Sun, 21 November 2021
We wrap up the discussion on partitioning from our collective favorite book, Designing Data-Intensive Applications, while Allen is properly substituted, Michael can’t stop thinking about Kafka, and Joe doesn’t live in the real sunshine state. The full show notes for this episode are available at https://www.codingblocks.net/episode172. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Game Ja Ja Ja Jam is coming up, sign up is open now! (itch.io)
- Joe finished the Create With Code Unity Course (learn.unity.com)
- New MacBook Pro Review, notch be darned!
Last Episode …  Best book evar! Best book evar! In our previous episode, we talked about data partitioning, which refers to how you can split up data sets, which is great when you have data that’s too big to fit on a single machine, or you have special performance requirements. We talked about two different partitioning strategies: key ranges which works best with homogenous, well-balanced keys, and also hashing which provides a much more even distribution that helps avoid hot-spotting. This episode we’re continuing the discussion, talking about secondary indexes, rebalancing, and routing. Partitioning, Part Deux Partitioning and Secondary Indexes - Last episode we talked about key range partitioning and key hashing to deterministically figure out where data should land based on a key that we chose to represent our data.
- But what happens if you need to look up data by something other than the key?
- For example, imagine you are partitioning credit card transactions by a hash of the date. If I tell you I need the data for last week, then it’s easy, we hash the date for each day in the week.
- But what happens if I ask you to count all the transactions for a particular credit card?
- You have to look at every single record. in every single partition!
- Secondary Indexes refer to metadata about our data that help keep track of where our data is.
- In our example about counting a user’s transactions in a data set that is partitioned by date, we could keep a separate data structure that keeps track of which partitions each user has data in.
- We could even easily keep a count of those transactions so that you could return the count of a user’s transaction solely from the information in the secondary index.
- Secondary indexes are complicated. HBase and Voldemort avoid them, while search engines like Elasticsearch specialize in them.
- There are two main strategies for secondary indexes:
- Document based partitioning, and
- Term based partitioning.
Document Based Partitioning - Remember our example dataset of transactions partitioned by date? Imagine now that each partition keeps a list of each user it holds, as well as the key for the transaction.
- When you query for users, you simply ask each partition for the keys for that user.
- Counting is easy and if you need the full record, then you know where the key is in the partition. Assuming you store the data in the partition ordered by key, it’s a quick lookup.
- Remember Big O? Finding an item in an ordered list is
O(log n). Which is much, much, much faster than looking at every row in every partition, which is O(n). - We have to take a small performance hit when we insert (i.e. write) new items to the index, but if it’s something you query often it’s worth it.
- Note that each partition only cares about the data they store, they don’t know anything about what the other partitions have. Because of that, we call it a local index.
- Another name for this type of approach is “scatter/gather”: the data is scattered as you write it and gathered up again when you need it.
- This is especially nice when you have data retention rules. If you partition by date and only keep 90 days worth of data, you can simply drop old partitions and the secondary index data goes with them.
Term Based Partitioning - If we are willing to make our writes a little more complicated in exchange for more efficient reads, we can step up to term based partitioning.
- One problem with having each partition keeping track of their local data is you have to query all the partitions. What if the data’s only on one partition? Our client still needs to wait to hear back from all partitions before returning the result.
- What if we pulled the index data away from the partitions to a separate system?
- Now we check this secondary index to figure out the keys, which we can then go look up on the appropriate indices.
- We can go one step further and partition this secondary index so it scales better. For example,
userId 1-100 might be on one, 101-200 on another, etc. - The benefit of term based partitioning is you get more efficient reads, the downside is that you are now writing to multiple spots: the node the data lives on and any partitions in our indexing system that we need to account for any secondary indexes. And this is multiplied by replication.
- This is usually handled by asynchronous writes that are eventually consistent. Amazon’s DynamoDB states it’s global secondary indexes are updated within a fraction of a second normally.
Rebalancing Partitions - What do you do if you need to repartition your data, maybe because you’re adding more nodes for CPU, RAM, or losing nodes?
- Then it’s time to rebalance your partitions, with the goals being to …
- Distribute the load equally-ish (notice we didn’t say data, could have some data that is more important or mismatched nodes),
- Keep the database operational during the rebalance procedure, and
- Minimize data transfer to keep things fast and reduce strain on the system.
- Here’s how not to do it:
hash % (number of nodes) - Imagine you have 100 nodes, a key of 1000 hashes to 0. Going to 99 nodes, that same key now hashes to 1, 102 nodes and it now hashes to 4 … it’s a lot of change for a lot of keys.
Partitions > Nodes - You can mitigate this problem by fixing the number of partitions to a value higher than the number of nodes.
- This means you move where the partitions go, not the individual keys.
- Same recommendation applies to Kafka: keep the numbers of partitions high and you can change nodes.
- In our example of partitioning data by date, with a 7 years retention period, rebalancing from 10 nodes to 11 is easy.
- What if you have more nodes than partitions, like if you had so much data that a single day was too big for a node given the previous example?
- It’s possible, but most vendors don’t support it. You’ll probably want to choose a different partitioning strategy.
- Can you have too many partitions? Yes!
- If partitions are large, rebalancing and recovering from node failures is expensive.
- On the other hand, there is overhead for each partition, so having many, small partitions is also expensive.
Other methods of partitioning - Dynamic partitioning:
- It’s hard to get the number of partitions right especially with data that changes it’s behavior over time.
- There is no magic algorithm here. The database just handles repartitioning for you by splitting large partitions.
- Databases like HBase and RethinkDB create partitions dynamically, while Mongo has an option for it.
- Partitioning proportionally to nodes:
- Cassandra and Ketama can handle partitioning for you, based on the number of nodes. When you add a new node it randomly chooses some partitions to take ownership of.
- This is really nice if you expect a lot of fluctuation in the number of nodes.
Automated vs Manual Rebalancing - We talked about systems that automatically rebalance, which is nice for systems that need to scale fast or have workloads that are homogenized.
- You might be able to do better if you are aware of the patterns of your data or want to control when these expensive operations happen.
- Some systems like Couchbase, Riak, and Voldemort will suggest partition assignment, but require an administrator to kick it off.
- But why? Imagine launching a large online video game and taking on tons of data into an empty system … there could be a lot of rebalancing going on at a terrible time. It would have been much better if you could have pre-provisioned ahead of time … but that doesn’t work with dynamic scaling!
Request Routing - One last thing … if we’re dynamically adding nodes and partitions, how does a client know who to talk to?
- This is an instance of a more general problem called “service discovery”.
- There are a couple ways to solve this:
- The nodes keep track of each other. A client can talk to any node and that node will route them anywhere else they need to go.
- Or a centralized routing service that the clients know about, and it knows about the partitions and nodes, and routes as necessary.
- Or require that clients be aware of the partitioning and node data.
- No matter which way you go, partitioning and node changes need to be applied. This is notoriously difficult to get right and REALLY bad to get wrong. (Imagine querying the wrong partitions …)
- Apache ZooKeeper is a common coordination service used for keeping track of partition/node mapping. Systems check in or out with ZooKeeper and ZooKeeper notifies the routing tier.
- Kafka (although not for much longer), Solr, HBase, and Druid all use ZooKeeper. MongoDb uses a custom ConfigServer that is similar.
- Cassandra and Riak use a “gossip protocol” that spreads the work out across the nodes.
- Elasticsearch has different roles that nodes can have, including data, ingestion and … you guessed it, routing.
Parallel Query Execution - So far we’ve mostly talked about simple queries, i.e. searching by key or by secondary index … the kinds of queries you would be running in NoSQL type situations.
- What about? Massively Parallel Processing (MPP) relational databases that are known for having complex join, filtering, aggregations?
- The query optimizer is responsible for breaking down these queries into stages which target primary/secondary indexes when possible and run these stages in parallel, effectively breaking down the query into subqueries which are then joined together.
- That’s a whole other topic, but based on the way we talked about primary/secondary indexes today you can hopefully have a better understanding of how the query optimizer does that work. It splits up the query you give it into distinct tasks, each of which could run across multiple partitions/nodes, runs them in parallel, and then aggregates the results.
- Designing Data-Intensive Applications goes into it in more depth in future chapters while discussing batch processing.
Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
Tip of the Week - PowerLevel10k is a Zsh “theme” that adds some really nice features and visual candy. It’s highly customizable and works great with Kubernetes and Git. (GitHub)
- If for some reason VS Code isn’t in your path, you can add it easily within VS Code. Open up the command palette (
CTRL+SHIFT+P / COMMAND+SHIFT+P) and search for “path”. Easy peasy! - Gently Down the Stream is a guidebook to Apache Kafka written and illustrated in the style of a children’s book. Really neat way to learn! (GentlyDownThe.Stream)
- PostgreSQL is one of the most powerful and versatile databases. Here is a list of really cool things you can do with it that you may not expect. (HakiBenita.com)
 Check out PowerLevel10k
Direct download: coding-blocks-episode-172.mp3
Category: Software Development
-- posted at: 9:10pm EDT
|
|
Sun, 7 November 2021
We crack open our favorite book again, Designing Data-Intensive Applications by Martin Kleppmann, while Joe sounds different, Michael comes to a sad realization, and Allen also engages “no take backs”. The full show notes for this episode are available at https://www.codingblocks.net/episode171. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says News - Thank you for the review!
Best book evar! The Whys and Hows of Partitioning Data - Partitioning is known by different names in different databases:
- Shard in MongoDB, ElasticSearch, SolrCloud,
- Region in HBase,
- Tablet in BigTable,
- vNode in Cassandra and Riak,
- vBucket in CouchBase.
- What are they?
- In contrast to the replication we discussed, partitioning is spreading the data out over multiple storage sections either because all the data won’t fit on a single storage mechanism or because you need faster read capabilities.
- Typically data records are stored on exactly one partition (record, row, document).
- Each partition is a mini database of its own.
Why partition? Scalability - Different partitions can be put on completely separate nodes.
- This means that large data sets can be spread across many disks, and queries can be distributed across many processors.
- Each node executes queries for its own partition.
- For more processing power, spread the data across more nodes.
- Examples of these are NoSQL databases and Hadoop data warehouses.
- These can be set up for either analytic or transactional workloads.
- While partitioning means that records belong to a single partition, those partitions can still be replicated to other nodes for fault tolerance.
- A single node may store more than one partition.
- Nodes can also be a leader for some partitions and a follower for others.
- They noted that the partitioning scheme is mostly independent of the replication used.
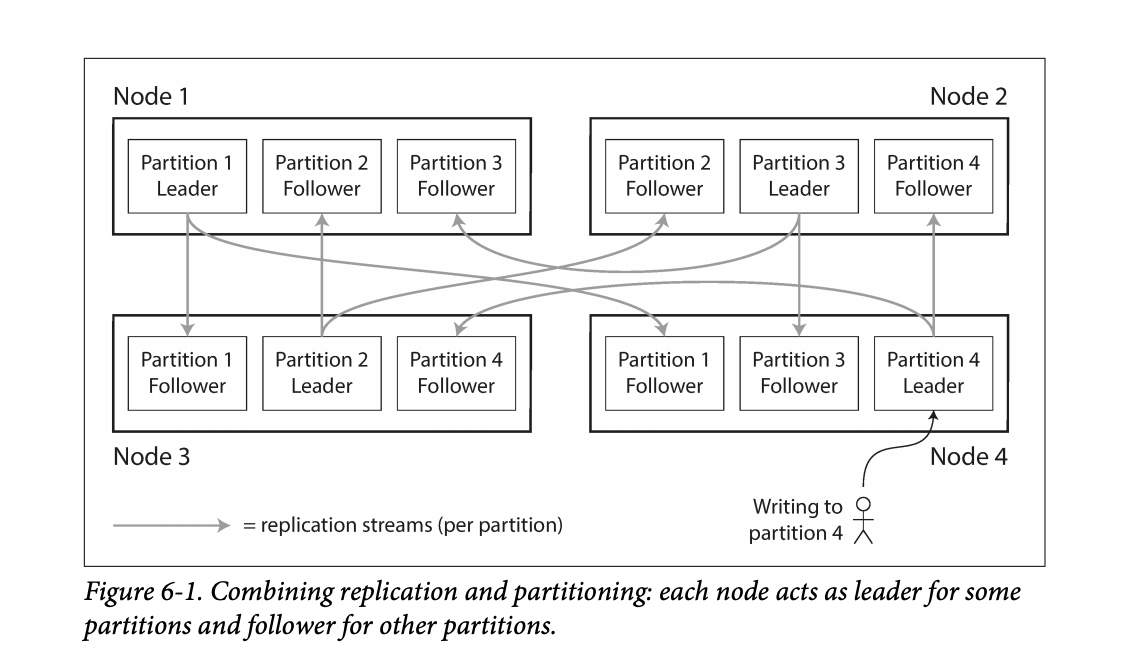 Figure 6-1 in the book shows this leader / follower scheme for partitioning among multiple nodes. Figure 6-1 in the book shows this leader / follower scheme for partitioning among multiple nodes. - The goal in partitioning is to try and spread the data around as evenly as possible.
- If data is unevenly spread, it is called skewed.
- Skewed partitioning is less effective as some nodes work harder while others are sitting more idle.
- Partitions with higher than normal loads are called hot spots.
- One way to avoid hot-spotting is putting data on random nodes.
- Problem with this is you won’t know where the data lives when running queries, so you have to query every node, which is not good.
Partitioning by Key Range - Assign a continuous range of keys on a particular partition.
- Just like old encyclopedias or even the rows of shelves in a library.
- By doing this type of partitioning, your database can know which node to query for a specific key.
- Partition boundaries can be determined manually or they can be determined by the database system.
- Automatic partition is done by BigTable, HBase, RethinkDB, and MongoDB.
- The partitions can keep the keys sorted which allow for fast lookups. Think back to the SSTables and LSM Trees.
- They used the example of using timestamps as the key for sensor data – ie
YY-MM-DD-HH-MM. - The problem with this is this can lead to hot-spotting on writes. All other nodes are sitting around doing nothing while the node with today’s partition is busy.
- One way they mentioned you could avoid this hot-spotting is maybe you prefix the timestamp with the name of the sensor, which could balance writing to different nodes.
- The downside to this is now if you wanted the data for all the sensors you’d have to issue separate range queries for each sensor to get that time range of data.
- Some databases attempt to mitigate the downsides of hot-spotting. For example, Elastic has the ability specify an index lifecycle that can move data around based on the key. Take the sensor example for instance, new data comes in but the data is rarely old. Depending on the query patterns it may make sense to move older data to slower machines to save money as time marches on. Elastic uses a temperature analogy allowing you to specify policies for data that is hot, warm, cold, or frozen.
Partitioning by Hash of the Key - To avoid the skew and hot-spot issues, many data stores use the key hashing for distributing the data.
- A good hashing function will take data and make it evenly distributed.
- Hashing algorithms for the sake of distribution do not need to be cryptographically strong.
- Mongo uses MD5.
- Cassandra uses Murmur3.
- Voldemort uses Fowler-Noll-Vo.
- Another interesting thing is not all programming languages have suitable hashing algorithms. Why? Because the hash will change for the same key. Java’s
object.hashCode() and Ruby’s Object#hash were called out. - Partition boundaries can be set evenly or done pseudo-randomly, aka consistent hashing.
- Consistent hashing doesn’t work well for databases.
- While the hashing of keys buys you good distribution, you lose the ability to do range queries on known nodes, so now those range queries are run against all nodes.
- Some databases don’t even allow range queries on the primary keys, such as Riak, Couchbase, and Voldemort.
- Cassandra actually does a combination of keying strategies.
- They use the first column of a compound key for hashing.
- The other columns in the compound key are used for sorting the data.
- This means you can’t do a range query over the first portion of a key, but if you specify a fixed key for the first column you can do a range query over the other columns in the compound key.
- An example usage would be storing all posts on social media by the user id as the hashing column and the updated date as the additional column in the compound key, then you can quickly retrieve all posts by the user using a single partition.
- Hashing is used to help prevent hot-spots but there are situations where they can still occur.
- Popular social media personality with millions of followers may cause unusual activity on a partition.
- Most systems cannot automatically handle that type of skew.
- In the case that something like this happens, it’s up to the application to try and “fix” the skew. One example provided in the book included appending a random 2 digit number to the key would spread that record out over 100 partitions.
- Again, this is great for spreading out the writes, but now your reads will have to issue queries to 100 different partitions.
- Couple examples:
- Sensor data: as new readings come in, users can view real-time data and pull reports of historical data,
- Multi-tenant / SAAS platforms,
- Giant e-commerce product catalog,
- Social media platform users, such as Twitter and Facebook.
 The first Google computer at Stanford was housed in custom-made enclosures constructed from Mega Blocks. (Wikipedia) The first Google computer at Stanford was housed in custom-made enclosures constructed from Mega Blocks. (Wikipedia) Resources We Like - Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- History of Google (Wikipedia)
Tip of the Week - VS Code lets you open the search results in an editor instead of the side bar, making it easier to share your results or further refine them with something like regular expressions.
- Apple Magic Keyboard (for iPad Pro 12.9-inch – 5th Generation) is on sale on Amazon. Normally $349, now $242.99 on Amazon and Best Buy usually matches Amazon.(Amazon)
- Compatible Devices:
- iPad Pro 12.9-inch (5th generation),
- iPad Pro 12.9-inch (4th generation),
- iPad Pro 12.9-inch (3rd generation)
- Room EQ Wizard is free software for room acoustic, loudspeaker, and audio device measurements. (RoomEQWizard.com)
Direct download: coding-blocks-episode-171.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 24 October 2021
The Mathemachicken strikes again for this year’s shopping spree, while Allen just realized he was under a rock, Joe engages “no take backs”, and Michael ups his decor game. The full show notes for this episode are available at https://www.codingblocks.net/episode170. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Thank you to everyone that left a review!
- iTunes: BoldAsLove88
- Audible: Tammy
Joe’s List
Allen’s List
Michael’s List
Resources We Like - Security Now 834, Life: Hanging By A Pin (Twit.tv)
- Buyer Beware: Crucial Swaps P2 SSD’s TLC NAND for Slower Chips (ExtremeTech.com)
- Samsung Is the Latest SSD Manufacturer Caught Cheating Its Customers (ExtremeTech.com)
Tip of the Week - VS Code … in the browser … just … there? Not all extensions work, but a lot do! (VSCode.dev)
- Skaffold is a tool you can use to build and maintain Kubernetes environments that we’ve mentioned on the show several times and guess what!? You can make your life even easier with Skaffold with environment variables. It’s another great way to maintain flexibility for your environments … both local and CI/CD. (Skaffold.dev)
- K9s is a Kubernetes terminal UI that makes it easy to quickly search, browse, filter, and edit your clusters and it also has skins! The Solarized Light theme is particularly awesome for customizing your experience, especially for presenting. (GitHub)
Direct download: coding-blocks-episode-170.mp3
Category: Software Development
-- posted at: 10:00pm EDT
|
|
Sun, 10 October 2021
We discuss the pros and cons of speaking at conferences and similar events, while Joe makes a verbal typo, Michael has turned over a new leaf, and Allen didn’t actually click the link. The full show notes for this episode are available at https://www.codingblocks.net/episode169. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News  The Kinesis Gaming Freestyle Edge RGB Split Mechanical Keyboard might be the current favorite. - Thank you to everyone that left a review!
- How long does it take to get the Moonlander? (ZSA.io)
- Is the Kinesis Gaming Freestyle the current favorite? (Amazon)
- Atlanta Code Camp was fantastic, see you again next year! (atlantacodecamp.com)
What kind of speaking are we talking about? - Conferences
- Meetups
- Does YouTube/Twitch count as tech presentations?
- There are some similarities! Streaming has the engagement, but generally isn’t as rehearsed. Published videos are closer to the format but you have to make some assumptions about your audience and can get creative with the editing.
Why do people speak? - Can help you build an audience
- Establish credibility
- Promotional opportunities
- Networking
- Free travel/conferences
- Great way to learn something
- Become a better communicator
- Is it fun?
Who speaks at conferences? - People speak at conferences for different reasons
- Couple different archetypes of speakers:
- Sponsored: the speakers are on the job, promoting their company and products
- Practitioners: Talks from people in the trenches, usually more technical and focused on specific results or challenges
- Idea people: People who have a strong belief in something that is controversial, may have an axe to grind or an idea that’s percolating into a product
- Professionals: Some companies encourage speakers to bolster the company reputation, promotions and job descriptions might require this
How do you put together a talk? - How do you pick a talk?
- Know who is selecting talks, go niche for larger conferences if you don’t have large credentials/backing
- Sometimes conferences will encourage “tracks” certain themes for topics
- What are some talks you like? What do they do differently?
- Do you aim for something you know, or want to know?
- How do you write your talks?
- How do you practice for a talk?
- Differences between digital and physical presentations?
- How long does it take you?
Where can you find places to speak? - Is this the right question? What does this tell you about your motivation?
- Meet new people who share your interests through online and in-person events. (Meetup)
- Find your next tech conference (Confs.Tech)
- Google for events in your area!
Final Questions - Is it worth the time and anxiety?
- What do you want out of talks?
- What are some alternatives?
- Blogging
- Videos
- Open Source
- Participating in communities
Resources - Is Speaking At A Conference Really Worth Your Time? (Cleverism.com)
- We’re 93% certain that Burke Holland gave a great talk about a dishwasher and Vue.js. (Twitter)
- Monitor you Netlify sites with Datadog (Datadog)
Netlify (docs.datadoghq.com)- Risk Astley – Never Gonna Give You Up (Official Music Video) (YouTube)
- Simple Minds – Don’t You (Forget About Me) (YouTube)
- Foo Fighters With Rick Astley – Never Gonna Give You Up – London O2 Arena 19 September 2017 (YouTube)
Tip of the Week - Next Meeting is a free app for macOS that keeps a status message up in the top right of your toolbar so you know when your next meeting is. It does other stuff too, like making it easier to join meetings and see your day’s events but … the status is enough to warrant the install. Thanks MadVikingGod! (Mac App Store)
- How do I disable “link preview” in iOS safari? (Stack Exchange)
- Here is your new favorite YouTube channel, Rick Beato is a music professional who makes great videos about the music you love, focusing on what makes the songs and artists special. (YouTube)
- Hot is a free app for macOS that shows you the temperate of your MacBook Pro … and the percentage of CPU you’re limited to because of the heat! Laptop feels slow? Maybe it’s too hot! (GitHub, XS-Labs)
- What is the meaning of $? in a shell script? (Stack Exchange)
- Did you know…You can install brew on Linux? That’s right, the popular macOS packaging software is available on your favorite distro. (docs.brew.sh, brew.sh)
Direct download: coding-blocks-episode-169.mp3
Category: Software Development
-- posted at: 10:00pm EDT
|
|
Sun, 26 September 2021
Joe goes full shock jock, but only for a moment. Allen loses the "Most Tips In A Single Episode: 2021" award, and Michael didn't get the the invite notification in this week's episode. The full show notes for this episode are available at https://www.codingblocks.net/episode168. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Shortcut - Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says Well...no survey this week, but this is where it would be! News This book has a whole chapter on transactions in distributed systems - Thank you to everyone that left a review!
- "Podchaser: alexi*********, Nicholas G Larsen, Kubernutties,
- iTunes: Kidboyadde, Metalgeeksteve, cametumbling, jstef16, Fr1ek
- Audible: Anonymous (we are like your mother - go clean your room and learn Docker)
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Maintaining data consistency - Each service should have its own data store
- What about transactions? microservices.io suggests the saga pattern (website)
- A sequence of local transactions must occur
- Order service saves to its data store, then sends a message that it is done
- Customer service attempts to save to its data store…if it succeeds, the transaction is done. If it fails, it sends a message stating so, and then the Order service would need to run another update to undo the previous action
- Sound complicated? It is…a bit, you can't rely on a standard 2 Phase Commit at the database level to ensure an atomic transaction
- Ways to achieve this - choreography or orchestration
Choreography Saga - The Order Service receives the POST /orders request and creates an Order in a PENDING state
- It then emits an Order Created event
- The Customer Service’s event handler attempts to reserve credit
- It then emits an event indicating the outcome
- The OrderService’s event handler either approves or rejects the Order - Each service's local transaction sends a domain event that triggers another service's local transaction
- To sum things up, each service knows where to listen for work it should do, and it knows where to publishes the results of it's work. It's up to the designers of the system to set things up such that the right things happened
- What's good about this approach?
"The code I wrote sux. The code I'm writing is cool. The code I'm going to write rocks!" Thanks for the paraphrase Mike! Orchestration Saga - The Order Service receives the POST /orders request and creates the Create Order saga orchestrator
- The saga orchestrator creates an Order in the PENDING state
- It then sends a Reserve Credit command to the Customer Service
- The Customer Service attempts to reserve credit
- It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the Order - There is an orchestrator object that tells each service what transaction to run
- The difference between Orchestration and Choreography is that the orchestration approach has a "brain" - an object that centralizes the logic and can make more advanced changes
- These patterns allow you to maintain data consistency across multiple services
- The programming is quite a bit more complicated - you have to write rollback / undo transactions - can't rely on ACID types of transactions we've come to rely on in databases
- Other issues to understand
- The service must update the local transaction AND publish the message / event
- The client that initiates the saga (asynchronously) needs to be able to determine the outcome
- The service sends back a response when the saga completes
- The service sends back a response when the order id is created and then polls for the status of the overall saga
- The service sends back a response when the order id is created and then submits an event via a webhook or similar when the saga completes
- When would you use Orchestration vs Choreography for transactions across Microservices?
- Friend of the show @swyx works for Temporal, a company that does microservice orchestration as a service, https://temporal.io/
Tips for writing Great Microservices Fantastic article on how to keep microservices loosely coupled
https://www.capitalone.com/tech/software-engineering/how-to-avoid-loose-coupled-microservices/ - Mentions using separate data storage / dbs per service
- Can't hide implementation from other services if they can see what's happening behind the scenes - leads to tight coupling
- Share as little code as possible
- Tempting to share things like customer objects, but doing so tightly couples the various microservices
- Better to nearly duplicate those objects in a NON-shared way - that way the services can change independently
- Avoid synchronous communication where possible
- This means relying on message brokers, polling, callbacks, etc
- Don't use shared test environments / appliances
- May not sound right, but sharing a service may lead to problems - like multiple services using the same test service could introduce performance problems
- Share as little domain data as possible - ie. important pieces of information shouldn't be passed around various services in domain objects. Only the bits of information necessary should be shared with each service - ie an order number or a customer number. Just enough to let the next microservice be able to do its job
Resources Tip of the Week - Podman is an open-source containerization tool from Red Hat that provides a drop in replacement for Docker (they even recommend aliasing it!). The major difference is in how it works underneath, spawning process directly rather than relying on resident daemons. Additionally, podman was designed in a post Kubernetes world, and it has some additional tooling that makes it easier to transition to Kubernetes- like being able to spawn pods and generate Kubernetes yaml files. Website
- Check out this episode from Google's Kubernetes podcast all about it: Podcast
- Unity is the most popular game engine and they have a ton of resources in their Learning Center. Including one that is focused on writing code. It walks you through writing 5 microgames with hands on exercises where you fix projects and ultimately design and write your own simple game. Also it's free! https://learn.unity.com/course/create-with-code
- Bonus: Make sure you subscribe to Jason Weimann's YouTube channel if you are interested in making games. Brilliant coder and communicator has a wide variety of videos: YouTube
- Educative.io has been a sponsor of the show before and we really like their approach to hands on teaching so Joe took a look to see if they had any resources on C++ since he was interested in possibly pursuing competitive programming. Not only do they have C++ courses, but they actually have a course specifically for Competitive Programming in C++. Great for devs who already know a programming language and are wanting to transition without having to start at step 1. Educative Course
- The most recent Coding Blocks Mailing List contest asked for "Summer Song" recommendations, we compiled them into a Spotify Summer Playlist. These are songs that remind you of summer, and don't worry we deduped the list so there is only one song from Rick Astley on there. Spotify
- Finally, one special recommendation for Coding Music. It's niche, for sure, but if you like coding to instrumental rock/hard-rock then you have to check out a 2018 album from a band called Night Verses. It's like Russian Circles had a baby with the Mercury Program. If you are familiar with either of those bands, or just want something different then make sure to check it out. Spotify
Direct download: coding-blocks-episode-168.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 12 September 2021
Some things just require discussion, such as Docker’s new licensing, while Joe is full of it, Allen *WILL* fault them, and Michael goes on the record. The full show notes for this episode are available at https://www.codingblocks.net/episode167. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Shortcut – Project management has never been easier. Check out how Shortcut (formerly known as Clubhouse) is project management without all the management.
Survey Says News - Thank you to everyone that left a review!
- iTunes: Badri Ravi
- Audible: Dysrhythmic, Brent
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Docker Announcement Docker recently announced big changes to the licensing terms and pricing for their product subscriptions. These changes would mean some companies having to pay a lot more to continue using Docker like they do today. So…what will will happen? Will Docker start raking in the dough or will companies abandon Docker? Resources - Docker is Updating and Extending Our Product Subscriptions (Docker)
- Minkube documentation (Thanks MadVikingGod! From the Tips n’ Tools channel in Slack.)
- Open Container Initiative, an open governance structure for the purpose of creating open industry standards around container formats and runtimes. (opencontainers.org)
- Podman, a daemonless container engine for developing, managing, and running OCI containers. (podman.io)
- Getting Started with K9s (YouTube)
How valuable is education? How do you decide when it’s time to go back to school or get a certification? What are the determining factors for making those decisions? Full-Stack Road Map What’s on your roadmap? We found a full-stack roadmap on dev.to and it’s got some interesting differences from other roadmaps we’ve seen or the roadmaps we’ve made. What are those differences? Resources - Full Stack Developer’s Roadmap (dev.to)
Bonus Tip: You can find the top dev.to articles for certain time periods like: https://dev.to/top/year. Works for week, month, and day, too. Where does your business logic go? Business logic should be in a service, not in a model … or should it? What’s the right way to do this? Is there a right way? Resources Are the M1/M1X chips a good idea for devs? Last year’s MacBook Pros introduced new M1 processors based on a RISC architecture. Now Apple is rolling out the rest of the line. What does this mean for devs? Is there a chance you will regret purchasing one of these laptops? Resources Tip of the Week - Hit
. (i.e. the period key) in GitHub to bring up an online VS Code editor while you are logged in. Thanks Morten Olsrud! (blog.yogeshchavan.dev) - Shoutout to Coder, cloud-powered development environments that feel local. (coder.com)
- The podcast that puts together the the “perfect album” for the topic du jour: The Perfect Album Side Podcast (iTunes, Spotify, Google Podcasts)
- Bon Jovi – Livin’ On A Prayer / Wanted Dead Or Alive (Los Angeles 1989) (YouTube)
- Docker’s
system prune command now includes a filter option to easily get rid of older docker resources. (docs.docker.com) - Example:
docker system prune --filter="until=72h" - The GitHub CLI makes it easy to create PR by autofilling information, as well as pushing your branch to origin:
- Apache jclouds is an open-source multi-cloud toolkit that abstracts the details of your cloud provider away so you can focus on your code and still support multiple providers. (jclouds.apache.org)
Direct download: coding-blocks-episode-167.mp3
Category: Software Development
-- posted at: 9:44pm EDT
|
|
Sun, 29 August 2021
We step away from our microservices deployments to meet around the water cooler and discuss the things on our minds, while Joe is playing Frogger IRL, Allen “Eeyores” his way to victory, and Michael has some words about his keyvoard, er, kryboard, leybaord, ugh, k-e-y-b-o-a-r-d! The full show notes for this episode are available at https://www.codingblocks.net/episode166. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Clubhouse – Project management has never been easier. Check out how Clubhouse (soon to be Shortcut) is project management without all the management.
Survey Says News - The threats worked and we got new reviews! Thank you to everyone that left a review:
- iTunes: ArcadeyGamey, Mc’Philly C. Steak, joby_h
- Audible: Jake Tucker
- Atlanta Code Camp is right around the corner on October 9th. Stop by the CB booth and say hi! (AtlantaCodeCamp.com)
Water Cooler Gossip > Office Memos - Are you interested in competitive programming?
- Michael gives a short term use review of his Moonlander.
- Spring makes Java better.
Resources We Like - CoRecursive episode 65: From Competitive Programming to APL With Conor Hoekstra (corecursive.com)
- Competitive Programming – A Complete Guide (GeeksForGeeks.org)
- Get started solving problems on Code Chef (CodeChef.com)
- Introduction to Dynamic Programming 1 (HackerEarth.com)
- Enhance your skills, expand your knowledge, and prepare for technical interviews with LeetCode. (LeetCode.com)
- Getting started with Competitive Programming – Build your algorithm skills (dev.to)
- ZSA Moonlander (zsa.io)
- Spring Framework Documentation (docs.spring.io)
- Spring Expression Language (SpEL) (docs.spring.io)
- RethinkDB, the open-source database for the realtime web. (RethinkDB.com)
Tip of the Week - Learn C the Hard Way: Practical Exercises on the Computational Subjects You Keep Avoiding (Like C) by Zed Shaw (Amazon)
- With Windows Terminal installed:
- In File Explorer, right click on or in a folder and select Open in Windows Terminal.
- Right click on the Windows Terminal icon to start a non-default shell.
- SonarLint is a free and open source IDE extension that identifies and helps you fix quality and security issues as you code. (SonarLint.org)
- Use
docker buildx to create custom builders. Just be sure to call docker buildx stop when you’re done with it. (Docker docs: docker buildx, docker buildx stop)
Direct download: coding-blocks-episode-166.mp3
Category: Software Development
-- posted at: 9:39pm EDT
|
|
Sun, 15 August 2021
We decide to dig into the details of what makes a microservice and do we really understand them as Joe tells us why we really want microservices, Allen incorrectly answers the survey, and Michael breaks down in real time. The full show notes for this episode are available at https://www.codingblocks.net/episode165. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - Want to know why we’re so hot on Skaffold? Check out this video from Joe: Getting Started with Skaffold (YouTube)
- Atlanta Code Camp is coming up October 9th, come hang out at the CB booth!
Want to know what’s up with Skaffold? We Thought We Knew About Microservices What are Microservices? - A collection of services that are…
- Highly maintainable and testable
- Loosely coupled (otherwise you just have a distributed monolith!)
- Independently deployable
- Organized around business capabilities (super important, Microservices are just as much about people organization as they are about code)
- Owned by a small team
- A couple from Jim Humelsine (Design Patterns Evangelist)
- Stateless
- Independently scalable (both in terms of tech, but also personnel)
- Note: we didn’t say anything about size but Sam Newman’s definition is: “Microservices are small, autonomous services that work together.”
- Semantic Diffusion (vague term getting vaguer)
- Enables frequent and reliable delivery of complex applications
- Allows you to evolve your tech stack (reminiscent of the strangler pattern)
- They are NOT a silver bullet – Many downsides
A Pattern Language - A collection of patterns for apply microservice patterns
- Example Microservice Implementation: https://microservices.io/patterns/microservices.html
- 3 micro-services in the example:
- Inventory service
- Account service
- Shipping service
- Each services talks to a separate backend database – i.e., inventory service talks to inventory DB, etc.
- Fronting those micro-services are a couple of API’s – a mobile gateway API and an API that serves a website
When an order is placed, a request is made to the mobile API to place the order, the mobile API has to make individual calls to each one of the individual micro-services to get / update information regarding the order - This setup is in contrast to a monolithic setup where you’d just have a single API that talks to all the backends and coordinates everything itself
Pros of the Microservice Architecture - Each service is small so it’s easier to understand and change
- Easier / faster to test as they’re smaller and less complex
- Better deployability – able to deploy each service independently of the others
- Easier to organize development effort around smaller, autonomous teams
- Because the code bases are smaller, the IDEs are actually better to work in
- Improved fault isolation – example they gave is a memory leak won’t impact ALL parts of the system like in a monolithic design
- Applications start and run faster when they are smaller
- Allows you to be more flexible with tech stacks – you can change out small pieces rather than entire systems if necessary
Cons of the Microservice Approach - Additional complexity of a distributed system
- Distributed debugging is hard! Requires additional tooling
- Additional cost (overhead of services, network traffic)
- Multi-system transactions are really hard
- Implementing inter-service communication and handling of failures
- Implementing multi-service requests is more complex
- Not only more complex, but you may be interfacing with multiple developer teams as well
- Testing interactions between services is more complex
- IDEs don’t really make distributed application development easier – more geared towards monolithic apps
- Deployments are more complex – managing multiple services, dependencies, etc.
- Increased infrastructure requirements – CPU, memory, etc.
- Distributed debugging is hard! Requires additional tooling
How to Know When to Choose the Microservice Architecture This is actually a hard problem. - Choosing this path can slow down development
- However, if you need to scale in the future, splitting apart / decomposing a monolith may be very difficult
Decomposing an Application into Microservices - Do so by business capability
- Example for e-commerce: Product catalog management, Inventory management, Order management, Delivery management
- How do you know the right way to break down the business capabilities?
- Organizational structure – customer service department, billing, shipping, etc
- Domain model – these usually map well from domain objects to business functions
- Which leads to decomposing by domain driven design
- Decompose by “verb” – ship order, place order, etc
- Decompose by “noun” – Account service, Order service, Billing service, etc
- Follow the Single Responsibility Principal – similar to software design
Questions About Microservices - Are Microservices a conspiracy?
- Isn’t this just SOA over again?
- How can you tell if you should have Microservices?
- Who uses Microservices?
- Netlifx
- Uber
- Amazon
- Lots of other big companies
- Who has abandoned Microservices?
- Lots of small companies…seeing a pattern here?
Resources We Like Tip of the Week - NeoVim is a fork of Vim 7 that aims to address some technical debt in vim in hopes of speeding up maintenance, plugin creation, and new features. It supports RPC now too, so you can write vim plugins in any language you want. It also has better support for background jobs and async tasks. Apparently the success of nvim has also led to some of the more popular features being brought into vim as well. Thanks Claus/@komoten! (neovim.io)
- Portable Apple Watch charger lets you charge your watch wirelessly from an outlet, or a usb. Super convenient! (Amazon)
- Free book from Linode explaining how to secure your Docker containers. Thanks Jamie! (Linode)
- There is a daily.dev plugin for Chrome that gives you the dev home page you deserve, delivering you dev news by default. Thanks @angryzoot! (Chrome Web Store)
- SonarQube is an open-source tool that you can run on your code to pull metrics on it’s quality. And it’s available for you to run in docker Thanks Derek Chasse! (hub.docker.com)
Direct download: coding-blocks-episode-165.mp3
Category: Software Development
-- posted at: 8:01pm EDT
|
|
Sun, 1 August 2021
We dive into JetBrains’ findings after they recently released their State of the Developer Ecosystem for 2021 while Michael has the open down pat, Joe wants the old open back, and Allen stopped using the command line. The full show notes for this episode are available at https://www.codingblocks.net/episode164. Stop by, check it out, and join the conversation. Sponsors - Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
Survey Says News - We really appreciate the latest reviews, so thank you!
- Allen has been making videos of some of our tips:
- Atlanta Code Camp is coming up October 9th, come hang out at the CB booth!
Check out Allen’s Quick Tips! Why JetBrains? JetBrains has given us free licenses to give out for years now. Sometimes people ask us what it is that we like about their products, especially when VS Code is such a great (and 100% free) experience…so we’ll tell ya! - JetBrains produces (among other things) a host of products that are all based on the same IDEA platform, but are custom tailored for certain kinds of development. CLion for C, Rider for C#, IntelliJ for JVM, WebStorm for front-end, etc. These IDEs support plugins but they come stocked with out-of-the-box functionality that you would have to add via plugins in a generalized Editor or IDE
- This also helps keep consistency amongst developers…everybody using the same tools for git, databases, formatting, etc
- Integrated experience vs General Purpose Tool w/ Plugins, Individual plugins allow for a lot of innovation and evolution, but they aren’t designed to work together in the same way that you get from an integrated experience.
- JetBrains has assembled a great community
- Supporting user groups, podcasts, and conferences for years with things like personal licenses
- Great learning materials for multiple languages (see the JetBrains Academy)
- Community (free) versions of popular products (Android Studio, IntelliJ, WebStorm, PyCharm)
- Advanced features that have taken many years of investment and iteration (Resharper/Refactoring tools)
- TL;DR JetBrains has been making great products for 20 years, and they are still excelling because those products are really good!
- Survey was comprised of 31,743 developers from 183 countries. JetBrains attempted to get a wide swath of diverse responses and they weighted the results in an attempt to get a realistic view of the world. Read more about the methodology
- What would you normally expect from JetBrain’s audience? (Compare to surveys from StackOverflow or Github or State of JS)
- JetBrains are mainly known for non-cheap, heavy duty tools so you might expect to see more senior or full time employees than StackOverlow, but that’s not the case…it skews younger
- Professional / Enterprise (63% full-time, 70.9% on latest Stack Overflow)
- JetBrains 3-5 vs StackOverflow 5-9 years of experience
- Education level is similar
- 71% of respondents develop for web backend!
- JavaScript is the most popular language
- Python is more popular than Java overall, but Java is more popular as a main language
- Top 5 languages devs are planning to adopt:
- Go
- Kotlin
- TypeScript
- Python
- Rust
- Top 5 Languages devs learning in 2021:
- Languages that fell:
- Top 5 Fastest Growing:
- Python
- TypeScript
- SQL
- Go
- Kotlin
- 71% of respondents develop for web backend
- Primary programming languages, so much JS!
- Developer OS:
- 61% Windows
- 47% linux
- 44% macOS
- What sources of information… Podcasts 31%! Glad to see this up there, of course
- 74% of the respondents use online ad-blocking tools
- Accounts: Github 84% Reddit…47%?
- Workplace and Events – pre covid comparisons
- Video Games are #1 hobby, last year was programming
- Used in last 12 Months, Primary…so much MySQL
- Really cool to see relative popularity by programming language
- How familiar are you with Docker?
- DevOps engineers are 2x more likely to be architects, 30% more likely to be leads
- Kubernetes: went from 16% to 29% to 40% to…40%. Is Kubernetes growth stalling?
- 90% of devs who use k8s have SSD, have above average RAM
- 53% of hosting is in the cloud? Still moving up, but there’s also a lot of growth with Hybrad
- AWS has a big lead in cloud services…GCP 2nd!? Let’s speculate how that happened, that’s not what we see in financial reports
- During development, where do you run and debug your code? (Come to Joe’s skaffold talk!)
- 35% of respondents develop microservices!!!!! Can this be right?
- Mostly senior devs are doing microservices
- GraphQL at 14%, coming up a little bit from last year
- How much RAM? (Want more RAM? Be DevOps, Architect, Data Analyst, leads)
- 79% of devs have SSD? Excellent!
- How old is your computer? Survey says….2 years? That’s really great.
- 75% say tests play an integral role, 44% involved. Not bad…but 44% not involved, huh?
- 67% Unit tests, yay!
Resources We Like Tip of the Week - The CoRecursive podcast has fantastic interviews with some really interesting people (corecursive.com) Thanks @msuriar. Some highlights:
- Free audiobook/album from the Software Daily host: Move Fast: How Facebook Builds Software (softwareengineeringdaily.com)
- Apple has great features and documentation on the different ways to take screenshots in macOS (support.apple.com)
- Data, Data, Data: Let the data guide your decisions. Not feelings.
- HTTPie is a utility built in Python that makes it really issue to issue web requests. CURL is great…but it’s not very user friendly. Give HTTPie a shot! (httpie.io)
Direct download: coding-blocks-episode-164.mp3
Category: Software Development
-- posted at: 9:33pm EDT
|
|
Sun, 18 July 2021
It’s time to take a break, stretch our legs, grab a drink, and maybe even join in some interesting conversations around the water cooler as Michael goes off script, Joe is very confused, and Allen insists that we stay on script. The full show notes for this episode are available at https://www.codingblocks.net/episode163. Stop by, check it out, and join the conversation. Sponsors - Educative.io – Learn in-demand tech skills with hands-on courses using live developer environments. Visit educative.io/codingblocks to get an additional 10% off an Educative Unlimited annual subscription.
Survey Says News - We really appreciate the latest reviews, so thank you!
- iTunes: EveryNickIsTaken2858, Memnoch97
- Allen finished his latest ergonomic keyboard review: Moonlander Ergonomic Keyboard Long Term Review (YouTube)
- Sadly, the
.http files tip from episode 161 for JetBrains IDEs is only application for JetBrains’ Ultimate version. Meantime, at the watercooler…. GitHub Copilot (GitHub) - In short, it’s a VS Code Extension that leverages the OpenAI Codex, a product that translates natural language to code, in order to … wait for it … write code. It’s currently in limited preview.
What’s the value? - Is the code correct? Github says ~40-50% in some large scale test cases
- It works best with small, documented functions
- Does having the code written for you steer you towards solutions?
- Could this encourage similar bugs/security holes across multiple languages by people importing the same code?
- Is this any different from developers using the same common solutions from StackOverflow?
- Could it become a crutch for new developers?
- Better for certain kinds of code? (Boiler plate, common accessors, date math)
- Boiler Plate (like angular / controller vars)
- Common APIs (Twitter, Goodreads)
- Common Algorithms, Design Patterns
- Less Familiar Languages
- But is it useful? We’ll see!
Is this the future? - We see more low, no, and now co-code solutions all the time, is this where things are going?
- This probably won’t be “it”, but maybe we will see things like this more commonly – in any case it’s different, why not give it a shot?
Is it Ethical? - The “AI” or whatever has been trained on “billions of lines” of open-source code…but not strictly permissive licenses. This means a dev using this tool runs the risk of accidently including proprietary code
- Quake Engine Source Code Example (GPLv2) (Twitter)
- From an article in VentureBeat:
- 54 million public software repositories hosted on GitHub as of May 2020 (for Python) 179GB of unique Python files under 1MB in size. Some basic limitations on line and file length, sanitization: The final training dataset totaled 159GB.
- There is problem with bias, especially in more niche categories
- Is it ethical to use somebody else’s data to train an AI without their permission?
- Can it get you sued?
- Would your thoughts change if the data is public? License restricted?
- Would your thoughts change if the product/model were open-sourced?
Abstractions… how far is too far? - Services should communicate with datastores and services via APIs that hide the details, these provide for a nice indirection that allows for easier maintenance in the future
- Do you abstract at the service level or the feature level?
- Are ORMs a foregone conclusion?
- What about services that have a unique communication pattern, or assist with cross cutting concerns for things like microservices (We are looking at you hear Kafka!)
The 10 Best Practices for Remote Software Engineering - From article: The 10 Best Practices for Remote Software Engineering (ACM)
- Work on Things You Care About
- Define Goals for Yourself
- Define Productivity for Yourself
- Establish Routine and Environment
- Take Responsibility for Your Work
- Take Responsibility for Human Connection
- Practice Empathetic Review
- Have Self-Compassion
- Learn to Say Yes, No, and Not Anymore
- Choose Correct Communication Channels
Some of Michael’s (Linux/macOS) favorites from the article: - Abbreviate your directories with tab completion when changing directories, such as
cd /v/l/a, and assuming that that abbreviated path can uniquely identify something like, /var/logs/apache, tab completion will take care of the rest. - Use
nl to get a numbered list of some previous command’s output, such as ls -l | nl. ERRATUM: During the episode, Michael mentioned that the output would first list the total lines, but that just happened to be due to output from ll and was unrelated to the output from nl. - On macOS, you can use the
powermetrics command to gain access to all sorts of metrics related to the internals of your computer, such as the temperature at various sensors. - Use
!! to repeat the last command. This can be especially helpful when you want to do something like prepend/append the previous command, such as sudo !!. ERRATUM: Wow, Michael really got this one wrong during the episode. It doesn’t repeat the “last sudo command” nor does it leave the command in edit mode. Listen to Allen’s description. /8) - Awesome keyboard shortcuts:
CTRL+A takes you to the start of the line and CTRL+E takes you to the end.- No need to type
clear any longer as CTRL+L will clear your screen. CTRL+U deletes the content to the left of the cursor and CTRL+K deletes the content to the right of the cursor.- Made a mistake in while typing your command? Use
CTRL+SHIFT+- to undo what you last typed. - Using the
history command, you can see your previous commands and even limit it with a negative number, such as history -5 to see only the last five commands. Tip of the Week - Partial Diff is a VS Code extension that makes it easy to compare text. You can right click to compare files or even blocks of text in the same file, as well as in different files. (Visual Studio Marketplace)
- StackBlitz is an online development environment for full stack applications. (StackBlitz.com)
- Microcks, an open source Kubernetes native tool for API mocking and testing. (Microcks.io)
- Bridging the HTTP protocol to Apache Kafka (Strimzi.io)
- Difference Between grep, sed, and awk (Baeldung.com)
- As an alternative to the ruler hack mentioned in episode 161, there are several compact, travel ready laptop stands. (Amazon)
Direct download: coding-blocks-episode-163.mp3
Category: Software Development
-- posted at: 10:16pm EDT
|
|
 The macro problem with microservices (Stack Overflow)
The macro problem with microservices (Stack Overflow)



































































