posted as a reminder.
- Absolutely plan for a Q&A session.
- Crucial to make sure any misunderstandings of the stories are cleared here.
- Next the stories are broken down into specific tasks. These tasks are given actual estimates in time.
- Once this is completed, you need to verify that the team has enough capacity to complete the tasks and stories in the sprint.
- In general, each team member can only complete 6 hours of actual work per day on average.
- Each person is then asked whether they commit to the work in the sprint.
- Must give a “yes” or “no” and why.
- If someone can’t commit with good reason, the the project owner and team need to work together to modify the sprint so that everyone can commit. This is a highly collaborative part of scrum planning.
Stakeholder Feedback - Information radiators are used to post whatever you think will help inform the stakeholders of the progress, be it a task board or burn down chart.
Task board - Lists stories committed to in the sprint.
- Shows the status of any current tasks.
- Lists which tasks have been completed.
- Swimlanes are typically how these are depicted with lanes like: Story, Not Started, In Progress, Completed.
Sprint burndown chart - Shows ongoing status of how you’re doing with completing the sprint.
Daily Standup - The purpose of the standup is the three C’s:\
- Collaboration,
- Communication, and
- Cadence.
- The entire team must join: developers, project owner, QA, scrum master.
- Should occur at the same time each day.
- Each status should just be an overview and light on the details.
- Tasks are moved to a new state during the standup, such as from Not Started to In Progress.
- Stakeholders can come to the scrum but should hold questions until the end.
- Cannot go over 15 minutes. It can be shorter, but should not be longer.
- Each person should answer three questions:
- What did you do yesterday?,
- What are you doing today?, and
- Are there any blockers?
- If you see someone hasn’t made progress in several days, this is a great opportunity to ask to help. This is part of keeping the team members accountable for progressing.
- Blockers are brought up during the meeting as anyone on the team needs to try and step in to help. If the issue hasn’t been resolved by the next day, then it’s the responsibility of the scrum master to try and resolve it, and escalate it further up the chain after that, such as to the project owner and so on, each consecutive day.
- Again, very important, this is just the formal way to keep the entire team aware of the progress. People should be communicating throughout the day to complete whatever tasks they’re working on.
Backlog Refinement - The backlog is constantly changing as the business requirements change.
- It is the job of the project owner to be in constant communication with the stakeholders to ensure the backlog represents the most important needs of the business and making sure the stories are prioritized in value order.
- Stories are constantly being modified, added, or removed.
- Around the midpoint of the sprint, there is usually a 30-60 minute “backlog refinement session” where the team comes together to discuss the changes in the backlog.
- These new stories can only be added to future sprints.
- The current sprint commitment cannot be changed once the sprint begins.
- The importance of this mid-sprint session is the team can ask clarifying questions and will be better prepared for the upcoming sprint planning.
- This helps the project owner know when there are gaps in the requirements and helps to improve the stories.
Marking a Story Done - The project owner has the final say making sure all the acceptance criteria has been met.
- There could be another meeting called the “sprint review” where the entire team meets to get signoff on the completed stories.
- Anything not accepted as done gets reviewed, prioritized, and moved out to another sprint.
- This can happen when a team discovers new information about a story while working on it during a sprint.
- The team agrees on what was completed and what can be demonstrated to the stakeholders.
The Demo - This is a direct communication between the team and the stakeholders and receive feedback.
- This may result in new stories.
- Stakeholders may not even want the new feature and that’s OK. It’s better to find out early rather than sinking more time into building something not needed or wanted.
- This is a great opportunity to build a relationship between the team members and the stakeholders.
- This demo also shows the overall progress towards the final goal.
- May not be able to demo at the end of every sprint, but you want to do it as often as possible.
Team Retrospective - Focus is on team performance, not the product and is facilitated by the scrum master.
- This is a closed door session and must be a safe environment for discussion.
- Only dedicated team members present and the team norms must be observed
- You want an open dialogue/
- What worked well? Focus on good team collaboration.
- What did not work well? Focus on what you can actually change.
- What can be improved?
- Put items into an improvement backlog
- Focus on one or two items in the next sprint
- Start with team successes first!
Resources We Like Tip of the Week - Test your YAML with the Ansible Template Tester (ansible.sivel.net)
- Hellscape by Andromida (Spotify, YouTube)
- Use
ALT+LEFT CLICK in Windows Terminal to open a new terminal in split screen mode. - Learn how to tie the correct knot for every situation! (animatedknots.com)
- Apply zoom levels to each tab independently of other tabs of the same website with Per Tab Zoom. (Chrome web store)
- Nearly every page on GitHub has a keyboard shortcut to perform actions faster. Learn them! (GitHub)
- Speaking of shortcuts, here’s a couple for Visual Studio Code:
- Use
CTRL+P (or CMD+P on a Mac) to find a file by name or path. - List (and search) all available commands with
CTRL+SHIFT+P (or CMD+SHIFT+P on a … you know). - Use
CTRL+K M (CMD+K M) to change the current document’s language mode. - Access your WSL2 filesystem from Windows using special network share: like
\\wsl$\ubuntu_instance_name\home\your_username\some_path - Docker Desktop: WSL 2 Best practices (Docker)
Direct download: coding-blocks-episode-156.mp3
Category: Software Development
-- posted at: 10:26pm EDT
|
|
Sun, 28 March 2021
During today’s standup, we focus on learning all about Scrum as Joe is back (!!!), Allen has to dial the operator and ask to be connected to the Internet, and Michael reminds us why Blockbuster failed. If you didn’t know and you’re reading these show notes via your podcast player, you can find this episode’s show notes in their original digital glory at https://www.codingblocks.net/episode155 where you can also jump in the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Thank you all for the reviews:
- iTunes: DareOsewa, Miggybby, MHDev, davehadley, GrandMasterJR, Csmith49, ForTheHorde&Tacos, A-Fi
- Audible: Joshua, Alex
Do You Even Scrum? Why Do We Call it Scrum Anyways? Comes from the game of Rugby. A scrummage is when a team huddles after a foul to figure out their next set of plays and readjust their strategy. Why is Scrum the Hot Thing? - Remember waterfall?
- Plan and create documentation for a year up front, only to build a product with rigid requirements for the next year. By the time you deliver, it may not even be the right product any longer.
- Waterfall works for things that have very repeatable steps, such as things like planning the completion of a building.
- It doesn’t work great for things that require more experimentation and discovery.
- Project managers saw the flaw in planning for the complete “game” rather than planning to achieve each milestone and tackle the hurdles as they show up along the way.
- Scrum breaks the deliverables and milestones into smaller pieces to deliver.
The Core Tenants of Scrum - Having business partners and stakeholders work with the development of the software throughout the project,
- Measure success using completed software throughout the project, and
- Allow teams to self-organize.
Scrum Wants You to Fail Fast - Failure is ok as long as you’re learning from it.
- But those lessons learned need to happen quickly, with fast feedback cycles.
- Small scale focus and rapid learning cycles.
- In other words, fail fast really means “learn fast”.
It’s super important to recognize that Scrum is *not* prescriptive. It’s more like guardrails to a process. An Overview of the Scrum Framework - The product owner has a prioritized backlog of work for the team.
- Every sprint, the team looks at the backlog and decides what they can accomplish during that sprint, which is generally 2-3 weeks.
- The team develops and tests their solutions until completed. This effort needs to happen within that sprint.
- The team then demonstrates their finished product to the product owner at the end of the sprint.
- The team has a retrospective to see how the sprint went, what worked, and what they can improve going forward.
Focusing on creating a completed, demo-able piece of work in the sprint allows the team to succeed or fail/learn fast. Projects are typically comprised of three basic things: time, cost, and scope. Usually time and cost are fixed, so all you can work with is the scope. There are Two Key Roles Within Scrum - Project owner – The business representative dedicated 100% to the team.
- Acts as a full time business representative.
- Reviews the team’s work constantly to ensure the proper deliverable is being created.
- Interacts with the stakeholders.
- Is the keeper of the product vision.
- Responsible for making sure the work is continuously sorted per the ongoing business needs.
- The Scrum master – Responsible for helping resolve daily issues and balance ongoing changes in requirements and/or scope.
- This person has a mastery of Scrum.
- Also helps improve internal team processes.
- Responsible for protecting the team and their processes.
- Balances the demands of the product owner and the needs of the team.
- This means keeping the team working at a sustainable rate.
- Acts as the spokesperson for the entire team.
- Provides charts and other views into the progress for others for transparency.
- Responsible for removing any blockers.
Project owner focuses on what needs to be done while the Scrum master focuses on how the team gets it done. Scrum doesn’t value heroics by teams or team members. Scrum is all about Daily Collaboration - Whatever you can do to make daily collaboration easier will yield great benefits.
- Collocate your team if possible.
- If you can’t do that, use video conferencing, chat, and/or conference calls to keep communication flowing.
The Team Makeup - You must have a dedicated team. If members of your team are split amongst different projects, it will be difficult to accomplish your goals as you lose efficiency.
- The ideal team size is 5 to 9 members.
- You want a number of T-shaped developers.
- These are people can work on more than one type of deliverable.
- You also need some “consultants” you may be able to call on that have more specialized/focused skillsets that may not be core members of the team.
Team Norms - Teams will need to have standard ways of dealing with situations.
- How people will work together.
- How they’ll resolve conflicts.
- How to come to a consensus.
- Must have full team buy-in and everyone must be willing to hold each other accountable.
Agree to disagree, but move forward with agreed upon solution. Product Vision - It’s the map for your team, it’s what tells you how to get where you want to go.
- This must be established by the project owner.
- The destination should be the “MVP”, i.e. the Minimum Viable Product.
- Why MVP? By creating just enough to get it out to the early adopters allows you to get feedback early.
- This allows for a fast feedback cycle.
- Minimizes scope creep.
- Must set the vision, and then decompose it.
Break the Vision Down into Themes - Start with a broad grouping of similar work.
- Allows you to be more efficient by grouping work together in similar areas.
- This also allows you to think about completing work in the required order.
Once You’ve Identified the Themes, You Break it Down Further into Features If you had a theme of a User Profile, maybe your features might be things like: - Change password,
- Setup MFA, and
- Link social media.
To get the MVP out the door, you might decide that only the Change Password feature is required. Resources We Like Tip of the Week - Learn and practice your technical writing skills.
- Online Technical Writing: Contents, Free Online Textbook for Technical Writing (prismnet.com)
- Using k9s makes running your Kubernetes cronjobs on demand super easy. Find the cronjob you want to run (hint:
:cronjobs) and then use CTRL+T to execute the cronjob now. (GitHub) - Windows Terminal is your new favorite terminal. (microsoft.com)
- TotW redux: GitHub CLI – Your new favorite way to interact with your GitHub account, be it public GitHub or GitHub Enterprise. (GitHub)
- Joe previously mentioned the GitHub CLI as a TotW (episode 142)
- Grep Console – grep, tail, filter, and highlight … everything you need for a console, in your JetBrains IDE. (plugins.jetbrains.com)
- Use
my_argument:true when calling pwsh to pass boolean values to your Powershell script. - JetBrains allows you to prorate your license upgrades at any point during your subscription.
Direct download: coding-blocks-episode-155.mp3
Category: Software Development
-- posted at: 9:18pm EDT
|
|
Sun, 14 March 2021
We dig into recursion and learn that Michael is the weirdo, Joe gives a subtle jab, and Allen doesn’t play well with others while we dig into recursion. This episode’s show notes can be found at https://www.codingblocks.net/episode154, for those that might be reading this via their podcast player. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
News - Thank you all for the reviews:
- iTunes: ripco55, Jla115
- Audible: _onetea, Marnu, Ian
Here I Go Again On My Own What is Recursion? - Recursion is a method of solving a problem by breaking the problem down into smaller instances of the same problem.
- A simple “close enough” definition: Functions that call themselves
- Simple example:
fib(n) { n <= 1 ? n : fib(n - 1) + fib(n - 2) } - Recursion pros:
- Elegant solutions that read well for certain types of problems, particularly with unbounded data.
- Work great with dynamic data structures, like trees, graphs, linked lists.
- Recursion cons:
- Tricky to write.
- Generally perform worse than iterative solutions.
- Runs the risk of stack overflow errors.
- Recursion is often used for sorting algorithms.
How Functions Roughly Work in Programming Languages - Programming languages generally have the notion of a “call stack”.
- A stack is a data structure designed for LIFO. The call stack is a specialized stack that is common in most languages
- Any time you call a function, a “frame” is added to the stack.
- The frame is a bucket of memory with (roughly) space allocated for the input arguments, local variables, and a return address.
- Note: “value types” will have their values duplicated in the stack and reference types contain a pointer.
- When a method “returns”, it’s frame is popped off of the stack, deallocating the memory, and the instructions from the previous function resume where it left off.
- When the last frame is popped off of the call stack, the program is complete.
- The stack size is limited. In C#, the size is 1MB for 32-bit processes and 4MB for 64-bit processes.
- You can change these values but it’s not recommended!
- When the stack tries to exceed it’s size limitations, BOOM! … stack overflow exception!
- How big is a frame? Roughly, add up your arguments (values + references), your local variables, and add an address.
- Ignoring some implementation details and compiler optimizations, a function that adds two 32b numbers together is going to be roughly 96b on the stack: 32 * 2 + return address.
- You may be tempted to “optimize” your code by condensing arguments and inlining code rather than breaking out functions… don’t do this!
- These are the very definition of micro optimizations. Your compiler/interpreter does a lot of the work already and this is probably not your bottleneck by a longshot. Use a profiler!
- Not all languages are stack based though: Stackless Python (kinda), Haskell (graph reduction), Assembly (jmp), Stackless C (essentially inlines your functions, has limitations)
The Four Memory Segments  source: Quora How Recursive Functions Work - The stack doesn’t care about what the return address is.
- When a function calls any other function, a frame is added to the stack.
- To keep things simple, suppose for a Fibonacci sequence function, the frame requires 64b, 32b for the argument and 32b for the return address.
- Every Fibonacci call, aside from 0 or 1, adds 2 frames to the stack. So for the 100th number we will allocate .6kb (1002 * 32). And remember, we only have 1mb for everything.
- You can actually solve Fibonacci iteratively, skipping the backtracking.
- Fibonacci is often given as an example of recursion for two reasons:
- It’s relatively easy to explain the algorithm, and
- It shows the danger of this approach.
What is Tail Recursion? - The recursive Fibonacci algorithm discussed so far relies on backtracking, i.e. getting to the end of our data before starting to wind back.
- If we can re-write the program such that the last operation, the one in “tail position” is the ONLY recursive call, then we no longer need the frames, because they are essentially just pass a through.
- A smart compiler can see that there are no operations left to perform after the next frame returns and collapse it.
- The compiler will first remove the last frame before adding the new one.
- This means we no longer have to allocate 1002 extra frames on the stack and instead just 1 frame.
- A common approach to rewriting these types of problems involves adding an “accumulator” that essentially holds the state of the operation and then passing that on to the next function.
- The important thing here, is that the your ONE AND ONLY recursive call must be the LAST operation … all by itself.
Joe’s (Un)Official Recursion Tips - Start with the end.
- Do it by hand.
- Practice, practice, practice.
Joe Recursion Joe’s Motivational Script 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #!/usr/bin/env python3 import sys def getname(arg): print(f"{arg}") if arg == 'Joe': getname('Recursion') else: getname('Joe') return if __name__ == "__main__": sys.setrecursionlimit(500) print(f"Who is awesome?") try: getname('Joe') except: print("You got this!") | Recap - Recursion is a powerful tool in programming.
- It can roughly be defined as a function that calls itself.
- It’s great for dynamic/unbounded data structures like graphs, trees, or linked lists.
- Recursive functions can be memory intensive and since the call stack is limited, it is easy to overflow.
- Tail call optimization is a technique and compiler trick that mitigates the call stack problem, but it requires language support and that your recursive call be the last operation in your function.
- FAANG-ish interviews love recursive problems, and they love to push you on the memory.
Resources We Like - Recursion (computer science) (Wikipedia)
- Dynamic Programming (LeetCode)
- Grokking Dynamic Programming Patterns for Coding Interviews (educative.io)
- Boxing and Unboxing in .NET (episode 2)
- IDA EBP variable offset (Stack Exchange)
- What is the difference between the stack and the heap? (Quora)
- Data Structures – Arrays and Array-ish (episode 95)
- Function Calls, Part 3 (Frame Pointer and Local Variables) (codeguru.com)
- How to implement the Fibonacci sequence in Python (educative.io)
- Tail Recursion for Fibonacci (GeeksforGeeks.org)
- Recursion (GeeksforGeeks.org)
- Structure and Interpretation of Computer Programs (MIT)
- Tail Recursion Explained – Computerphile (YouTube)
- !!Con 2019- Tail Call Optimization: The Musical!! by Anjana Vakil & Natalia Margolis (YouTube)
Tip of the Week - How to take good care of your feet (JeanCoutu.com)
- Be sure to add
labels to your Kubernetes objects so you can later use them as your selector. (kubernetes.io) - Example:
kubectl get pods --selector=app=nginx - Security Now!, Episode 808 (twit.tv, grc.com)
Direct download: coding-blocks-episode-154.mp3
Category: Software Development
-- posted at: 10:10pm EDT
|
|
Sun, 28 February 2021
It’s been a minute since we last gathered around the water cooler, as Allen starts an impression contest, Joe wins said contest, and Michael earned a participation award. For those following along in their podcast app, this episode’s show notes can be found at https://www.codingblocks.net/episode153. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- DataStax – Sign up today to get $300 in credit with promo code
CODINGBLOCKS and make something amazing with Cassandra on any cloud. Survey Says News - Thank you all for the latest reviews:
- iTunes: peter b :(, Jackifus, onetea_
- Getting BSOD? Test your memory with MemTest86.
Gather Around the Water Cooler - Go deep on a single language? Or know enough about many of them?
- Who is hiring for remote work?
- Remote job resources:
- What companies are in your top 3?
- Know your storage technology. What it excels at and what it doesn’t.
Resources We Like Tip of the Week - Automated Google Cloud Platform Authentication with minikube.
- Calvin and Hobbes the Search Engine (MichaelYingling.com)
- 11 Facts About Real-World Container Use (Datadog)
- Tips & Tricks for running Strimzi with kubectl (Strimzi)
Direct download: coding-blocks-episode-153.mp3
Category: Software Development
-- posted at: 8:29pm EDT
|
|
Sun, 14 February 2021
We dig into all things Python, which Allen thinks is pretty good, and it’s rise in popularity, while Michael and Joe go toe-to-toe over a gripe, ahem, feature. We realize that you _can_ use your podcast player to read these notes, but if you didn’t know, this episode’s show notes can be found at https://www.codingblocks.net/episode152. Check it out and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- DataStax – Sign up today to get $300 in credit with promo code
CODINGBLOCKS and make something amazing with Cassandra on any cloud. - Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - The Coding Blocks Game Jam 2021 results are in! (itch.io)
- Our review page has been updated! (/review)
- Ergonomic keyboard reviews:
- Kinesis Advantage 2 Full Review after Heavy Usage (YouTube)
- Ergonomic Keyboard Zergotech Freedom Full Review (YouTube)
Why Python? A Brief History of Python. Very Brief. - Python is a general-purpose high-level programming language, which can be used to develop desktop GUI applications, websites, and apps that run on sophisticated algorithms.
- Python was created in 1991, before JavaScript or Java, but didn’t make major leaps in popularity until 1998 – 2003, according to the Tiobe index.
- Coincidentally, this lines up with the early days of Google, where they had a motto of “Python where we can, C++ where we must”.
- In 2009, MIT switched from Scheme to Python, and others in academia followed.
Some Python Benefits, But Only Some - It’s an easy language for new developers as well as those who don’t consider themselves developers, such as data scientists or hobbyists, but have a need write some code.
- Python has a great standard library when compared to languages like JavaScript that largely rely on third party libraries to provide depth in functionality.
- It’s cross platform. As long as we’re talking OS.
- Mobile? Not really, as that space is consumed with Swift, Java, and Objective-C. But with things like Pythonista, you can write and execute Python on mobile.
- Web? No, at least not on the client side. That space is dominated by JavaScript. But with frameworks like Django and Flask, you can use Python on the server side.
- In addition to the standard library, there are also many great/popular third party libraries, like NumPy, that are available on PyPi.
The Downsides to Python - Performance when compared to a natively compiled application because it’s a dynamic, interpreted language.
- Which brings up the late binding type system.
- The lack of mobile and web presence as previously mentioned.
- Legacy issues when dealing with v2, which is still in use.
- Language features that haven’t aged well, such as PEP-8.
- Quirks like
self, or __init__, private functionality, and immutability. Resources We Like - The Python Programming Language (Tiobe)
- Heavy usage of Python at Google (Stack Overflow)
- The Incredible Growth of Python (Stack Overflow)
- 2020 Developer Survey, Top Paying Technologies (Stack Overflow)
- What makes Python more popular than Ruby? (Reddit)
- 2020 Developer Survey, Most Loved, Dreaded, and Wanted (Stack Overflow)
- Top 10 Python Packages For Machine Learning (ActiveState.com)
- 56 Groundbreaking Python Open-source Projects – Get Started with Python (data-flair.training)
- Top 10 Python Packages Every Developer Should Learn (ActiveState.com)
- Choosing the right estimator aka the scikit-learn algorithm cheat-sheet (scikit-learn.org)
- Previously discussed as a Tip of the Week during episode 92, Azure Functions and CosmosDB from MS Ignite (/episode92)
- Introduction to Celery (docs.celeryproject.org)
- Is it possible to compile a program written in Python? (Stack Overflow)
- Pythonista 3 – A Full Python IDE for iOS (omz-software.com)
- Previously discussed as a Tip of the Week during episode 88, What is Algorithmic Complexity? (/episode88)
- Flask – Web development, one drop at a time (flask.palletsprojects.com)
- Django – A high-level Python Web framework that encourages rapid development and clean, pragmatic design. (DjangoProject.com)
- PyPi – The Python Package Index (PyPI) is a repository of software for the Python programming language. (pypi.org)
- Ten Reasons To Use Python (cuelogic.com)
- Top 10 Reasons Why Python is So Popular With Developers in 2021 (upgrad.com)
- Python – 12. Virtual Environments and Packages (docs.python.org)
- Python’s virtual environments have been mentioned as a Tip of the Week twice: first during episode 102, Why Date-ing is Hard and again during episode 140, The DevOps Handbook – Enabling Safe Deployments. (/episode102, /episode140)
- PEP 8 — Style Guide for Python Code (python.org)
- The Gary Gnu Intro With Knock Knock – The Great Space Coaster (YouTube)
- Datadog has a blog article for everything:
- Tracing asynchronous Python code with Datadog APM (Datadog)
- How to collect, customize, and centralize Python logs (Datadog)
Tip of the Week - It’s easy to get the last character of a string in Python:
last_char = sample_str[-1] - Follow us on Twitch:
- Install the Git cheat NPM module to use
git cheat to easily see a Git cheat sheet in your terminal. (GitHub) gcloud has a built-in cheat sheet. Use gcloud cheat-sheet to access it. (Google Cloud)
Direct download: coding-blocks-episode-152.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 31 January 2021
We step back to reflect on what we learned from our first game jam, while Joe’s bathroom is too close and Allen taught Michael something (again). Stop squinting to read this via your device’s podcast player. This episode’s show notes can be found at https://www.codingblocks.net/episode151, where you can join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- DataStax – Sign up today to get $300 in credit with promo code
CODINGBLOCKS and make something amazing with Cassandra on any cloud. - Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - We appreciate the new reviews, thank you!
- iTunes: ddausdd
- Audible: devops.rob
- Kinesis Advantage 2 Full Review after Heavy Usage (YouTube)
Game Jam Tips - Aim for the browser and to be embedded.
- Be careful sharing your custom URL when hosting somewhere other than the game jam as it splits your traffic and likely, your feedback.
- Time management is super important.
- Be realistic about how much time you have.
- You’ll be tired by the end!
- Start with the Game Loop.
- Try to always be playable.
- Aim small and prioritize the “must haves”.
- Know what you want to learn.
- Judge your game against what you can do.
- Beware of graphics and animations! Inspiration is fine, but it can become a sinkhole.
- Recall from the above tips about time management and focusing on a playable game.
- Play into the theme. Or don’t.
- Use tools, asset stores, and libraries, such as Tiled, PyGame, Photoshop, and/or Butler, to simplify your effort and make maximum use of your time.
- Consider teamwork.
- Borrowing ideas is fine.
- Keep your “elevator pitch” in mind, and evolve it.
- Publish early and save energy for playing.
- Save time to write up your game’s description, take video/screenshots, etc. for the submission.
- Keep your game testable by having a dev mode and/or the ability to initialize a certain game state.
- Think about the player over and over and over. How do you teach them the game’s mechanics, physics, when the game is over, etc.
- And again, save time and energy for publishing your game, as well as, playing and rating other’s games.
Resources We Like - The Coding Blocks Game Jam 2021 submissions (itch.io)
Tip of the Week - Sign up for a game jam! (itch.io)
- Use
-A number, -B number, or -C number to include context with your next grep output. (gnu.org) -A number will print number lines after the match.-B number will print number lines before the match.-C number will print number lines before and after the match. - Add your Git commit to your Docker images as a label like:
docker build --tag 1.0.0.1 --label git-commit=$GIT_COMMIT . - Where
$GIT_COMMIT might be something like: GIT_COMMIT=$(git rev-parse HEAD) or GIT_COMMIT=$(git rev-parse --short HEAD) if you only want to use the abbreviated commit ID.- In Jenkins, you can use
${env.GIT_COMMIT} to get the current commit ID that the current build is building,
Direct download: coding-blocks-episode-151.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 17 January 2021
We discuss all things open-source, leaving Michael and Joe to hold down the fort while Allen is away, while Joe’s impersonations are spot on and Michael is on a first name basis, assuming he can pronounce it. This episode of the Coding Blocks podcast is about the people and organizations behind open-source software. We talk about the different incentives behind projects, and their governance to see if we can understand our ecosystem better. This episode’s show notes can be found at https://www.codingblocks.net/episode150, if you’re reading this via your podcast player. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - We appreciate the new reviews, thank you!
- iTunes: @k_roll242, code turtle
Upcoming Events: You Thought You Knew OSS Q: What do most developers think about when they think of “open-source” software? Q: Is the formal definition more important than the general perception? Formal Definitions of Open-Source - opensource.org: Open source software is made by many people and distributed under an OSD-compliant license which grants all the rights to use, study, change, and share the software in modified and unmodified form. Software freedom is essential to enabling community development of open source software.
- opensource.com: Open source commonly refers to software that uses an open development process and is licensed to include the source code
Pop Quiz, who created…? - C: Dennis Ritchie
- Linux: Linus Torvolds
- Curl: Daniel Sternberg
- Python: Guido von Rossum
- JavaScript: Brandon Eich (Netscape)
- Node: Ryan Dahl
- Java: James Gosling (Sun)
- Git: Linus Torvalds
- C#: Microsoft (Anders Hejlsberg)
- Kubernetes: Google
- Postgres: Michael Stonebraker
- React: Facebook
- Rust: Mozilla
- Chromium: Google
- Flutter: Google
- TypeScript: Microsoft
- Vue: Evan You
Q: It seems like most newer projects (with the exception of Vue) are associated with corporations or foundations. When and why did that change? GitHub Star Distribution Q: What are the most popular projects? Who were they made for, and why? Who uses open-source software? - There are a lot of stats and surveys…none great
- All surveys and stats agree that open-source is on the rise
- You kinda can’t not use open-source software. Your OS, tools, networking hardware, etc all use copious amounts of open-souce software.
Individuals - Many (most) smaller libraries are written and maintained by individual authors, and have few or no contributors
- Some large / important libraries have thousands of contributors
- 10 most contributed GitHub projects in 2019
- VS Code has almost 20k contributors
- Flutter has 13k contributors
- Kubernetes and Ansible have around 7k
Q: Why do individuals create open source? What do they get out of it? Corporations - A lot of corporate “open source” that are utilities or tools for working with those companies (ie: Azure SDK)
- Many open source projects are stewarded by a single company (Confluent, Elastic, MongoDB)
- Many open source projects listed below are now run by a foundation
Let’s look at some of the most prominent projects that were started by corporations. Note: many of these projects came in through acquisitions, and many have since been donated to foundations. Microsoft Google - Kubernetes, Angular, Chromium, Android, Go, Dart, Protobuff, TensorFlow, Flutter, Skaffold, Spinnaker, Polymer, Yeoman
- https://opensource.google/projects/explore/featured
Facebook Amazon - Well, lots of toolkits and sdks for AWS…
Oracle Focused Corporations Sometimes a company will either outright own, or otherwise build a business centered around a technology. These companies will typically offer services and support around open-source projects. - DataStax
- Elasticsearch
- Canonical
- MongoDB
Q: Why do corporations publish open-source software? What do they get out of releasing projects? Foundations - Foundations are organizations that own open-source projects
- Foundations have many different kinds of governance models, but generally they are responsible for things like…
- code stewardship (pull requests, versions, planning, contributors, lifecycle, support, certification*)
- financial support (domains, hosting, marketing, grants)
- legal issues (including protecting the contributors liability)
- Most big open-source projects you can think of run under some sort of foundation
- Typically they are funded by large corporate backers
- There are a ton of foundations here. including many “one-offs”: https://opensource.com/resources/organizations ** WordPress Foundation, Python Foundation, Mozilla foundations
- Foundations are run in a variety of ways, and for different reasons, some even offer many competing projects
- https://opensource.guide/leadership-and-governance/ ** BDFL – Python, small projects, one person has final say ** “Meritocracy” (not a great term) – Active contributors are given decision making power, voting ** Liberal Contribution: Projects seek concensus rather than a pure vote, strive to be inclusive (Node, Rust)
Apache (1999) - Governance: https://www.apache.org/foundation/governance/
- Org Chart: https://www.apache.org/foundation/governance/orgchart
- https://projects.apache.org/
- Non-Profit Company, mostly Java, tons of libraries, data
- All volunteer board, 350+ projects
- Projects
- HTTPD, Kafka, Spark, Flink, Groovy, Avro, Log4…, Maven, ActiveMQ, Lucene, Solr,
Cloud Native Computing Foundation - Kubernetes, Helm, Prometheus, FluentD, Linkerd, OpenTracing
- A whole bunch of others that start with a K
Linux Foundation - Linux Kernel
- Kubernetes..? Ah, they’re over CNCF, and many, many, many other things
- Let’s Encrypt, NodeJS (through the OpenJs Foundation)
Q: Why do corporations donate projects, why do individuals? Who really owns open-source code? Resources We Like Tip of the Week
Direct download: coding-blocks-episode-150.mp3
Category: Software Development
-- posted at: 9:55pm EDT
|
|
Sun, 3 January 2021
We start off the year discussing our favorite developer tools of 2020, as Joe starts his traditions early, Allen is sly about his résumé updates, and Michael lives to stream. For those that read the show notes via their podcast player and find themselves wondering where they can find these show notes on their computer, the answer is simple: https://www.codingblocks.net/episode149. Check it out and join the discussion. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after your first dashboard.
Survey Says Take the survey at: https://www.codingblocks.net/episode149. News - Thank you for the new reviews we received this holiday!
- iTunes: larsankile, 0xACE, Tbetcha33, The_Shrike_, shineycloud
- Watch Joe speak at the virtual San Diego Elastic Meetup, Tuesday, January 19, 2021 at 5:00 PM PST, where he is talking about Easy Local Development with Elastic Cloud on Kubernetes using Skaffold.
- Join our game jam January 21 – 24, 2021 and let’s make games!
The Top Tools of 2020 - K9s – A terminal UI to interact with your Kubernetes cluster.
- Popeye – A utility that scans a live Kubernetes cluster and reports potential issues with deployed resources and configurations.
- All things JetBrains, especially IntelliJ IDEA, PyCharm, and DataGrip. Amazing, cross-platform tools that developers from all tech stacks can use.
- Skaffold – Handles the workflow for building, pushing, and deploying your application within Kubernetes, allowing you to focus on writing your code.
- Kustomize – A template-free way to customize Kubernetes application configuration, built into
kubectl. - Oh My Zsh – An open source, community-driven framework for managing your zsh configuration.
- Netlify – Unites everything teams need to build and run dynamic web experiences, from preview to production, using an intuitive git-based workflow and a powerful serverless platform.
- Jira StopWatch – A desktop tool for recording time spent on different Jira issues.
- Lens – The Kubernetes IDE, Lens provides full situational awareness for everything that runs in Kubernetes, lowering the barrier of entry for those just getting started with Kubernetes, while radically improving productivity for the experienced users.
- Zoom – Keeping you connected wherever you are. Hands down, the best video calling software out there for screen sharing; you can actually read the other person’s screen!
- Prometheus – Power your metrics and alerting with a leading open-source monitoring solution.
- Grafana – The world’s most popular technology used to compose observability dashboards.
- Visual Studio Code – Code editing, redefined. Free and built on open source. Runs everywhere.
- Favorite VS Code extensions:
- Bracket Pair Colorizer – Matching brackets can be easily identified in color.
- GitLens – Supercharges the Git capabilities built into Visual Studio Code.
- Rainbow CSV – Highlight CSV files and run SQL-like queries.
- Cmder – A software package created out of pure frustration over the absence of nice console emulators on Windows.
- Unraid – Take control of your data, media, applications, and desktops, using just about any combination of hardware.
Resources We Like - Streaming: Debugging C# in Kubernetes and Skaffold vs Kustomize (YouTube)
Tip of the Week - Challenging projects every programmer should try (utk.edu)
- More challenging projects every programmer should try (utk.edu)
- Duck DNS – A free dynamic DNS hosted on AWS (duckdns.org)
- Honorable DNS mentions:
- 8.8.8.8/8.8.4.4 – Google Public DNS (Wikipedia)
- 9.9.9.9/9.9.9.10/9.9.9.11 – Quad9 (Wikipedia)
- 1.1.1.1/1.1.1.2/1.1.1.3 – Cloudflare’s DNS (Wikipedia)
- MIT’s Missing Semester of CS Education:
- The Missing Semester of Your CS Education (mit.edu)
- Missing Semester IAP 2020 (YouTube)
- 2020 Lectures (mit.edu)
Direct download: coding-blocks-episode-149.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|


 The macro problem with microservices (Stack Overflow)
The macro problem with microservices (Stack Overflow)



































































