Mon, 5 July 2021
We wrap up our replication discussion of Designing Data-Intensive Applications, this time discussing leaderless replication strategies and issues, while Allen missed his calling, Joe doesn’t read the gray boxes, and Michael lives in a future where we use apps. If you’re reading this via your podcast player, you can find this episode’s full show notes at https://www.codingblocks.net/episode162. As Joe would say, check it out and join in on the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you for the latest review!
 Check out the book! Single Leader to Multi-Leader to Leaderless - When you have leaders and followers, the leader is responsible for making sure the followers get operations in the correct order
- Dynamo brought the trend to the modern era (all are Dynamo inspired) but also…
- We talked about NoSQL Databases before:
- What exactly is NewSQL? https://en.wikipedia.org/wiki/NewSQL
- What if we just let every replica take writes? Couple ways to do this…
- You can write to several replicas
- You can use a coordinator node to pass on the writes
- But how do you keep these operations in order? You don’t!
- Thought exercise, how can you make sure operation order not matter?
- Couple ideas: No partial updates, increments, version numbers
Multiple Writes, Multiple Reads - What do you do if your client (or coordinator) try to write to multiple nodes…and some are down?
- Well, it’s an implementation detail, you can choose to enforce a “quorom”. Some number of nodes have to acknowledge the write.
- This ratio can be configurable, making it so some % is required for a write to be accepted
- What about nodes that are out of date?
- The trick to mitigating stale data…the replicas keep a version number, and you only use the latest data – potentially by querying multiple nodes at the same time for the requested data
- We’ve talked about logical clocks before, it’s a way of tracking time via observed changes…like the total number of changes to a collection/table…no timezone or nanosecond differences
How do you keep data in sync? - About those unavailable nodes…2 ways to fix them up
- Read Repair: When the client realizes it got stale data from one of the replicas, it can send the updated data (with the version number) back to that replica. Pretty cool! – works well for data that is read frequently
- Anti-Entropy: The nodes can also do similar background tasks, querying other replicas to see which are out of data – ordering not guaranteed!
- Voldemort: ONLY uses read repair – this could lead to loss of data if multiple replicas went down and the “new” data was never read from after being written
Quorums for reading and writing - Quick Reminder: We are still talking about 100% of the data on each replica
- 3 major numbers at play:
- Number of nodes
- Number of confirmed writes
- Number of reads required
- If you want to be safe, the nodes you write to and the ones you write too should include some overlap
- A common way to ensure that, keep the number of writes + the number of reads should be greater than the number of nodes
- Example: You have 10 nodes – if you use 5 for writing and 5 for reading…you may not have an overlap resulting in potentially stale data!
- Common approach – taken number of nodes (odd number) + 1, then divide that number by 2 and that’s the number of reader and writers you should have
- 9 Nodes – 5 writes and 5 reads – ensures non-stale data
- When using this approach, you can handle Nodes / 2 (rounded down) number of failed nodes
- How would you tweak the numbers for a write heavy workload?
- Typically, you write and read to ALL replicas, but you only need a successful response from these numbers
- What if you have a LOT of nodes?!?
- Note: there’s still room for problems here – author explicitly lists 5 types of edge cases, and one category of miscellaneous timing edge cases. All variations of readers and writers getting out of sync or things happen at the same timing
- If you really want to be safe, you need consensus (r = w = n) or transactions (that’s a whole other chapter)
- Note that if the number of required readers or writers doesn’t return an OK, then an error is returned from the operation
- Also worth considering is you don’t have to have overlap – having readers + writers < nodes means you could have stale data, but at possibly lower latencies and lower probabilities of error responses
Monitoring staleness - Single/Multi Leader lag is generally easy to monitor – you just query the leader and the replicas to see which operation they are on
- Leaderless databases don’t have guaranteed ordering so you can’t do it this way
- If the system only uses read repair (where the data is fixed up by clients only as it is read) then you can have data that is ancient
- It’s hard to give a good algorithm description here because so much relies on the implementation details
And when things don’t work? - Multi-writes and multi-reads are great when a small % of nodes or down, or slow
- What if that % is higher?
- Return an error when we can’t get quorum?
- Accept writes and catch the unavailable nodes back up later?
- If you choose to continue operating, we call it “sloppy quorum” – when you allow reads or writes from replicas that aren’t the “home” nodes – the likened it to you got locked out of your house and you ask your neighbor if you can stay at their place for the night
- This increases (write) availability, at the cost of consistency
- Technically it’s not a quorum at all, but it’s the best we can do in that situation if you really care about availability – the data is stored somewhere just not where it’d normally be stored
Detecting Concurrent Writes - What do you get when you write the same key at the same time with different values?
- Remember, we’re talking about logical clocks here so imagine that 2 clients both write version #17 to two different nodes
- This may sound unlikely, but when you realize we’re talking logical clocks, and systems that can operate at reduced capacity…it happens
- What can we do about it?
- Last write wins: But which one is considered last? Remember, how we catch up? (Readers fix or leaders communicate) …either way, the data will eventually become consistent but we can’t say which one will win…just that one will eventually take over
- Note: We can take something else into account here, like clock time…but no perfect answer
- LWW is good when your data is immutable, like logs – Cassandra recommends using a UUID as a key for each write operation
- Happens-Before Relationship – (Riak has CfRDT that bundle a version vector to help with this)
This “happens-before” relationship and concurrency - How do we know whether the operations are concurrent or not?
Basically if neither operation knows about the other, then they are concurrent… - Three possible states if you have writes A and B
- A happened before B
- B happened before A
- A and B happened concurrently
- When there is a happens before, then you take the later value
- When they are concurrent, then you have to figure out how to resolve the conflicts
- Merging concurrently written values
- Last write wins?
- Union the data?
- No good answer
Version vectors - The collection of version numbers from all replicas is called a version vector
- Riak uses dotted version vectors – the version vectors are sent back to the clients when values are read, and need to be sent back to the db when the value is written back
- Doing this allows the db to understand if the write was an overwrite or concurrent
- This also allows applications to merge siblings by reading from one replica and write to another without losing data if the siblings are merged correctly
Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
- Designing Data-Intensive Applications – Data Models: Relational vs Document (episode 123)
- NewSQL (Wikipedia)
- Do not allow Jeff Bezos to return to Earth (Change.org)
- Man Invests $20 in Obscure Cryptocurrency, Becomes Trillionaire Overnight, at Least Temporarily (Newsweek)
- Quantifying Eventual Consistency with PBS (Bailis.org)
- Riak Distributed Data Types (Riak.com)
Tip of the Week - A GitHub repo for a list of “falsehoods”: common things that people believe but aren’t true, but targeted at the kinds of assumptions that programmers might make when they are working on domains they are less familiar with. (GitHub)
- The Linux
at command lets you easily schedule commands to run in the future. It’s really user friendly so you can be lazy with how you specify the command, for example echo "command_to_be_run" | at 09:00 or at 09:00 -f /path/to/some/executable (linuxize.com) - You can try Kotlin online at play.kotlinlang.org, it’s an online editor with links to lots of examples. (play.kotlinlan.org)
- The Docker
COPY cmd will need to be run if there are changes to files that are being copied. You can use a .dockerignore to skip files that you don’t care about to trim down on unnecessary work and build times. (doc.docker.com).
Direct download: coding-blocks-episode-162.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 20 June 2021
We continue our discussion of Designing Data-Intensive Applications, this time focusing on multi-leader replication, while Joe is seriously tired, and Allen is on to Michael’s shenanigans. For anyone reading this via their podcast player, this episode’s show notes can be at https://www.codingblocks.net/episode161, where you can join the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you very much for the new reviews:
- iTunes: GubleReid, tbednarick, JJHinAsia, katie_crossing
- Audible: Anonymous User, Anonymous User … hmm
When One Leader Just Won’t Do Talking about Multi-Leader Replication Replication Recap and Latency - When you’re talking about single or multi-leader replication, remember all writes go through leaders
- If your application is read heavy, then you can add followers to increase your scalability
- That doesn’t work well with sync writes..the more followers, the higher the latency
- The more nodes the more likely there will be a problem with one or more
- The upside is that your data is consistent
- The problem is if you allow async writes, then your data can be stale. Potentially very stale (it does dial up the availability and perhaps performance)
- You have to design your app knowing that followers will eventually catch up – “eventual consistency“
- “Eventual” is purposely vague – could be a few seconds, could be an hour. There is no guarantee.
- Some common use cases make this particularly bad, like a user updating some information…they often expect to see that change afterwards
- There are a couple techniques that can help with this problem
Techniques for mitigation replication lag - Read You Writes Consistency refers to an attempt to read significant data from leader or in sync replicas by the user that submitted the data
- In general this ensures that the user who wrote the data will get the same data back – other users may get stale version of the data
- But how can you do that?
- Read important data from a leader if a change has been made OR if the data is known to only be changeable by that particular user (user profile)
- Read from a leader/In Sync Replica for some period of time after a change
- Client can keep a timestamp of it’s most recent write, then only allow reads from a replica that has that timestamp (logical clocks keep problems with clock synchronization at bay here)
- But…what if the user is using multiple devices?
- Centralize MetaData (1 leader to read from for everything)
- You make sure to route all devices for a user the same way
- Monotonic Reads: a guarantee of sorts that ensures you won’t see data moving backwards in time. One way to do this – keep a timestamp of the most recent read data, discard any reads older than that…you may get errors, but you won’t see data older than you’ve already seen.
- Another possibility – ensure that the reads are always coming from the same replica
- Consistent Prefix Reads: Think about causal data…an order is placed, and then the order is shipped…but what if we had writes going to more than one spot and you query the order is shipped..but nothing was placed? (We didn’t have this problem with a Single Replica)
- We’ll talk more about this problem in a future episode, but the short answer is to make sure that causal data gets sent to the same “partition”
Replication isn’t as easy as it sounds, is it? Multi-Leader Rep…lication Single leader replication had some problems. There was a single point of failure for writes, and it could take time to figure out the new leader. Should the old leader come back then…we have a problem. Multi-Leader replication… - Allows more than one node to receive writes
- Most things behave just like single-leader replication
- Each leader acts as followers to other leaders
When to use Multi-Leader Replication - Many database systems that support single-leader replication can be taken a step further to make them mulit-leader. Usually. you don’t want to have multiple leaders within the same datacenter because the complexity outweighs the benefits.
- When you have multiple leaders you would typically have a leader in each datacenter
- An interesting approach is for each datacenter to have a leader and followers…similar to the single leader. However, each leader would be followers to the other datacenter leaders
- Sort of a chained single-leader replication setup
Comparing Single-Leader vs Multi-Leader Replication Performance – because writes can occur in each datacenter without having to go through a single datacenter, latency can be greatly reduced in multi-leader - The synchronization of that data across datacenters can happen asynchronously making the system feel faster overall
- Fault tolerance – in single-leader, everything is on pause while a new leader is elected
- In multi-leader, the other datacenters can continue taking writes and will catch back up when a new leader is selected in the datacenter where the failure occurred
Network problems - Usually a multi-leader replication is more capable of handling network issues as there are multiple data centers handling the writes – therefore a major issue in one datacenter doesn’t cause everything to take a dive
So it’s clear right? Multi-leader all the things? Hint: No! Problems with Multi-Leader Replication - Changes to the same data concurrently in multiple datacenters has to be resolved – conflict resolution – to be discussed later
- External tools for popular databases:
- Additional problems – multi-leader is typically bolted on after the fact
- Auto-incrementing keys, triggers, constraints can all be problematic
- Those reasons alone are reasons why it’s usually recommended to avoid multi-leader replication
Clients with offline operation - Multi-leader makes sense when there are applications that need to continue to work even when they’re not connected to the network
- Calendars were an example given – you can make changes locally and when your app is online again it syncs back up with the remote databases
- Each application’s local database acts as a leader
- CouchDB was designed to handle this type of setup
Collaborative editing Google Docs, Etherpad, Changes are saved to the “local” version that’s open per user, then changes are synced to a central server and pushed out to other users of the document Conflict resolution - One of the problems with multi-leader writes is there will come times when there will be conflicting writes when two leaders write to the same column in a row with different values
- How do you solve this?
- If you can automate, you should because you don’t want to be putting this together by hand
- Make one leader more important than the others
- Make certain writes always go through the same data centers
- It’s not easy – Amazon was brought up as having problems with this as well
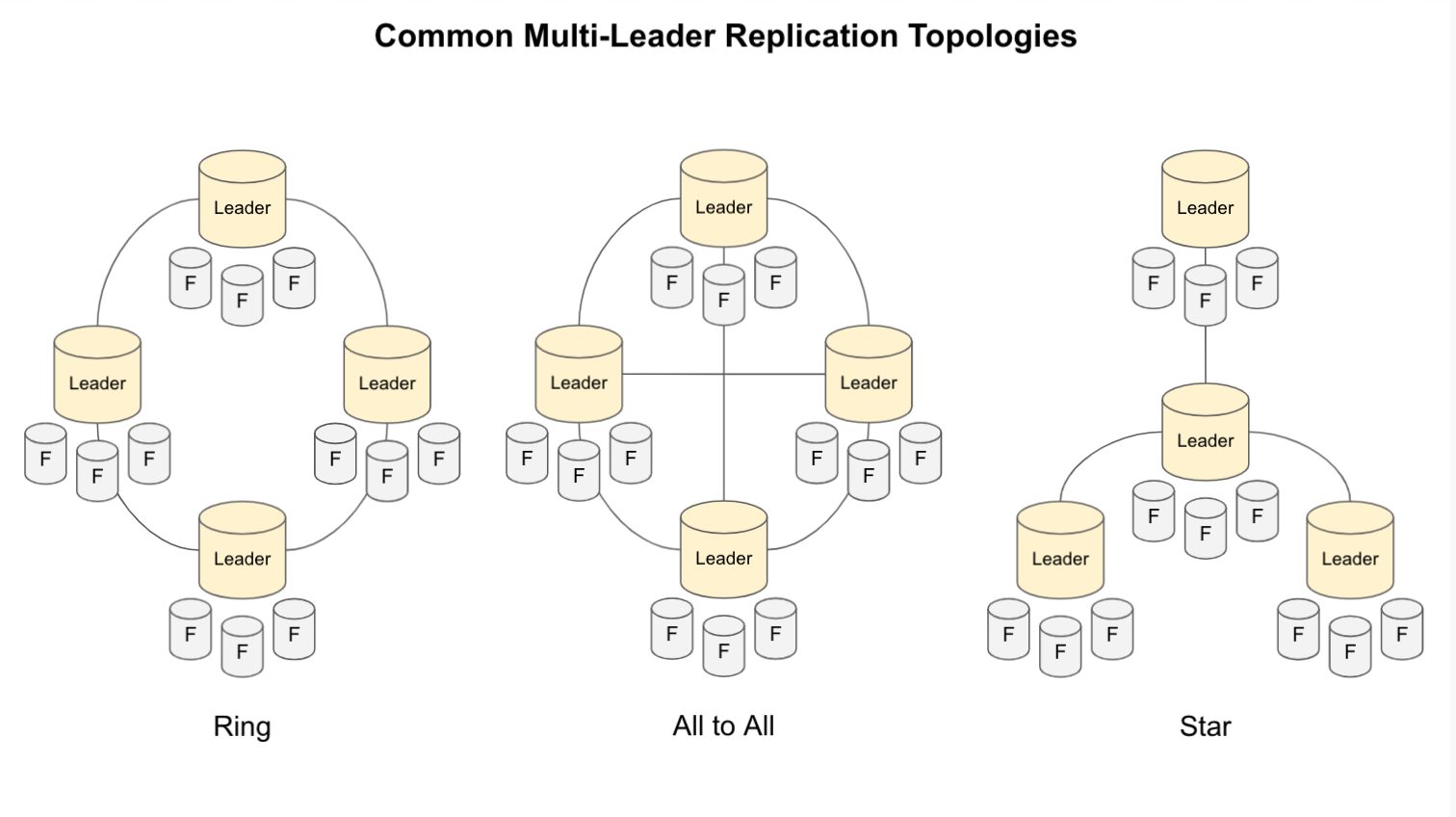
Multi-Leader Replication Toplogogies - A replication topology describes how replicas communicate
- Two leaders is easy
- Some popular topologies:
- Ring: Each leader reads from “right”, writes to the “left”
- All to All: Very Chatty, especially as you add more and more nodes
- Star: 1 special leader that all other leaders read from
- Depending on the topology, a write may need to pass through several nodes before it reaches all replicas
- How do you prevent infinite loops? Tagging is a popular strategy
- If you have a star or circular topology, then a single node failure can break the flow
- All to all is safest, but some networks are faster than others that can cause problems with “overrun” – a dependent change can get recorded before the previous
- You can mitigate this by keeping “version vectors”, kind of logical clock you can use to keep from getting too far ahead
 Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- Past episode discussions on Designing Data-Intensive Applications (Coding Blocks)
- Amazon Yesterday Shipping (YouTube)
- Uber engineering blog (eng.uber.com)
Tip of the Week - .http files are a convenient way of running web requests. The magic is in the IDE support. IntelliJ has it built in and VSCode has an extension. (IntelliJ Products, VSCode Extension)
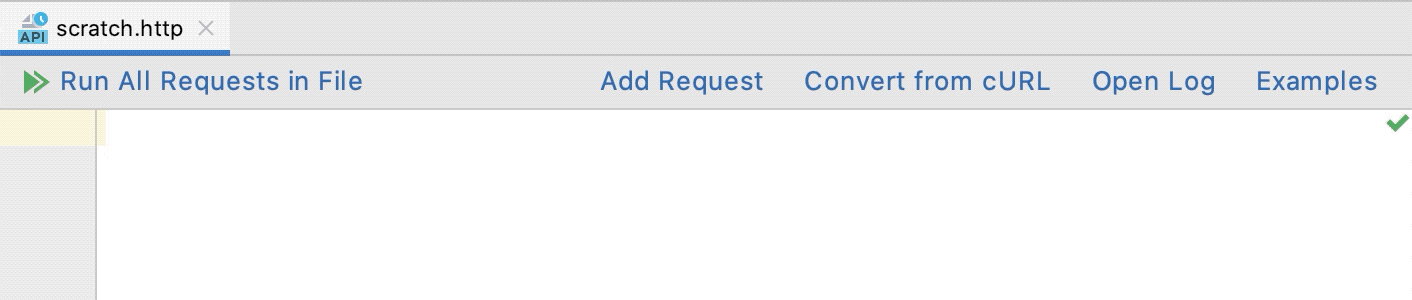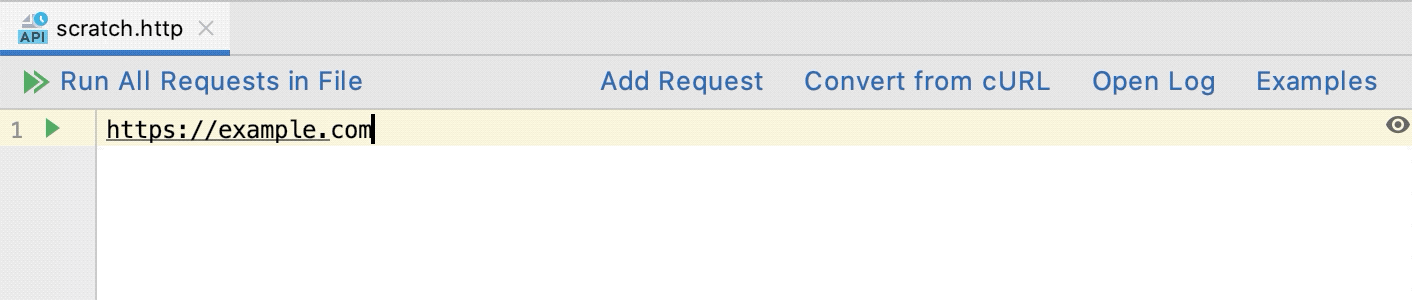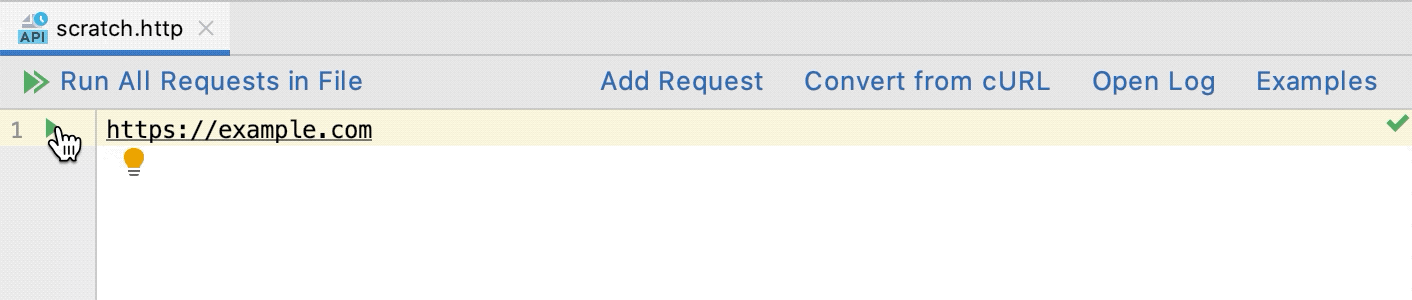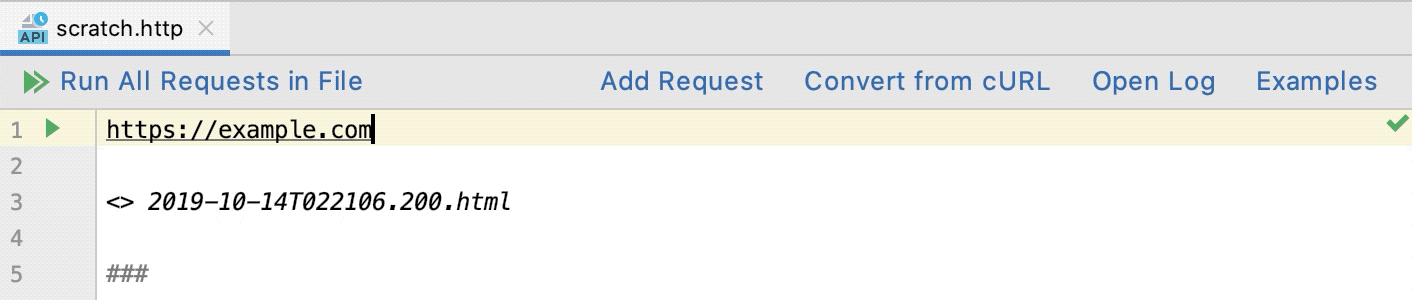 - iTerm2 is a macOS Terminal Replacement that adds some really nice features. Some of our Outlaw’s favorite short-cuts: (iTerm2, Features and Screenshots)
- CMD+D to create a new panel (split vertically)
- CMD+SHIFT+D to create a new panel (split horizontally)
- CMD+Option+arrow keys to navigate between panes
- CMD+Number to navigate between tabs
- Ruler Hack – An architect scale ruler is a great way to prevent heat build up on your laptop by giving the hottest parts of the laptop some air to breathe. (Amazon)
- Fizz Buzz Enterprise Edition is a funny, and sadly reminiscent, way of doing FizzBuzz that incorporates all the buzzwords and most abused design patterns that you see in enterprise Code. (GitHub)
- From our friend Jamie Taylor (of DotNet Core Podcast, Tabs ‘n Spaces, and Waffling Taylors), mkcert is a “zero-config” way to easily generate self-signed certificates that your computer will trust. Great for dev! (GitHub)
- Find out more about Jamie on these great shows…
Direct download: coding-blocks-episode-161.mp3
Category: Software Development
-- posted at: 8:55pm EDT
|
|
Sun, 6 June 2021
We dive back into Designing Data-Intensive Applications to learn more about replication while Michael thinks cluster is a three syllable word, Allen doesn’t understand how we roll, and Joe isn’t even paying attention. For those that like to read these show notes via their podcast player, we like to include a handy link to get to the full version of these notes so that you can participate in the conversation at https://www.codingblocks.net/episode160. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
- Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - Thank you to everyone that left us a new review:
- Audible: Ashfisch, Anonymous User (aka András)
The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair Douglas Adams Douglas Adams In this episode, we are discussing Data Replication, from chapter 5 of “Designing Data-Intensive Applications”. Replication in Distributed Systems - When we talk about replication, we are talking about keeping copies of the same data on multiple machines connected by a network
- For this episode, we’re talking about data small enough that it can fit on a single machine
- Why would you want to replicate data?
- Keeping data close to where it’s used
- Increase availability
- Increase throughput by allowing more access to the data
- Data that doesn’t change is easy, you just copy it
- 3 popular algorithms
- Single Leader
- Multi-Leader
- Leaderless
- Well established (1970’s!) algorithms for dealing with syncing data, but a lot data applications haven’t needed replication so the practical applications are still evolving
- Cluster group of computers that make up our data system
- Node each computer in the cluster (whether it has data or not)
- Replica each node that has a copy of the database
- Every write to the database needs to be copied to every replica
- The most common approach is “leader based replication”, two of the algorithms we mentioned apply
- One of the nodes is designated as the “leader”, all writes must go to the leader
- The leader writes the data locally, then sends to data to it’s followers via a “replication log” or “change stream”
- The followers tail this log and apply the changes in the same order as the leader
- Reads can be made from any of the replicas
- This is a common feature of many databases, Postgres, Mongo, it’s common for queues and some file systems as well
Synchronous vs Asynchronous Writes - How does a distributed system determine that a write is complete?
- The system could hang on till all replicas are updated, favoring consistency…this is slow, potentially a big problem if one of the replicas is unavailable
- The system could confirm receipt to the writer immediately, trusting that replicas will eventually keep up… this favors availability, but your chances for incorrectness increase
- You could do a hybrid, wait for x replicas to confirm and call it a quorum
- All of this is related to the CAP theorem…you get at most two: Consistency, Availability and Partition Tolerance
- The book mentions “chain replication” and other variants, but those are still rare
Steps for Adding New Followers - Take a consistent snapshot of the leader at some point in time (most db can do this without any sort of lock)
- Copy the snapshot to the new follower
- The follower connects to the leader and requests all changes since the back-up
- When the follower is fully caught up, the process is complete
Handling Outages - Nodes can go down at any given time
- What happens if a non-leader goes down?
- What does your db care about? (Available or Consistency)
- Often Configurable
- When the replica becomes available again, it can use the same “catch-up” mechanism we described before when we add a new follower
- What happens if you lose the leader?
- Failover: One of the replicas needs to be promoted, clients need to reconfigure for this new leader
- Failover can be manual or automatic
Rough Steps for Failover - Determining that the leader has failed (trickier than it sounds! how can a replica know if the leader is down, or if it’s a network partition?)
- Choosing a new leader (election algorithms determine the best candidate, which is tricky with multiple nodes, separate systems like Apache Zookeeper)
- Reconfigure: clients need to be updated (you’ll sometimes see things like “bootstrap” services or zookeeper that are responsible for pointing to the “real” leader…think about what this means for client libraries…fire and forget? try/catch?
Failover is Hard! - How long do you wait to declare a leader dead?
- What if the leader comes back? What if it still thinks it’s leader? Has data the others didn’t know about? Discard those writes?
- Split brain – two replicas think they are leaders…imagine this with auto-incrementing keys… Which one do you shut down? What if both shut down?
- There are solutions to these problems…but they are complex and are a large source of problems
- Node failures, unreliable networks, tradeoffs around consistency, durability, availability, latency are fundamental problems with distributed systems
Implementation of Replication Logs - 3 main strategies for replication, all based around followers replaying the same changes
Statement-Based Replication - Leader logs every Insert, Update, Delete command, and followers execute them
- Problems
- Statements like NOW() or RAND() can be different
- Auto-increments, triggers depend on existing things happen in the exact order..but db are multi-threaded, what about multi-step transactions?
- What about LSM databases that do things with delete/compaction phases?
- You can work around these, but it’s messy – this approach is no longer popular
- Example, MySQL used to do it
Write Ahead Log Shipping - LSM and B-Tree databases keep an append only WAL containing all writes
- Similar to statement-based, but more low level…contains details on which bytes change to which disk blocks
- Tightly coupled to the storage engine, this can mean upgrades require downtime
- Examples: Postgres, Oracle
Row Based Log Replication - Decouples replication from the storage engine
- Similar to WAL, but a litle higher level – updates contain what changed, deletes similar to a “tombstone”
- Also known as Change Data Capture
- Often seen as an optional configuration (Sql Server, for example)
- Examples: (New MySQL/binlog)
Trigger-Based Replication - Application based replication, for example an app can ask for a backup on demand
- Doesn’t keep replicas in sync, but can be useful
Resources We Like Tip of the Week - A collection of CSS generators for grid, gradients, shadows, color palettes etc. from Smashing Magazine.
- Learn This One Weird ? Trick To Debug CSS (freecodecamp.org)
- Use
tree to see a visualization of a directory structure from the command line. Install it in Ubuntu via apt install tree. (manpages.ubuntu.com) - Initialize a variable in Kotlin with a try-catch expression, like
val myvar: String = try { ... } catch { ... }. (Stack Overflow) - Manage secrets and protect sensitive data (and more with Hashicorp Vault. (Hashicorp)
Direct download: coding-blocks-episode-160.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 23 May 2021
We couldn’t decide if we wanted to gather around the water cooler or talk about some cool APIs, so we opted to do both, while Joe promises there’s a W in his name, Allen doesn’t want to say graph, and Michael isn’t calling out applets. For all our listeners that read this via their podcast player, this episode’s show notes can be found at https://www.codingblocks.net/episode159, where you can join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
- ConfigCat – The feature flag and config management service that lets you turn features ON after deployment or target specific groups of users with different features.
Survey Says News - Thank you all for the latest reviews:
- iTunes: Lp1876
- Audible: Jon, Lee
Overheard around the Water Cooler - Where do you draw the line before you use a hammer to solve every problem?
- When is it worth bringing in another technology?
- Can you have too many tools?
APIs of Interest Joe’s Picks - Video game related APIs
- RAWG – The Biggest Video Game Database on RAWG – Video Game Discovery Service (rawg.io)
- PS: Your favorite video games might have an API:
- Satellite imagery related APIs
- Get into the affiliate game
Allen’s Picks Michael’s Picks - Alpha Vantage – Free Stock APIs (alphavantage.co)
- Why so serious?
- icanhazdadjoke – The largest selection of dad jokes on the Internet (icanhazdadjoke.com)
- Channel your inner Stuart Smalley with affirmations. (affirmations.dev)
- HTTP Cats – The ultimate source for HTTP status code images. (http.cat)
- Relevant call backs from episode 127:
- Random User Generator – A free, open-source API for generating random user data. (randomuser.me)
- Remember the API – Programmer gifts and merchandise (remembertheapi.com)
Resources We Like - ReDoc – OpenAPI/Swagger-generated API Reference Documentation (GitHub)
- Google Earth – The world’s most detailed globe. (google.com/earth)
- Google Sky – Traveling to the stars has never been easier. (google.com/sky)
- apitracker.io – Discover the best APIs and SaaS products to integrate with. (apitracker.io)
- ProgrammableWeb – The leading source of news and information about Internet-based APIs.(ProgrammableWeb.com)
- NASA APIs – NASA data, including imagery, accessible to developers. (api.nasa.gov)
- RapidAPI – The Next-Generation API Platform (rapidapi.com)
- Stuart Smalley (Wikipedia)
- Al Franken (Wikipedia)
- Muzzle – A simple Mac app to silence embarrassing notifications while screensharing. (MuzzleApp.com)
Tip of the Week - Not sure what project to do? Google for an API or check out RapidAPI for a consistent way to farm ideas:
- Press F12 in Firefox, Chrome, or Edge, then go to the Elements tab (or Inspector in Firefox) to start hacking away at the DOM for immediate prototyping.
- All things K9s
- Getting Started with K9s – A Love Letter to K9s
- Use K9s to easily monitor your Kubernetes cluster
- Not only does K9s support skins and themes, but supports *cluster specific* skins (k9scli.io)
- If you like xkcd, Monkey User is for you!
- xkcd – A webcomic of romance, sarcasm, math, and language. (xkcd.com)
- Monkey User – Created out of a desire to bring joy to people working in IT. (MonkeyUser.com)
- Remap Windows Terminal to use CTRL+D, another keyboard customizations. (docs.microsoft.com)
- PostgreSQL and Foreign Data (postgresql.org)
- Cheerio – Fast, flexible & lean implementation of core jQuery designed specifically for the server. (npmjs.com)
- JetBrains MPS (Meta Programming System) – Create your own domain-specific language (JetBrains)
- Case study – Domain-specific languages to implement Dutch tax legislation and process changes of that legislation. (JetBrains)
Direct download: coding-blocks-episode-159.mp3
Category: Software Development
-- posted at: 10:14pm EDT
|
|
Sun, 9 May 2021
We talk about the various ways we can get paid with code while Michael failed the Costco test, Allen doesn’t understand multiple choice questions, and Joe has a familiar pen name. This episode’s show notes can be found at https://www.codingblocks.net/episode158, where you can join the conversation, for those reading this via their podcast player. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Thank you all for the latest reviews:
- iTunes: PriestRabbitWalkIntoBloodBank, Sock-puppet Sophist sez, Rogspug, DhokeDev, Dan110024
- Audible: Aiden
Show Me the Money Active Income - Active income is income earned by exchanging time for money. This typically includes salary and hourly employment, as well as contracting.
- Some types of active income blur the lines.
- Way to find active income can include job sites like Stack Overflow Jobs, Indeed, Upwork, etc.
- Government grants and jobs are out there as well.
- Active income is typically has some ceiling, such as your time.
Passive Income - Passive income is income earned on an investment, any kind of investment, such as stock markets, affiliate networks, content sales for things like books, music, courses, etc.
- The work you do for the passive income can blur lines, especially when that work is promotion.
- Passive income is generally not tied to your time.
Passive Income Options - Create a SaaS platform to keep people coming back. Don’t let the term SaaS scare you off. This can be something smaller like a regex validator.
- Affiliate links are a great example of passive income because you need to invest the time once to create the link.
- Ads and sponsors: typically, the more targeted the audience is for the ad, the more the ad is worth.
- Donations via services like Ko-fi, Patreon, and PayPal.
- Apps, plugins, website templates/themes
- Create content, such as books, courses, videos, etc. Self-publishing can have a bigger reward and offer more freedom, but doesn’t come with the built-in audience and marketing team that a publisher can offer.
- Arbitrage between markets.
- Grow an audience, be it on YouTube, Twitch, podcasting, blogging, etc.
Things to Consider - What’s the up-front effort and/or investment?
- How much maintenance can you afford?
- How much will it cost you?
- Who gets hurt if you choose to quit?
- What can you realistically keep up with?
- What are the legal and tax liabilities?
Resources We Like Tip of the Week - Google developer documentation style guide: Word list (developers.google.com)
- In Windows Terminal, use
CTRL+SHIFT+W to close a tab or the window. - The GitHub CLI manual (cli.github.com)
- Use
gh pr create --fill to create a pull request using your last commit message as the title and body of the PR. - We’ve discussed the GitHub CLI in episode 142 and episode 155.
- How to get a dependency tree for an artifact? (Stack Overflow)
- xltrail – Version control for Excel workbooks (xltrail.com)
- Spring Initializr (start.spring.io)
- You can leverage the same thing in IntelliJ with Spring.
Direct download: coding-blocks-episode-158.mp3
Category: Software Development
-- posted at: 11:16pm EDT
|
|
Sun, 25 April 2021
We discuss all things APIs: what makes them great, what makes them bad, and what we might like to see in them while Michael plays a lawyer on channel 46, Allen doesn’t know his favorite part of the show, and Joe definitely pays attention to the tips of the week. For those reading this episode’s show notes via their podcast player, you can find this episode’s show notes at https://www.codingblocks.net/episode157 where you can be a part of the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Big thanks to everyone that left us a new review:
- iTunes: hhskakeidmd
- Audible: Colum Ferry
All About APIs What are APIs? - API stands for application programming interface and is a formal way for applications to speak to each other.
- An API defines requests that you can make, what you need to provide, and what you get back.
- If you do any googling, you’ll see that articles are overwhelmingly focused on Web APIs, particularly REST, but that is far from the only type. Others include:
- All libraries,
- All frameworks,
- System Calls, i.e.: Windows API,
- Remote API (aka RPC – remote procedure call),
- Web related standards such as SOAP, REST, HATEOAS, or GraphQL, and
- Domain Specific Languages (SQL for example)
- The formal definition of APIs, who own them, and what can be done with them is complicated à la Google LLC v. Oracle America, Inc.
- Different types of API have their own set of common problems and best practices
- Common REST issues:
- Authentication,
- Rate limiting,
- Asynchronous operations,
- Filtering,
- Sorting,
- Pagination,
- Caching, and
- Error handling.
- Game libraries:
- Heavy emphasis on inheritance and “hidden” systems to cut down on complexity.
- Libraries for service providers
- Support multiple languages and paradigms (documentation, versioning, rolling out new features, supporting different languages and frameworks)
- OData provides a set of standards for building and consuming REST API’s.
General tips for writing great APIs - Make them easy to work with.
- Make them difficult to misuse (good documentation goes a long way).
- Be consistent in the use of terms, input/output types, error messages, etc.
- Simplicity: there’s one way to do things. Introduce abstractions for common actions.
- Service evolution, i.e. including the version number as part of your API call enforces good versioning habits.
- Documentation, documentation, documentation, with enough detail that’s good to ramp up from getting started to in depth detail.
- Platform Independence: try to stay away from specifics of the platforms you expect to deal with.
Why is REST taking over the term API? - REST is crazy popular in web development and it’s really tough to do anything without it.
- It’s simple. Well, not really if you consider the 43 things you need to think about.
- Some things about REST are great by design, such as:
- By using it, you only have one protocol to support,
- It’s verb oriented (commonly used verbs include
GET, POST, PUT, PATCH, and DELETE), and - It’s based on open standards.
- Some things about REST are great by convention, such as:
- Noun orientation like resources and identifiers,
- Human readable I/O,
- Stateless requests, and
- HATEOAS provides a methodology to decouple the client and the server.
Maybe we can steal some ideas from REST - Organize the API around resources, like
/orders + verbs instead of /create-order. - Note that nouns can be complex, an order can be complex … products, addresses, history, etc.
- Collections are their own resources (i.e.
/orders could return more than 1). - Consistent naming conventions makes for easy discovery.
- Microsoft recommends plural nouns in most cases, but their skewing heavily towards REST, because REST already has a mechanism for behaviors with their verbs. For example
/orders and /orders/123. - You can drill in further and further when you orient towards nouns like
/orders/123/status. - The general guidance is to return resource identifiers rather than whole objects for complex nouns. In the order example, it’s better to return a customer ID associated with the whole order.
- Avoid introducing dependencies between the API and the underlying data sources or storage, the interface is meant to abstract those details!
- Verb orientation is okay in some, very action based instances, such as a calculator API.
Resources We Like Tip of the Week - Docker Desktop: WSL 2 Best practices (Docker)
- Experiencing déjà vu? That’s because we talked about this during episode 156.
- With Minikube, you can easily configure the amount of CPU and RAM each time you start it.
- Listen to American Scandal. A great podcast with amazing production quality. (Wondery)
- If you have a license for DataGrip and use other JetBrains IDEs, once you add a data source, the IDE will recognize strings that are SQL in your code, be they Java, JS, Python, etc., and give syntax highlighting and autocomplete.
- Also, you can set the connection to a DB in DataGrip as read only under the options. This will give you a warning message if you try a write operation even if your credentials have write permissions.
- API Blueprint. A powerful high-level API description language for web APIs. (apiblueprint.org)
- Apache Superset – A modern data exploration and visualization platform. (Apache)
- Use console.log() like a pro. (markodenic.com)
- Turns out we did discuss something similar to this back in episode 44.
- Telerik Fiddler – A must have web debugging tool for your web APIs. (Telerik)
- New Docker Build secret information (docs.docker.com)
Direct download: coding-blocks-episode-157.mp3
Category: Software Development
-- posted at: 8:51pm EDT
|
|
Sun, 11 April 2021
We discuss the parts of the scrum process that we’re supposed to pay attention to while Allen pronounces the m, Michael doesn’t, and Joe skips the word altogether. If you’re reading this episode’s show notes via your podcast player, just know that you can find this episode’s show notes at https://www.codingblocks.net/episode156. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Hey, we finally updated the Resources page. It only took a couple years.
- Apparently we don’t understand the purpose of the scrum during rugby. (Wikipedia)
Standup Time User Stories - A user story is a detailed, valuable chunk of work that can be completed in a sprint.\
- Use the INVEST mnemonic created by Bill Wake:
- I = Independent – the story should be able to be completed without any dependencies on another story
- N = Negotiable – the story isn’t set in stone – it should have the ability to be modified if needed
- V = Valuable – the story must deliver value to the stakeholder
- E = Estimable – you must be able to estimate the story
- S = Small – you should be able to estimate within a reasonable amount of accuracy and completed within a single sprint
- T = Testable – the story must have criteria that allow it to be testable
Stories Should be Written in a Format Very Much Like… “As a _____, I want _____ so that _____.”, like
“As a user, I want MFA in the user profile so I can securely log into my account” for a functional story, or
“As a developer, I want to update our version of Kubernetes so we have better system metrics” for a nonfunctional story. Stories Must have Acceptance Criteria - Each story has it’s own UNIQUE acceptance criteria.
- For the MFA story, the acceptance criteria might be:\
- Token is captured and saved.
- Verification of code completed successfully.
- Login works with new MFA.
- The acceptance criteria defines what “done” actually means for the story.
Set up Team Boundaries - Define “done”.
- Same requirement for ALL stories:
- Must be tested in QA environment,
- Must have test coverage for new methods.
- Backlog prioritization or “grooming”.
- Must constantly be ordered by value, typically by the project owner.
- Define sprint cadence
- Usually 1-4 weeks in length, 2-3 is probably best.
- Two weeks seems to be what most choose simply because it sort of forces a bit of urgency on you.
Estimates - Actual estimation, “how many hours will a task take?”
- Relative estimation, “I think this task will take 2x as long as this other ticket.”
- SCRUM uses both, user stories are compared to each other in relative fashion.
- By doing it this way, it lets external stakeholders know that it’s an estimate and not a commitment.
- Story points are used to convey relative sizes.
- Estimation is supposed to be lightweight and fast.
Roadmap and Release Plan - The roadmap shows when themes will be worked on during the timeframe.\
- You should be able to have a calendar and map your themes across that calendar and in an order that makes sense for getting a functional system.
- Just because you should have completed, functional components at the end of each sprint, based on the user stories, that doesn’t mean you’re releasing that feature to your customer. It may take several sprints before you’ve completed a releasable feature.
- It will take several sprints to find out what a team’s stabilized velocity is, meaning that the team will be able to decently predict how many story points they can complete in a given sprint.
Filling up the Sprint - Decide how many points you’ll have for a sprint.
- Determine how many sprints before you can release the MVP.
- Fill up the sprints as full as possible in priority order UNLESS the next priority story would overflow the sprint.
- Simple example, let’s say your sprint will have 10 points and you have the following stories:
Story A – 3 points
Story B – 5 points
Story C – 8 points
Story D – 2 points - Your sprints might look like:
Sprint 1 – A (3) B(5), D(2) = 10 points
Sprint 2 – C (8) - Story C got bumped to Sprint 2 because the goal is to maximize the amount of work that can be completed in a given sprint in priority order, as much as possible.
- The roadmap is an estimate of when the team will complete the stories and should be updated at the end of each sprint. In other words, the roadmap is a living document.
Sprint Planning - This is done at the beginning of each sprint.
- Attendees – all developers, scrum master, project owner.
- Project owner should have already prioritized the stories in the backlog.
- The goal of the planning meeting is to ensure all involved understand the stories and acceptance criteria.
- Also make sure the overarching definition of “done” is posted as a reminder.
- Absolutely plan for a Q&A session.
- Crucial to make sure any misunderstandings of the stories are cleared here.
- Next the stories are broken down into specific tasks. These tasks are given actual estimates in time.
- Once this is completed, you need to verify that the team has enough capacity to complete the tasks and stories in the sprint.
- In general, each team member can only complete 6 hours of actual work per day on average.
- Each person is then asked whether they commit to the work in the sprint.
- Must give a “yes” or “no” and why.
- If someone can’t commit with good reason, the the project owner and team need to work together to modify the sprint so that everyone can commit. This is a highly collaborative part of scrum planning.
Stakeholder Feedback - Information radiators are used to post whatever you think will help inform the stakeholders of the progress, be it a task board or burn down chart.
Task board - Lists stories committed to in the sprint.
- Shows the status of any current tasks.
- Lists which tasks have been completed.
- Swimlanes are typically how these are depicted with lanes like: Story, Not Started, In Progress, Completed.
Sprint burndown chart - Shows ongoing status of how you’re doing with completing the sprint.
Daily Standup - The purpose of the standup is the three C’s:\
- Collaboration,
- Communication, and
- Cadence.
- The entire team must join: developers, project owner, QA, scrum master.
- Should occur at the same time each day.
- Each status should just be an overview and light on the details.
- Tasks are moved to a new state during the standup, such as from Not Started to In Progress.
- Stakeholders can come to the scrum but should hold questions until the end.
- Cannot go over 15 minutes. It can be shorter, but should not be longer.
- Each person should answer three questions:
- What did you do yesterday?,
- What are you doing today?, and
- Are there any blockers?
- If you see someone hasn’t made progress in several days, this is a great opportunity to ask to help. This is part of keeping the team members accountable for progressing.
- Blockers are brought up during the meeting as anyone on the team needs to try and step in to help. If the issue hasn’t been resolved by the next day, then it’s the responsibility of the scrum master to try and resolve it, and escalate it further up the chain after that, such as to the project owner and so on, each consecutive day.
- Again, very important, this is just the formal way to keep the entire team aware of the progress. People should be communicating throughout the day to complete whatever tasks they’re working on.
Backlog Refinement - The backlog is constantly changing as the business requirements change.
- It is the job of the project owner to be in constant communication with the stakeholders to ensure the backlog represents the most important needs of the business and making sure the stories are prioritized in value order.
- Stories are constantly being modified, added, or removed.
- Around the midpoint of the sprint, there is usually a 30-60 minute “backlog refinement session” where the team comes together to discuss the changes in the backlog.
- These new stories can only be added to future sprints.
- The current sprint commitment cannot be changed once the sprint begins.
- The importance of this mid-sprint session is the team can ask clarifying questions and will be better prepared for the upcoming sprint planning.
- This helps the project owner know when there are gaps in the requirements and helps to improve the stories.
Marking a Story Done - The project owner has the final say making sure all the acceptance criteria has been met.
- There could be another meeting called the “sprint review” where the entire team meets to get signoff on the completed stories.
- Anything not accepted as done gets reviewed, prioritized, and moved out to another sprint.
- This can happen when a team discovers new information about a story while working on it during a sprint.
- The team agrees on what was completed and what can be demonstrated to the stakeholders.
The Demo - This is a direct communication between the team and the stakeholders and receive feedback.
- This may result in new stories.
- Stakeholders may not even want the new feature and that’s OK. It’s better to find out early rather than sinking more time into building something not needed or wanted.
- This is a great opportunity to build a relationship between the team members and the stakeholders.
- This demo also shows the overall progress towards the final goal.
- May not be able to demo at the end of every sprint, but you want to do it as often as possible.
Team Retrospective - Focus is on team performance, not the product and is facilitated by the scrum master.
- This is a closed door session and must be a safe environment for discussion.
- Only dedicated team members present and the team norms must be observed
- You want an open dialogue/
- What worked well? Focus on good team collaboration.
- What did not work well? Focus on what you can actually change.
- What can be improved?
- Put items into an improvement backlog
- Focus on one or two items in the next sprint
- Start with team successes first!
Resources We Like Tip of the Week - Test your YAML with the Ansible Template Tester (ansible.sivel.net)
- Hellscape by Andromida (Spotify, YouTube)
- Use
ALT+LEFT CLICK in Windows Terminal to open a new terminal in split screen mode. - Learn how to tie the correct knot for every situation! (animatedknots.com)
- Apply zoom levels to each tab independently of other tabs of the same website with Per Tab Zoom. (Chrome web store)
- Nearly every page on GitHub has a keyboard shortcut to perform actions faster. Learn them! (GitHub)
- Speaking of shortcuts, here’s a couple for Visual Studio Code:
- Use
CTRL+P (or CMD+P on a Mac) to find a file by name or path. - List (and search) all available commands with
CTRL+SHIFT+P (or CMD+SHIFT+P on a … you know). - Use
CTRL+K M (CMD+K M) to change the current document’s language mode. - Access your WSL2 filesystem from Windows using special network share: like
\\wsl$\ubuntu_instance_name\home\your_username\some_path - Docker Desktop: WSL 2 Best practices (Docker)
Direct download: coding-blocks-episode-156.mp3
Category: Software Development
-- posted at: 10:26pm EDT
|
|
Sun, 28 March 2021
During today’s standup, we focus on learning all about Scrum as Joe is back (!!!), Allen has to dial the operator and ask to be connected to the Internet, and Michael reminds us why Blockbuster failed. If you didn’t know and you’re reading these show notes via your podcast player, you can find this episode’s show notes in their original digital glory at https://www.codingblocks.net/episode155 where you can also jump in the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Thank you all for the reviews:
- iTunes: DareOsewa, Miggybby, MHDev, davehadley, GrandMasterJR, Csmith49, ForTheHorde&Tacos, A-Fi
- Audible: Joshua, Alex
Do You Even Scrum? Why Do We Call it Scrum Anyways? Comes from the game of Rugby. A scrummage is when a team huddles after a foul to figure out their next set of plays and readjust their strategy. Why is Scrum the Hot Thing? - Remember waterfall?
- Plan and create documentation for a year up front, only to build a product with rigid requirements for the next year. By the time you deliver, it may not even be the right product any longer.
- Waterfall works for things that have very repeatable steps, such as things like planning the completion of a building.
- It doesn’t work great for things that require more experimentation and discovery.
- Project managers saw the flaw in planning for the complete “game” rather than planning to achieve each milestone and tackle the hurdles as they show up along the way.
- Scrum breaks the deliverables and milestones into smaller pieces to deliver.
The Core Tenants of Scrum - Having business partners and stakeholders work with the development of the software throughout the project,
- Measure success using completed software throughout the project, and
- Allow teams to self-organize.
Scrum Wants You to Fail Fast - Failure is ok as long as you’re learning from it.
- But those lessons learned need to happen quickly, with fast feedback cycles.
- Small scale focus and rapid learning cycles.
- In other words, fail fast really means “learn fast”.
It’s super important to recognize that Scrum is *not* prescriptive. It’s more like guardrails to a process. An Overview of the Scrum Framework - The product owner has a prioritized backlog of work for the team.
- Every sprint, the team looks at the backlog and decides what they can accomplish during that sprint, which is generally 2-3 weeks.
- The team develops and tests their solutions until completed. This effort needs to happen within that sprint.
- The team then demonstrates their finished product to the product owner at the end of the sprint.
- The team has a retrospective to see how the sprint went, what worked, and what they can improve going forward.
Focusing on creating a completed, demo-able piece of work in the sprint allows the team to succeed or fail/learn fast. Projects are typically comprised of three basic things: time, cost, and scope. Usually time and cost are fixed, so all you can work with is the scope. There are Two Key Roles Within Scrum - Project owner – The business representative dedicated 100% to the team.
- Acts as a full time business representative.
- Reviews the team’s work constantly to ensure the proper deliverable is being created.
- Interacts with the stakeholders.
- Is the keeper of the product vision.
- Responsible for making sure the work is continuously sorted per the ongoing business needs.
- The Scrum master – Responsible for helping resolve daily issues and balance ongoing changes in requirements and/or scope.
- This person has a mastery of Scrum.
- Also helps improve internal team processes.
- Responsible for protecting the team and their processes.
- Balances the demands of the product owner and the needs of the team.
- This means keeping the team working at a sustainable rate.
- Acts as the spokesperson for the entire team.
- Provides charts and other views into the progress for others for transparency.
- Responsible for removing any blockers.
Project owner focuses on what needs to be done while the Scrum master focuses on how the team gets it done. Scrum doesn’t value heroics by teams or team members. Scrum is all about Daily Collaboration - Whatever you can do to make daily collaboration easier will yield great benefits.
- Collocate your team if possible.
- If you can’t do that, use video conferencing, chat, and/or conference calls to keep communication flowing.
The Team Makeup - You must have a dedicated team. If members of your team are split amongst different projects, it will be difficult to accomplish your goals as you lose efficiency.
- The ideal team size is 5 to 9 members.
- You want a number of T-shaped developers.
- These are people can work on more than one type of deliverable.
- You also need some “consultants” you may be able to call on that have more specialized/focused skillsets that may not be core members of the team.
Team Norms - Teams will need to have standard ways of dealing with situations.
- How people will work together.
- How they’ll resolve conflicts.
- How to come to a consensus.
- Must have full team buy-in and everyone must be willing to hold each other accountable.
Agree to disagree, but move forward with agreed upon solution. Product Vision - It’s the map for your team, it’s what tells you how to get where you want to go.
- This must be established by the project owner.
- The destination should be the “MVP”, i.e. the Minimum Viable Product.
- Why MVP? By creating just enough to get it out to the early adopters allows you to get feedback early.
- This allows for a fast feedback cycle.
- Minimizes scope creep.
- Must set the vision, and then decompose it.
Break the Vision Down into Themes - Start with a broad grouping of similar work.
- Allows you to be more efficient by grouping work together in similar areas.
- This also allows you to think about completing work in the required order.
Once You’ve Identified the Themes, You Break it Down Further into Features If you had a theme of a User Profile, maybe your features might be things like: - Change password,
- Setup MFA, and
- Link social media.
To get the MVP out the door, you might decide that only the Change Password feature is required. Resources We Like Tip of the Week - Learn and practice your technical writing skills.
- Online Technical Writing: Contents, Free Online Textbook for Technical Writing (prismnet.com)
- Using k9s makes running your Kubernetes cronjobs on demand super easy. Find the cronjob you want to run (hint:
:cronjobs) and then use CTRL+T to execute the cronjob now. (GitHub) - Windows Terminal is your new favorite terminal. (microsoft.com)
- TotW redux: GitHub CLI – Your new favorite way to interact with your GitHub account, be it public GitHub or GitHub Enterprise. (GitHub)
- Joe previously mentioned the GitHub CLI as a TotW (episode 142)
- Grep Console – grep, tail, filter, and highlight … everything you need for a console, in your JetBrains IDE. (plugins.jetbrains.com)
- Use
my_argument:true when calling pwsh to pass boolean values to your Powershell script. - JetBrains allows you to prorate your license upgrades at any point during your subscription.
Direct download: coding-blocks-episode-155.mp3
Category: Software Development
-- posted at: 9:18pm EDT
|
|
Sun, 14 March 2021
We dig into recursion and learn that Michael is the weirdo, Joe gives a subtle jab, and Allen doesn’t play well with others while we dig into recursion. This episode’s show notes can be found at https://www.codingblocks.net/episode154, for those that might be reading this via their podcast player. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
News - Thank you all for the reviews:
- iTunes: ripco55, Jla115
- Audible: _onetea, Marnu, Ian
Here I Go Again On My Own What is Recursion? - Recursion is a method of solving a problem by breaking the problem down into smaller instances of the same problem.
- A simple “close enough” definition: Functions that call themselves
- Simple example:
fib(n) { n <= 1 ? n : fib(n - 1) + fib(n - 2) } - Recursion pros:
- Elegant solutions that read well for certain types of problems, particularly with unbounded data.
- Work great with dynamic data structures, like trees, graphs, linked lists.
- Recursion cons:
- Tricky to write.
- Generally perform worse than iterative solutions.
- Runs the risk of stack overflow errors.
- Recursion is often used for sorting algorithms.
How Functions Roughly Work in Programming Languages - Programming languages generally have the notion of a “call stack”.
- A stack is a data structure designed for LIFO. The call stack is a specialized stack that is common in most languages
- Any time you call a function, a “frame” is added to the stack.
- The frame is a bucket of memory with (roughly) space allocated for the input arguments, local variables, and a return address.
- Note: “value types” will have their values duplicated in the stack and reference types contain a pointer.
- When a method “returns”, it’s frame is popped off of the stack, deallocating the memory, and the instructions from the previous function resume where it left off.
- When the last frame is popped off of the call stack, the program is complete.
- The stack size is limited. In C#, the size is 1MB for 32-bit processes and 4MB for 64-bit processes.
- You can change these values but it’s not recommended!
- When the stack tries to exceed it’s size limitations, BOOM! … stack overflow exception!
- How big is a frame? Roughly, add up your arguments (values + references), your local variables, and add an address.
- Ignoring some implementation details and compiler optimizations, a function that adds two 32b numbers together is going to be roughly 96b on the stack: 32 * 2 + return address.
- You may be tempted to “optimize” your code by condensing arguments and inlining code rather than breaking out functions… don’t do this!
- These are the very definition of micro optimizations. Your compiler/interpreter does a lot of the work already and this is probably not your bottleneck by a longshot. Use a profiler!
- Not all languages are stack based though: Stackless Python (kinda), Haskell (graph reduction), Assembly (jmp), Stackless C (essentially inlines your functions, has limitations)
The Four Memory Segments  source: Quora How Recursive Functions Work - The stack doesn’t care about what the return address is.
- When a function calls any other function, a frame is added to the stack.
- To keep things simple, suppose for a Fibonacci sequence function, the frame requires 64b, 32b for the argument and 32b for the return address.
- Every Fibonacci call, aside from 0 or 1, adds 2 frames to the stack. So for the 100th number we will allocate .6kb (1002 * 32). And remember, we only have 1mb for everything.
- You can actually solve Fibonacci iteratively, skipping the backtracking.
- Fibonacci is often given as an example of recursion for two reasons:
- It’s relatively easy to explain the algorithm, and
- It shows the danger of this approach.
What is Tail Recursion? - The recursive Fibonacci algorithm discussed so far relies on backtracking, i.e. getting to the end of our data before starting to wind back.
- If we can re-write the program such that the last operation, the one in “tail position” is the ONLY recursive call, then we no longer need the frames, because they are essentially just pass a through.
- A smart compiler can see that there are no operations left to perform after the next frame returns and collapse it.
- The compiler will first remove the last frame before adding the new one.
- This means we no longer have to allocate 1002 extra frames on the stack and instead just 1 frame.
- A common approach to rewriting these types of problems involves adding an “accumulator” that essentially holds the state of the operation and then passing that on to the next function.
- The important thing here, is that the your ONE AND ONLY recursive call must be the LAST operation … all by itself.
Joe’s (Un)Official Recursion Tips - Start with the end.
- Do it by hand.
- Practice, practice, practice.
Joe Recursion Joe’s Motivational Script 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #!/usr/bin/env python3 import sys def getname(arg): print(f"{arg}") if arg == 'Joe': getname('Recursion') else: getname('Joe') return if __name__ == "__main__": sys.setrecursionlimit(500) print(f"Who is awesome?") try: getname('Joe') except: print("You got this!") | Recap - Recursion is a powerful tool in programming.
- It can roughly be defined as a function that calls itself.
- It’s great for dynamic/unbounded data structures like graphs, trees, or linked lists.
- Recursive functions can be memory intensive and since the call stack is limited, it is easy to overflow.
- Tail call optimization is a technique and compiler trick that mitigates the call stack problem, but it requires language support and that your recursive call be the last operation in your function.
- FAANG-ish interviews love recursive problems, and they love to push you on the memory.
Resources We Like - Recursion (computer science) (Wikipedia)
- Dynamic Programming (LeetCode)
- Grokking Dynamic Programming Patterns for Coding Interviews (educative.io)
- Boxing and Unboxing in .NET (episode 2)
- IDA EBP variable offset (Stack Exchange)
- What is the difference between the stack and the heap? (Quora)
- Data Structures – Arrays and Array-ish (episode 95)
- Function Calls, Part 3 (Frame Pointer and Local Variables) (codeguru.com)
- How to implement the Fibonacci sequence in Python (educative.io)
- Tail Recursion for Fibonacci (GeeksforGeeks.org)
- Recursion (GeeksforGeeks.org)
- Structure and Interpretation of Computer Programs (MIT)
- Tail Recursion Explained – Computerphile (YouTube)
- !!Con 2019- Tail Call Optimization: The Musical!! by Anjana Vakil & Natalia Margolis (YouTube)
Tip of the Week - How to take good care of your feet (JeanCoutu.com)
- Be sure to add
labels to your Kubernetes objects so you can later use them as your selector. (kubernetes.io) - Example:
kubectl get pods --selector=app=nginx - Security Now!, Episode 808 (twit.tv, grc.com)
Direct download: coding-blocks-episode-154.mp3
Category: Software Development
-- posted at: 10:10pm EDT
|
|
Sun, 28 February 2021
It’s been a minute since we last gathered around the water cooler, as Allen starts an impression contest, Joe wins said contest, and Michael earned a participation award. For those following along in their podcast app, this episode’s show notes can be found at https://www.codingblocks.net/episode153. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- DataStax – Sign up today to get $300 in credit with promo code
CODINGBLOCKS and make something amazing with Cassandra on any cloud. Survey Says News - Thank you all for the latest reviews:
- iTunes: peter b :(, Jackifus, onetea_
- Getting BSOD? Test your memory with MemTest86.
Gather Around the Water Cooler - Go deep on a single language? Or know enough about many of them?
- Who is hiring for remote work?
- Remote job resources:
- What companies are in your top 3?
- Know your storage technology. What it excels at and what it doesn’t.
Resources We Like Tip of the Week - Automated Google Cloud Platform Authentication with minikube.
- Calvin and Hobbes the Search Engine (MichaelYingling.com)
- 11 Facts About Real-World Container Use (Datadog)
- Tips & Tricks for running Strimzi with kubectl (Strimzi)
Direct download: coding-blocks-episode-153.mp3
Category: Software Development
-- posted at: 8:29pm EDT
|
|



