We continue our discussion of Designing Data-Intensive Applications, this time focusing on multi-leader replication, while Joe is seriously tired, and Allen is on to Michael’s shenanigans.
For anyone reading this via their podcast player, this episode’s show notes can be at https://www.codingblocks.net/episode161, where you can join the conversation.
Sponsors
- Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says
News
- Thank you very much for the new reviews:
- iTunes: GubleReid, tbednarick, JJHinAsia, katie_crossing
- Audible: Anonymous User, Anonymous User … hmm
When One Leader Just Won’t Do

Talking about Multi-Leader Replication
Replication Recap and Latency
- When you’re talking about single or multi-leader replication, remember all writes go through leaders
- If your application is read heavy, then you can add followers to increase your scalability
- That doesn’t work well with sync writes..the more followers, the higher the latency
- The more nodes the more likely there will be a problem with one or more
- The upside is that your data is consistent
- The problem is if you allow async writes, then your data can be stale. Potentially very stale (it does dial up the availability and perhaps performance)
- You have to design your app knowing that followers will eventually catch up – “eventual consistency“
- “Eventual” is purposely vague – could be a few seconds, could be an hour. There is no guarantee.
- Some common use cases make this particularly bad, like a user updating some information…they often expect to see that change afterwards
- There are a couple techniques that can help with this problem
Techniques for mitigation replication lag
- Read You Writes Consistency refers to an attempt to read significant data from leader or in sync replicas by the user that submitted the data
- In general this ensures that the user who wrote the data will get the same data back – other users may get stale version of the data
- But how can you do that?
- Read important data from a leader if a change has been made OR if the data is known to only be changeable by that particular user (user profile)
- Read from a leader/In Sync Replica for some period of time after a change
- Client can keep a timestamp of it’s most recent write, then only allow reads from a replica that has that timestamp (logical clocks keep problems with clock synchronization at bay here)
- But…what if the user is using multiple devices?
- Centralize MetaData (1 leader to read from for everything)
- You make sure to route all devices for a user the same way
- Monotonic Reads: a guarantee of sorts that ensures you won’t see data moving backwards in time. One way to do this – keep a timestamp of the most recent read data, discard any reads older than that…you may get errors, but you won’t see data older than you’ve already seen.
- Another possibility – ensure that the reads are always coming from the same replica
- Consistent Prefix Reads: Think about causal data…an order is placed, and then the order is shipped…but what if we had writes going to more than one spot and you query the order is shipped..but nothing was placed? (We didn’t have this problem with a Single Replica)
- We’ll talk more about this problem in a future episode, but the short answer is to make sure that causal data gets sent to the same “partition”
Replication isn’t as easy as it sounds, is it?
Multi-Leader Rep…lication
Single leader replication had some problems. There was a single point of failure for writes, and it could take time to figure out the new leader. Should the old leader come back then…we have a problem. Multi-Leader replication…
- Allows more than one node to receive writes
- Most things behave just like single-leader replication
- Each leader acts as followers to other leaders
When to use Multi-Leader Replication
- Many database systems that support single-leader replication can be taken a step further to make them mulit-leader. Usually. you don’t want to have multiple leaders within the same datacenter because the complexity outweighs the benefits.
- When you have multiple leaders you would typically have a leader in each datacenter
- An interesting approach is for each datacenter to have a leader and followers…similar to the single leader. However, each leader would be followers to the other datacenter leaders
- Sort of a chained single-leader replication setup
Comparing Single-Leader vs Multi-Leader Replication
Performance – because writes can occur in each datacenter without having to go through a single datacenter, latency can be greatly reduced in multi-leader
- The synchronization of that data across datacenters can happen asynchronously making the system feel faster overall
- Fault tolerance – in single-leader, everything is on pause while a new leader is elected
- In multi-leader, the other datacenters can continue taking writes and will catch back up when a new leader is selected in the datacenter where the failure occurred
Network problems - Usually a multi-leader replication is more capable of handling network issues as there are multiple data centers handling the writes – therefore a major issue in one datacenter doesn’t cause everything to take a dive
So it’s clear right? Multi-leader all the things? Hint: No!
Problems with Multi-Leader Replication
- Changes to the same data concurrently in multiple datacenters has to be resolved – conflict resolution – to be discussed later
- External tools for popular databases:
- Additional problems – multi-leader is typically bolted on after the fact
- Auto-incrementing keys, triggers, constraints can all be problematic
- Those reasons alone are reasons why it’s usually recommended to avoid multi-leader replication
Clients with offline operation
- Multi-leader makes sense when there are applications that need to continue to work even when they’re not connected to the network
- Calendars were an example given – you can make changes locally and when your app is online again it syncs back up with the remote databases
- Each application’s local database acts as a leader
- CouchDB was designed to handle this type of setup
Collaborative editing
Google Docs, Etherpad, Changes are saved to the “local” version that’s open per user, then changes are synced to a central server and pushed out to other users of the document
Conflict resolution
- One of the problems with multi-leader writes is there will come times when there will be conflicting writes when two leaders write to the same column in a row with different values
- How do you solve this?
- If you can automate, you should because you don’t want to be putting this together by hand
- Make one leader more important than the others
- Make certain writes always go through the same data centers
- It’s not easy – Amazon was brought up as having problems with this as well
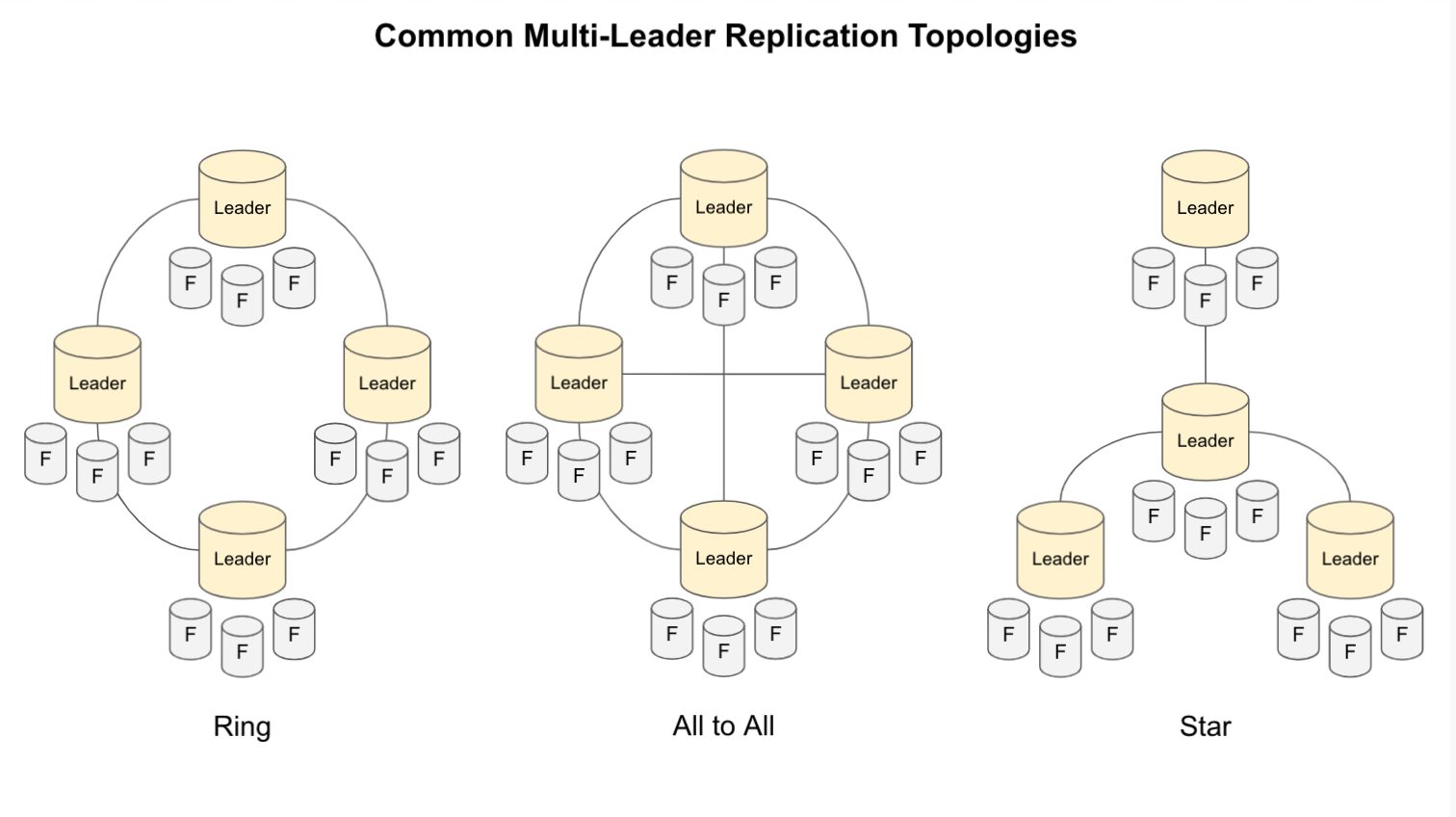
Multi-Leader Replication Toplogogies
- A replication topology describes how replicas communicate
- Two leaders is easy
- Some popular topologies:
- Ring: Each leader reads from “right”, writes to the “left”
- All to All: Very Chatty, especially as you add more and more nodes
- Star: 1 special leader that all other leaders read from
- Depending on the topology, a write may need to pass through several nodes before it reaches all replicas
- How do you prevent infinite loops? Tagging is a popular strategy
- If you have a star or circular topology, then a single node failure can break the flow
- All to all is safest, but some networks are faster than others that can cause problems with “overrun” – a dependent change can get recorded before the previous
- You can mitigate this by keeping “version vectors”, kind of logical clock you can use to keep from getting too far ahead
Resources We Like
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
- Amazon Yesterday Shipping (YouTube)
- Uber engineering blog (eng.uber.com)
Tip of the Week
- .http files are a convenient way of running web requests. The magic is in the IDE support. IntelliJ has it built in and VSCode has an extension. (IntelliJ Products, VSCode Extension)
- iTerm2 is a macOS Terminal Replacement that adds some really nice features. Some of our Outlaw’s favorite short-cuts: (iTerm2, Features and Screenshots)
- CMD+D to create a new panel (split vertically)
- CMD+SHIFT+D to create a new panel (split horizontally)
- CMD+Option+arrow keys to navigate between panes
- CMD+Number to navigate between tabs
- Ruler Hack – An architect scale ruler is a great way to prevent heat build up on your laptop by giving the hottest parts of the laptop some air to breathe. (Amazon)
- Fizz Buzz Enterprise Edition is a funny, and sadly reminiscent, way of doing FizzBuzz that incorporates all the buzzwords and most abused design patterns that you see in enterprise Code. (GitHub)
- From our friend Jamie Taylor (of DotNet Core Podcast, Tabs ‘n Spaces, and Waffling Taylors), mkcert is a “zero-config” way to easily generate self-signed certificates that your computer will trust. Great for dev! (GitHub)
- Find out more about Jamie on these great shows…



