We decided to knock the dust off our copies of Designing Data-Intensive Applications to learn about transactions while Michael is full of solutions, Allen isn’t deterred by Cheater McCheaterton, and Joe realizes wurds iz hard.
Great statement from one of the creators of Google’s Spanner where the general idea is that it’s better to have transactions as an available feature even if it has performance issues and let developers decide if the performance is worth the tradeoff, rather than not having transactions and putting all that complexity on the developer.
Number of things that can go wrong during database interactions:
DB software or underlying hardware could fail during a write,
An application that uses the DB might crash in the middle of a series of operations,
Network problems could arise,
Multiple writes to the same records from multiple places causing race conditions,
Reads could happen to partially updated data which may not make sense, and/or
Race conditions between clients could cause weird problems.
“Reliable” systems can handle those situations and ensure they don’t cause catastrophic failures, but making a system “reliable” is a lot of work.
Transactions are what have been used for decades to address those issues.
A transaction is a way to group all related reads and writes into a single operation.
Either a transaction as a whole completes successfully as a “commit” or fails as an “abort, rollback”.
If the transaction fails, the application can choose what to do, like retry for example.
In general, transactions make error handling much simpler for an application.
That was their purpose, to make developing against a database much simpler.
Not all applications need transactions.
In some cases, it makes sense not to use transactions for performance and/or availability reasons.
How do you know if you need a transaction?
What are the safety guarantees?
What are the costs of using them?
Concepts of a transaction
Most relational DBs support transactions and some non-relational DBs support transactions.
The general idea of a transaction has been around mostly unchanged for over 40 years, originally introduced in IBM System R, the first relational database.
With the introduction of a lot of the NoSQL (non-relational) databases, transactions were left out.
In some NoSQL implementations, they redefined what a transaction meant with a weaker set of guarantees.
A popular belief was put out there that transactions meant anti-scalable.
Another popular belief was that to have a “serious” database, it had to have transactions.
The book calls out both as hyperbole.
The reality is there are tradeoffs for both having or not having transactions.
ACID is the acronym to describe the safety guarantees of databases and stands for Atomicity, Consistency, Isolation, and Durability.
Coined in 1983 by Theo Harder and Andreas Reuter.
The reality is that each database’s implementation of ACID may be very different.
Lots of ambiguity for what Isolation means.
Because ACID doesn’t specify the actual guarantees, it’s basically a marketing term.
Systems that don’t support ACID are often referred to as BASE, BAsically available, Soft state, and Eventual consistency.
Even more vague than ACID! BASE, more or less, just means anything but ACID.
Atomicity
Atomicity refers to something that can not be broken into smaller parts.
In terms of multi-threaded programming, this means you can only see the state of something before or after a complete operation and nothing in-between.
In the world of database and ACID, atomicity has nothing to do with concurrency. For instance, if multiple actions are trying to processes the same data, that’s covered under Isolation.
Instead, ACID describes what should happen if there is a fault while performing multiple related writes.
For example, if a group of related writes are to be performed in an operation and there is some underlying error that occurs before the transaction of writes can be committed, then the operation is aborted and any writes that occurred during that operation must be undone, i.e. rolled back.
Without atomicity, it is difficult to know what part of the operation completed and what failed.
The benefit of the rollback is you don’t have to have any special logic in your application to figure out how to get back to the original state. You can just simply try again because the transaction took care of the cleanup for you.
This ability to get rid of any writes after an abort is basically what the atomicity is all about.
Consistency
In ACID, consistency just means the database is in a good state.
But consistency is a property of the application as it’s what defines the invariants for its operations.
This means that you must write your application transactions properly to satisfy the invariants that have been defined.
The database can take care of certain invariants, such as foreign key constraints and uniqueness constraints, but otherwise it’s left up to the application to set up the transactions properly.
The book suggests that because the consistency is on the application’s shoulders, the C shouldn’t be part of ACID.
Isolation
Isolation is all about handling concurrency problems and race conditions.
The author provided an example of two clients trying to increment a single database counter concurrently, the value should have gone from 3 to 5, but only went to 4 because there was a race condition.
Isolation means that the transactions are isolated from each other so the previous example cannot happen.
The book doesn’t dive deep on various forms of isolation implementations here as they go deeper in later sections, however one that was brought up was treating every transaction as if it was a serial transaction. The problem with this is there is a rather severe performance hit for forcing everything serially.
The section that describes the additional isolation levels is “Weak Isolation Levels”.
Durability
Durability just means that once the database has committed a write, the data will not be forgotten, even if a database failure or hardware failure occurs.
This notion of durability typically means, in a single node database, that the data has been written to the drive, typically to a write-ahead log or similar implementation.
The write-ahead log ensures if there is any data corruption in the database, that it can be rebuilt, if necessary.
In a replicated database, durability means that the data has been written to the other nodes successfully.
The performance implication here is that for the database to guarantee that it’s durable, it must wait for those distributed writes to complete before committing the transaction.
PERFECT DURABILITY DOES NOT EXIST.
If all your databases and backups somehow got destroyed at the same time, there’s absolutely nothing you could do.
Longevity of Recordable CDs, DVDs and Blu-rays – Canadian Conservation Institute (CCI) Notes 19/1 (canada.ca)
Tip of the Week
The Bad Plus is an instrumental band that makes amazing music that’s perfect for programming. It’s a little wild, and a little strange. Maybe like Radiohead, but a saxophone instead of Thom Yorke? Maybe? (YouTube)
Correction, Piano Rock will quickly become your new favorite channel. (YouTube)
docker builder is a command prefix that you can use that specifically operates against the builder. For example you can prune the builder’s cache without wiping out your local cache. It can really save your bacon if you’re working with a lot of images. (docs.docker.com)
Ever want to convert YAML to JSON so you can see nesting issues easier? There’s a VSCode plugin for that! Search for hilleer.yaml-plus-json or find it on GitHub. (GitHub)
Spotify has a great interface, but Apple Audio has lossless audio, sounds great, and pays artists more. Give it a shot! If you sign up for Apple One you can get Apple Music, Apple TV+, Apple Arcade, Apple News+ and a lot more for one unified price. (Apple)
Michael spends the holidays changing his passwords, Joe forgot to cancel his subscriptions, and Allen’s busy playing Call of Duty: Modern Healthcare as we discuss the our 2023 resolutions.
You can pipe directly to Visual Studio Code (in bash anyway), much easier than outputting to a file and opening it in Code … especially if you end up accidentally checking it in!
Is your trackpad not responding on your new(-ish) MacBook? Run a piece of paper around the edge to clean out any gunk. Also maybe avoid dripping BBQ sauce on it.
How does the iOS MFA / Verification Code settings work? We want MFA, but we we’re tired of the runaround!
Jump around – nope, not Kris Kross, great tip from Thiyagarajan – keeps track of your most “frecent” directories to make navigation easier (GitHub)
There’s a version for PowerShell too – thank you Brad Knowles! (GitHub)
We take a few to step back and look at how things have changed since we first started the show while Outlaw is dancing on tables, Allen really knows his movie monsters, and Joe's math is on point.
We've wrapped up 9 years…how have we changed the most…why?
Bonus: Buying a window with 3 huge tvs (youtube.com)
Top 3 things you've gotten out of it …
Alphabetize all the things in your class
A better understanding of DB technologies and the impact of their underlying data structures
It's forced us to study various topics …
Amazing friends, community
The application tier can / should be your most powerful
Don't make your tech-du-jour a hammer
Tip of the Week
If you want to enable Markdown support, open a document in Google Docs, head over to the top of the screen, go to “Tools” then “Preferences” and enable “Automatically detect Markdown.” After that, you’re good to go..except this only works for the current doc. (techcrunch.com)
Markdown Viewer is also a plugin for Chrome that lets you support .md files in Google Drive (workspace.google.com)
DataGrip's useless "error at position" messages are frustrating, but the IDE actually does give you the info you need. Check your cursor!
Minikube's "profile" feature makes it easy to swap between clusters. No more tearing down and rebuilding if you need to switch to a new task! (minikube.sigs.k8s.io)
SQLforDevs.com has a free ebook: Next-Level Database Techniques for Developers. (sqlfordevs.com)
We talk about career management and interview tips, pushing data contracts "left", and our favorite dev books while Outlaw is [redacted], Joe's trying to figure out how to hire junior devs, and Allen's trying to screw some nails in.
Interesting article about AI potentially replacing recruiters at Amazon (vox.com)
From 'Round the Water-Cooler
Why don't companies want junior developers?
You see a lot of advice out there for developers to get that first job, but what advice does the industry have to trying to hire and support them? …not much
How long do you need to stay at a job?
What do you do if you're worried about being a "job hopper"?
Interviewing…know what the company is creating so you'll have an idea of what challenges they may have technically and so you can look up how you might solve some of those problems
How do you decide when to bring in new tech?
Right tool for the job - don't always be jumping ship to the newest, shiniest thing - it might be you just need to augment your stack with a new piece of technology rather than thinking something new will solve ALL your problems
Tip of the Week
Did you know Obsidian has a command palette similar to Code? Same short-cut (Cmd/Ctrl-P) as VS Code and it makes for a great learning curve! Don't know how to make something italic? Cmd-P. Insert a template? Cmd-P. Pretty much anything you want to do, but don't know how to do. Cmd P! (help.obsidian.md)
Ghostery plugin for Firefox cuts down on ads and protects your privacy. Thanks for the tip Aaron Jeskie! (addons.mozilla.org)
Amazing prank to play on Windows user, hit F-11 to full screen this website next time your co-worker or family member leaves their computer unlocked. Thanks Scott Harden! (fakeupdate.net)
We take a peak into some of the challenges Twitter has faced while solving data problems at large scale, while Michael challenges the audience, Joe speaks from experience, and Allen blindsides them both.
In 2019, over 100 million people per day would visit Twitter.
Every tweet and user action creates an event that is used by machine learning and employees for analytics.
Their goal was to democratize data analysis within Twitter to allow people with various skillsets to analyze and/or visualize the data.
At the time, various technologies were used for data analysis:
Scalding which required programmer knowledge, and
Presto and Vertica which had performance issues at scale.
Another problem was having data spread across multiple systems without a simple way to access it.
Moving pieces to Google Cloud Platform
The Google Cloud big data tools at play:
BigQuery, a cost-effective, serverless, multicloud enterprise data warehouse to power your data-driven innovation.
DataStudio, unifying data in one place with ability to explore, visualize and tell stories with the data.
History of Data Warehousing at Twitter
2011 – Data analysis was done with Vertica and Hadoop and data was ingested using Pig for MapReduce.
2012 – Replaced Pig with Scalding using Scala APIs that were geared towards creating complex pipelines that were easy to test. However, it was difficult for people with SQL skills to pick up.
2016 – Started using Presto to access Hadoop data using SQL and also used Spark for ad hoc data science and machine learning.
2018 …
Scalding for production pipelines,
Scalding and Spark for ad hoc data science and machine learning,
Vertica and Presto for ad hoc, interactive SQL analysis,
Druid for interactive, exploratory access to time-series metrics, and
Tableau, Zeppelin, and Pivot for data visualization.
So why the change? To simplify analytical tools for Twitter employees.
BigQuery for Everyone
Challenges:
Needed to develop an infrastructure to reliably ingest large amounts of data,
Support company-wide data management,
Implement access controls,
Ensure customer privacy, and
Build systems for:
Resource allocation,
Monitoring, and
Charge-back.
In 2018, they rolled out an alpha release.
The most frequently used tables were offered with personal data removed.
Over 250 users, from engineering, finance, and marketing used the alpha.
Sometime around June of 2019, they had a month where 8,000 queries were run that processed over 100 petabytes of data, not including scheduled reports.
The alpha turned out to be a large success so they moved forward with more using BigQuery.
They have a nice diagram that’s an overview of what their processes looked like at this time, where they essentially pushed data into GCS from on-premise Hadoop data clusters, and then used Airflow to move that into BigQuery, from which Data Studio pulled its data.
Ease of Use
BigQuery was easy to use because it didn’t require the installation of special tools and instead was easy to navigate via a web UI.
Users did need to become familiar with some GCP and BigQuery concepts such as projects, datasets, and tables.
They developed educational material for users which helped get people up and running with BigQuery and Data Studio.
In regards to loading data, they looked at various pieces …
Cloud Composer (managed Airflow) couldn’t be used due to Domain Restricted Sharing (data governance).
Google Data Transfer Service was not flexible enough for data pipelines with dependencies.
They ended up using Apache Airflow as they could customize it to their needs.
For data transformation, once data was in BigQuery, they created scheduled jobs to do simple SQL transforms.
For complex transformations, they planned to use Airflow or Cloud Composer with Cloud Dataflow.
Performance
BigQuery is not for low-latency, high-throughput queries, or for low-latency, time-series analytics.
It is for SQL queries that process large amounts of data.
Their requirements for their BigQuery usage was to return results within a minute.
To achieve these requirements, they allowed their internal customers to reserve minimum slots for their queries, where a slot is a unit of computational capacity to execute a query.
The engineering team had to analyze 800+ queries, each processing around 1TB of data, to figure out how to allocate the proper slots for production and other environments.
Data Governance
Twitter focused on discoverability, access control, security, and privacy.
For data discovery and management, they extended their DAL to work with both their on-premise and GCP data, providing a single API to query all sets of data.
In regards to controlling access to the data, they took advantage of two GCP features:
Domain restricted sharing, meaning only users inside Twitter could access the data, and
VPC service controls to prevent data exfiltration as well as only allow access from known IP ranges.
Authentication, Authorization, and Auditing
For authentication, they used GCP user accounts for ad hoc queries and service accounts for production queries.
For authorization, each dataset had an owner service account and a reader group.
For auditing, they exported BigQuery stackdriver logs with detailed execution information to BigQuery datasets for analysis.
Ensuring Proper Handling of Private Data
They required registering all BigQuery datasets,
Annotate private data,
Use proper retention, and
Scrub and remove data that was deleted by users.
Privacy Categories for Datasets
Highly sensitive datasets are available on an as-needed basis with least privilege.
These have individual reader groups that are actively monitored.
Medium sensitivity datasets are anonymized data sets with no PII (Personally identifiable information) and provide a good balance between privacy and utility, such as, how many users used a particular feature without knowing who the users were.
Low sensitivity datasets are datasets where all user level information is removed.
Public datasets are available to everyone within Twitter.
Scheduled tasks were used to register datasets with the DAL, as well as a number of additional things.
Cost
Roughly the same for querying Presto vs BigQuery.
There are additional costs associated with storing data in GCS and BigQuery.
Utilized flat-rate pricing so they didn’t have to figure out fluctuating costs of running ad hoc queries.
In some situations where querying 10’s of petabytes, it was more cost-effective to utilize Presto querying data in GCS storage.
Could you build Twitter in a weekend?
Resources
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Characters Sets (No Excuses!) (JoelOnSoftware.com)
Scaling data access by moving an exabyte of data to Google Cloud (blog.twitter.com)
Democratizing data analysis with Google BigQuery (blog.twitter.com)
Google BigQuery, Cloud data warehouse to power your data-driven innovation (cloud.google.com)
Elon Musk and Twitter employees engage in war of words (NewsBytesApp.com)
Tip of the Week
VS Code has a plugin for Kubernetes and it’s actually very nice! Particularly when you “attach” to the container. It installs a couple bits on the container, and you can treat it like a local computer. The only thing to watch for … it’s very easy to set your local context! (marketplace.visualstudio.com)
kafkactl is a great command line tool for managing Apache Kafka and has a consistent API that is intuitive to use. (deviceinsight.github.io)
Cruise Control is a tool for Apache Kafka that helps balance resource utilization, detect and alert on problems, and administrate. (GitHub)
iTerm2 is a terminal emulator for macOS that does amazing things. Why aren’t you already using it? (iterm2.com)
Message compression in Kafka will help you save a lot of space and network bandwidth, and the compression is per message so it’s easy to enable in existing systems! (cwiki.apache.org)
It’s that time of year where we’ve got money burning a hole in our pockets. That’s right, it’s time for the annual shopping spree. Meanwhile, Fiona Allen is being gross, Joe throws shade at Burger King, and Michael has a new character encoding method.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
Well, you know Joe has to be a little different so the format’s a bit different here! What if there was a way to spend money that could actually make you happy? Check out this article: Yes, you can buy happiness … if you spend it to save time (CNBC).
Ideas for ways to spend $2k to save you time
A good mattress will improve your sleep, and therefore your amount of quality time in a day! ($1k),
Cleaning Service ($100 – $300 per month),
Massage ($50 per month),
Car Wash Subscription ($20 per month),
Grocery Delivery Service (Shipt is $10 a month + up charges on items),
How do you fix a typo on your phone? Try pressing and then sliding your thumb on the space bar! It’s a nifty trick to keep you in the flow. And it works on both Android and iOS.
Heading off to holiday? Here’s an addendum to episode 191‘s Tip of the Week … Don’t forget your calendar!
On iOS, go to Settings -> Mail -> Accounts -> Select your work account -> Turn off the Mail and Calendar sliders.
Also, in Slack, you can pause notifications for an extended period and if you do, it’ll automatically change your status to Vacationing .
Did you know that Docker only has an image cache locally, there isn’t a local registry installed? This matters if you go to use something like microk8s instead of minikube! (microk8s.io)
What if you want to see what process has a file locked?
In Windows, Ronald Sahagun let us know you can use File Locksmith in PowerToys from Microsoft. (learn.microsoft.com)
In Linux based systems, Dave Follett points out you can just cat the process ID file in your /proc directory: cat /proc/<processId> to see what’s locked. LS Locks makes it easy too, just run the command and grep for your file. (Stack Exchange)
We gather around the watercooler to discuss the latest gossip and shenanigans have been called while Coach Allen is not wrong, Michael gets called out, and Joe gets it right the first time.
DuckDB is an in-process SQL OLAP database management system. You can use it from the command line, drop it into your POM file, pip install it, or npm install it, and then you can easily work with CSV or Parquet files as if they were a database. (duckdb.org)
It’s really easy to try out in the browser too! (shell.duckdb.org)
Want to be sure a file or URL is safe? Use Virus Total to find out. From VirusTotal: VirusTotal inspects items with over 70 antivirus scanners and URL/domain blocklisting services, in addition to a myriad of tools to extract signals from the studied content. (virustotal.com)
How to Show & Verify Code Signatures for Apps in Mac OS X (osxdaily.com)
tldr: codesign -dv --verbose=4 /path/to/some.app
How to Get GitHub-like Diff Support in Git on the Command-Line (matthewsetter.com)
Speed up development cycles when working in Kubernetes with Telepresence. (telepresence.io)
We wrap up Git from the Bottom Up by John Wiegley while Joe has a convenient excuse, Allen gets thrown under the bus, and Michael somehow made it worse.
Retool – Stop wrestling with UI libraries, hacking together data sources, and figuring out access controls, and instead start shipping apps that move your business forward.
News
Thanks for the reviews on iTunes jessetsilva, Marco Fernandooo, and sysadmike702!
Git’s reset is likely one of the commands that people shy away from using because it can mess with your working tree as well as what commit HEAD references.
reset is a reference editor, an index editor and a working tree editor.
git reset
Modifies HEAD?
Modifies the index?
Modifies the working tree?
--mixed
YES
YES. Removes all staged changes from the index, effectively unstaging them back to the working tree.
YES. All changes from the reset commit(s) are put in the working tree. Any previous changes are merged with the reset commit(s)’s changes in the working tree.
--soft
YES
YES. All changes from the reset commit(s) are put in the index. Any previously staged changes are merged with the reset commit(s)’s changes in the index.
NO. Any changes in the working tree are left untouched.
--hard
YES
YES. Clears the index of any staged changes.
YES. Clears the working tree of any unstaged changes.
What do the git reset mode flags change?
Mixed reset
--mixed is the default mode.
If you do a reset --mixed of more than one commit, all of those changes will be put back in the working tree together essentially setting you up for a squash of those commits.
Soft Reset
These two commands are equivalent, both effectively ignoring the last commit:
git reset --soft HEAD^
git update-ref HEAD HEAD^
If you did a git status after either of the previous commands, you’d see more changes because your working tree is now being compared to a different commit, assuming you previously had changes in your working tree.
This effectively allows you to create a new commit in place of the old one.
Instead of doing this, you can always do git commit --amend.
Similar to the use of --mixed for multiple commits, if you do a reset --soft of more than one commit, all of those changes will be put back in the index together essentially setting you up for a squash of those commits.
Hard Reset
This can be one of the most consequential commands.
Performing git reset --hard HEAD will get rid of any changes in your index and working tree to all tracked files, such that all of your files will match the contents of HEAD.
If you do a reset --hard to an earlier commit, such as git reset --hard HEAD~3, Git is removing changes from your working tree to match the state of the files from the earlier commit, and it’s changing HEAD to reference that earlier commit. Similar to the previous point, all uncommitted changes to tracked files are undone.
Again, this is a destructive/dangerous way to do something like this and there is another way that is safer:
Instead, perform a git stash followed by git checkout -b new-branch HEAD~3.
This will save, i.e. stash, your index and working tree changes, and then check out a new branch that references HEAD‘s great grandparent.
git stash saves your work in a stash that you can then apply to any branch you wish in the future; it is not branch specific.
Checking out a new branch to the older state allows you to maintain your previous branch and still make the changes you wanted on your new branch.
If you decide that you like what is in your new branch better than your old branch, you can run these commands:
git branch -D oldbranch
git branch -m newbranch oldbranch
After learning all of this, the author’s recommendation is to always do the stashing/branch creation as it’s safer and there’s basically no real overhead to it.
If you do accidentally blow away changes, the author mentions that you can do a restore from the reflog such as git reset --hard HEAD@{1}.
The author also recommends ALWAYS doing a git stash before doing a git reset --hard
This allows you to do a git stash apply and recover anything you lost, i.e. nice backup plan.
As mentioned previously, if you have other consumers of your branch/commits, you should be careful when making changes that modify history like this as it can force unexpected merges to happen to your consumers.
Stashing and the Reflog
There are two new ways that blobs can make their way into the repository.
The first is the reflog, a metadata repository that records everything you do in your repository.
So any time you make a commit in your repository, a commit is also being made to the reflog.
You can view the reflog with git reflog.
The glorious thing about the reflog is even if you did something like a git reset and blew away your changes, any changes previously committed would still exist in the reflog for at least 30 days, before being garbage collected (assuming you don’t manually run garbage collection).
This allows you to recover a commit that you deleted in your repository.
The other place that a blob can exist is in your working tree, albeit not directly noticeable.
If you modified foo.java but you didn’t add it to the index, you can still see what the hash would be by running git hash-object foo.java.
In this regard, the change exists on your filesystem instead of Git’s repository.
The author recommends stashing any changes at the end of the day even if you’re not ready to add anything to your index or commit it.
By doing so, Git will store all of your working tree changes and current index as the necessary trees and blobs in your git repository along with a couple of commits for storing the state of the working tree and index.
The next day, you come back in, run a git stash apply and all of your changes are back in your working tree.
So why do that? You’re just back in the same state you were the night before, yeah? Well, except now those commits that happened due to the stash are something you can go back to in your reflog, in case of an emergency!
Another special thing, because stashes are stored as commits, you can interact with them just like any other branch, at any time!
git checkout -b temp stash@{32}
In the above command, you can checkout a stash you did 32 days ago, assuming you were doing a single stash per day!
If you want to cleanup your stash history, DO NOT USE git stash clear as it kills all your stash history.
Instead, use git reflog expire --expire=30.days refs/stash to let your stashes expire.
One last tip the author mentioned is you could even roll your own snapshot type command by simply doing a git stash && git stash apply.
The Pragmatic Programmer – How to Build Pragmatic Teams (Episode 114)
Tip of the Week
A couple episodes back (episode 192), Allen mentioned Obsidian, a note taking app that operates on markdown files so you can use it offline if you want or you can keep the files in something like DropBox or pay a monthly fee for syncing. Good stuff, and if you ever want to leave the service … you have the markdown files! That’s an old tip, but Joe has been using it lately and wanted add a couple supplemental tips now that he’s gotten more experience with it.
If Obsidian just manages markdown files, then why bother? Why not just use something like VSCode? Because, Obsidian is also a rich client that is designed to help you manage markdown with features built in for things like search, tags, cross-linking etc.
Obsidian supports templates, so you can, for example, create a template for common activities … like if you keep a daily TODO list that has the same items on it every day, you can just {{include}} it to dump a copy of that checklist or whatever in. (help.obsidian.md)
Obsidian is designed to support multiple “vaults” up front. This lets you, for example, have one vault that you use for managing your personal life that you choose to sync to all of your devices, and one for work that is isolated in another location and doesn’t sync so you don’t have to worry about exfiltrating my work notes.
Community extensions! People have written interesting extensions, like a Calendar View or a Kanban board, but ultimately they serialize down to markdown files so if the extension (for example) doesn’t work on mobile then you can still somewhat function.
All of the files that Obsidian manages have to have a .md file extension. Joe wanted to store some .http files in his vault because it’s easy to associate them with his notes, but he also wanted to be able to execute them using the REST Client extension … which assumes a .http extension. The easiest solution Joe found was just to change the file type in the lower right hand corner in VSCode and it works great. This works for other extensions, too, of course! (GitHub)
[Wireless] How to improve compatibility of IoT device with ASUS WiFi 6(AX) Router? (ASUS)
Google’s new mesh Wi-Fi solution with support for Wi-Fi 6e is out, Google Nest Wifi Pro, and looks promising. (store.google.com)
Terran Antipodes sent Allen a tip that we had to share, saying that you can place your lower lip between your teeth to hold back a sneeze. No need to bite down or anything, it just works! All without the worry of an aneurysm.
This episode, we learn more about Git’s Index and compare it to other version control systems while Joe is throwing shade, Michael learns a new command, and Allen makes it gross.
Ludum Dare is a bi-annual game jam that’s been running for over 20 years now. Jam #51 is coming up September 30th to October 3rd. (ldjam.com)
We previously talked about Ludum Dare in episode 146.
The Index
Meet the Middle Man
The index refers to the set of blobs and trees created when running a git add, when you “stage” files.
These trees and blobs are not a part of the repository yet!
If you were to unstage the changes using a reset, you’d have an orphaned blob(s) that would eventually get cleaned up.
The index is a staging area for your next commit.
The staging area allows you to build up your next commit in stages.
You can almost ignore the index by doing a git commit -a (but shouldn’t).
In Subversion, the next set of changes is always determined by looking at the differences in the current working tree.
In Git, the next set of changes is determined by looking at your index and comparing that to the latest HEAD.
git add allows you to make additional changes before executing your commit with things like git add --patch and git add --interactive parameters.
For Emacs fans out there, the author mentioned gitsum. (GitHub)
Taking the Index Further
The author mentions “Quilt!”, is it this? (man7.org)
The primary difference between Git and Quilt is Git only allows one patch to be constructed at a time.
Situation the author describes is: What if I had multiple changes I wanted to test independently with each other?
There isn’t anything built into Git to allow you to try out parallel sets of changes on the fly.
Multiple branches would allow you to try out different combinations and the index allows you to stage your changes in a series of commits, but you can’t do both at the same time.
To do this you’d need an index that allows for more than a single commit at a time.
Stacked Git is a tool that lets you prepare more than one index at a time. (stacked-git.github.io)
The author gives an example of using regular Git to do two commits by interactively selecting a patch.
Then, the author gives the example of how you’d have to go about disabling one set of changes to test the other set of changes. It’s not great … swapping between branches, cherry-picking changes, etc.
If you find yourself in this situation, definitely take a look at Stacked Git. Using Stacked Git, you are basically pushing and popping commits on a stack.
Diffusion Bee is GUI for running Stable Diffusion on M1 macs. It’s got a one-click installer that you can get up and generating weird computer art in minutes … as long as you’re on a recent version of macOS and M1 hardware. (GitHub)
No M1 Mac? You can install the various packages you need to do it yourself, some assembly required! (assembly.ai)
Git Tower is a fresh take on Git UI that lets you drag-n-drop branches, undo changes, and manage conflicts. Give it a shot! (git-tower.com)
Git Kraken is the Gold Standard when it comes to Git UIs. It’s a rich, fully featured environment for managing all of your branches and changes. They are also the people behind the popular VS Code Extension GitLens (gitkraken.com)
GitHub CLI is an easy to use command line interface for interacting with GitHub. Reason 532 to love it … draft PR creation via gh pr create --draft ! (cli.github.com)
It’s time to understand the full power of Git’s rebase capabilities while Allen takes a call from Doc Brown, Michael is breaking stuff all day long, and Joe must be punished.
Ludum Dare is a bi-annual game jam that’s been running for over 20 years now. Jam #51 is coming up September 30th to October 3rd. (ldjam.com)
We previously talked about Ludum Dare in episode 146.
Branching and the power of rebase
Every branch you work in typically has one or more base commits, i.e. the commits the branch started from.
git branch shows the branches in your local repo.
git show-branch shows the branch ancestry in your local repo.
Reading the output from the bottom up takes you from oldest to newest history in the branches
Plus signs, are used to indicate commits on divergent branches from the one that’s currently checked out.
An asterisk, is used to indicate commits that happened on the current branch.
At the top of the output above the dashed line, the output shows the branches, the column and color that will identify their commits, and the label used when identifying their commits.
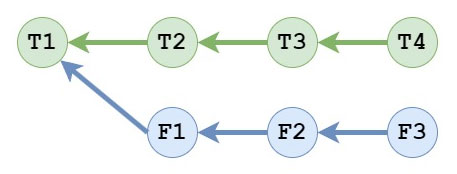
Consider an example repo where we have two branches, T and F, where T = Trunk and F = Feature and the commit history looks like this:
What we want to do is bring Feature up to date with what’s in Trunk, so bring T2, T3, and T4 into F3.
In most source control systems, your only option here is to merge, which you can also do in Git, and should be done if this is a published branch where we don’t want to change history.
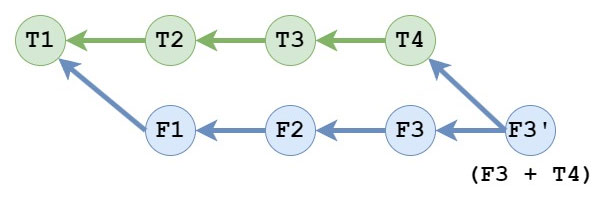
After a merge, the commit tree would look like this:
The F3' commit is essentially a “meta-commit” because it’s showing the work necessary to bring T4 and F3 together in the repository but contains no new changes from the working tree (assuming there were no merge conflicts to resolve, etc.)
If you would rather have your work in your Feature branch be directly based on the commits from Trunk rather than merge commits, you can do a git rebase, but you should only do this for local development.
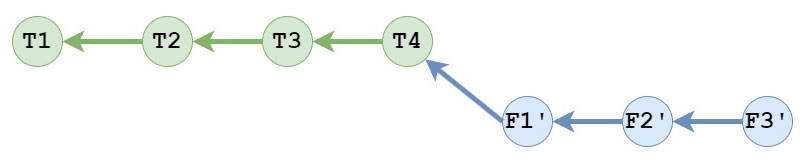
The resulting branch would look like this:
You should only rebase local branches because you’re potentially rewriting commits and you should not change public history.
When doing the merge, the merge commit, F3' is an instruction on how to transform F3 + T4.
When doing the rebase, the commits are being rewritten, such that F1' is based on T4 as if that’s how it was originally written by the author.
Use rebase for local branches that don’t have other branches off it, otherwise use merge for anything else.
Interactive rebasing
git rebase will try to automatically do all the merging.
git rebase -i will allow you to handle every aspect of the rebase process.
pick – This is the default behavior when not using -i. The commit should be applied to its rewritten parent. If there are conflicts, you’re allowed to resolve them before continuing.
squash – Use this option when you want to combine the contents of a commit into the previous commit rather than keeping the commits separate. This is useful for when you want multiple commits to be rewritten as a single commit.
edit – This will stop the rebasing process at that commit and let you make any changes before doing a git rebase --continue. This allows you to make changes in the middle of the process, making it look like the edit was always there.
drop – Use when you want to remove a commit from the history as if it had never been committed. You can also remove the commit from the list or comment it out from the rebase file to get the same results. If there were any commits later that depended on the dropped commit, you will get merge conflicts.
Interactive gives you the ability to reshape your branch to how you wish you’d done it in the first place, such as reordering commits.
Site Reliability Engineering – Embracing Risk (episode 182)
Tip of the Week
Russian Circles is a rock band that makes gloomy, mid-tempo, instrumental music that’s perfect for coding. They just put out a new album and, much like the others, it’s great for coding to! (YouTube)
GitLens for Visual Studio Code is an open-source extension for Visual Studio Code that brings in a lot more information from your Git repository into your editor. (marketplace.visualstudio.com)
JSON Crack is a website that makes it easy to “crack” JSON documents and view them hierarchically. Great for large docs. Thanks for the tip Thiyagu! (JsonCrack.com)
Handle is a Windows utility that you can use to see which process has a “handle” on your resource. Thanks for the tip Larry Weiss! (docs.microsoft.com)
Crunchy Data has made it so you can run PostgreSQL in the browser thanks to WASM. Technically very cool, and it’s a great way to learn Postgres. Thanks for the tip Mikerg! (Crunchy Data)
Divvy is a cool new window manager for macOS. It’s cool, modern, and much more powerful than the built in manager! Thanks for the tip jonasbn! (apps.apple.com)